 NEWSLETTER
NEWSLETTER
Purina US, una subsidiaria de Nestlé, tiene una larga trayectoria permitiendo a las personas adoptar mascotas más fácilmente a través de Buscador de mascotas, un mercado digital de más de 11.000 refugios de animales y grupos de rescate en EE. UU., Canadá y México. Como plataforma líder en adopción de mascotas, Petfinder ha ayudado a millones de mascotas a encontrar un hogar definitivo.
Purina busca constantemente formas de mejorar aún más la plataforma Petfinder tanto para los refugios como para los grupos de rescate y los adoptantes de mascotas. Un desafío al que se enfrentaron fue reflejar adecuadamente la raza específica de animales en adopción. Debido a que muchos animales del refugio son de razas mixtas, identificar razas y atributos correctamente en el perfil de la mascota requería un esfuerzo manual, lo que consumía mucho tiempo. Purina utilizó inteligencia artificial (IA) y aprendizaje automático (ML) para automatizar la detección de razas animales a escala.
Esta publicación detalla cómo Purina utilizó etiquetas personalizadas de Amazon Rekognition, funciones de pasos de AWS y otros servicios de AWS para crear un modelo de aprendizaje automático que detecta la raza de la mascota a partir de una imagen cargada y luego usa la predicción para completar automáticamente los atributos de la mascota. La solución se centra en los principios fundamentales del desarrollo de un flujo de trabajo de aplicaciones de IA/ML de preparación de datos, entrenamiento de modelos, evaluación de modelos y monitoreo de modelos.
Descripción general de la solución
Para predecir razas de animales a partir de una imagen se necesitan modelos de aprendizaje automático personalizados. Desarrollar un modelo personalizado para analizar imágenes es una tarea importante que requiere tiempo, experiencia y recursos, y que a menudo lleva meses en completarse. Además, a menudo se requieren miles o decenas de miles de imágenes etiquetadas a mano para proporcionar al modelo datos suficientes para tomar decisiones con precisión. Configurar un flujo de trabajo para auditar o revisar las predicciones del modelo para validar el cumplimiento de sus requisitos puede aumentar aún más la complejidad general.
Con las etiquetas personalizadas de Rekognition, que se basan en las capacidades existentes de Amazon Rekognition, puede identificar los objetos y escenas en imágenes que son específicas para sus necesidades comerciales. Ya está entrenado en decenas de millones de imágenes en muchas categorías. En lugar de miles de imágenes, puede cargar un pequeño conjunto de imágenes de entrenamiento (normalmente unos cientos de imágenes o menos por categoría) que sean específicas para su caso de uso.
La solución utiliza los siguientes servicios:
- Amazon API Gateway es un servicio totalmente administrado que facilita a los desarrolladores publicar, mantener, monitorear y proteger API a cualquier escala.
- El AWS Cloud Development Kit (AWS CDK) es un marco de desarrollo de software de código abierto para definir la infraestructura de la nube como código con lenguajes de programación modernos e implementarla a través de AWS CloudFormation.
- AWS CodeBuild es un servicio de integración continua en la nube totalmente administrado. CodeBuild compila código fuente, ejecuta pruebas y produce paquetes que están listos para implementar.
- Amazon DynamoDB es un servicio de base de datos no relacional rápido y flexible para cualquier escala.
- AWS Lambda es un servicio informático basado en eventos que le permite ejecutar código para prácticamente cualquier tipo de aplicación o servicio backend sin aprovisionar ni administrar servidores.
- Amazon Rekognition ofrece capacidades de visión por computadora (CV) personalizables y previamente capacitadas para extraer información y conocimientos de sus imágenes y videos. Con las etiquetas personalizadas de Amazon Rekognition, puede identificar los objetos y escenas en imágenes que son específicas para sus necesidades comerciales.
- AWS Step Functions es un servicio totalmente administrado que facilita la coordinación de los componentes de aplicaciones distribuidas y microservicios mediante flujos de trabajo visuales.
- AWS Systems Manager es una solución segura de administración de un extremo a otro para recursos en AWS y en entornos híbridos y multinube. Parameter Store, una capacidad de Systems Manager, proporciona almacenamiento jerárquico seguro para la gestión de datos de configuración y la gestión de secretos.
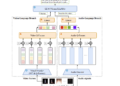
La solución de Purina se implementa como un punto final HTTP API Gateway, que enruta las solicitudes para obtener atributos de mascotas. Utiliza etiquetas personalizadas de Rekognition para predecir la raza de la mascota. El modelo ML se entrena a partir de perfiles de mascotas extraídos de la base de datos de Purina, asumiendo que la etiqueta de raza principal es la etiqueta verdadera. DynamoDB se utiliza para almacenar los atributos de la mascota. Lambda se utiliza para procesar la solicitud de atributos de mascota mediante la coordinación entre API Gateway, Amazon Rekognition y DynamoDB.
La arquitectura se implementa de la siguiente manera:
- La aplicación Petfinder enruta la solicitud para obtener los atributos de la mascota a través de API Gateway.
- API Gateway llama a la función Lambda para obtener los atributos de la mascota.
- La función Lambda llama al punto final de inferencia de etiqueta personalizada de Rekognition para predecir la raza de la mascota.
- La función Lambda utiliza la información de raza de mascota prevista para realizar una búsqueda de atributos de mascota en la tabla de DynamoDB. Recopila los atributos de la mascota y los envía de vuelta a la aplicación Petfinder.
El siguiente diagrama ilustra el flujo de trabajo de la solución.
El equipo de Petfinder en Purina quiere una solución automatizada que puedan implementar con un mantenimiento mínimo. Para lograr esto, utilizamos Step Functions para crear una máquina de estado que entrena los modelos con los datos más recientes, verifica su rendimiento en un conjunto de puntos de referencia y vuelve a implementar los modelos si han mejorado. El reentrenamiento del modelo se activa a partir de la cantidad de correcciones de raza realizadas por los usuarios que envían información de perfil.
Entrenamiento modelo
Desarrollar un modelo personalizado para analizar imágenes es una tarea importante que requiere tiempo, experiencia y recursos. Además, a menudo se requieren miles o decenas de miles de imágenes etiquetadas a mano para proporcionar al modelo datos suficientes para tomar decisiones con precisión. Generar estos datos puede tardar meses en recopilarse y requiere un gran esfuerzo para etiquetarlos para su uso en el aprendizaje automático. una técnica llamada transferir aprendizaje ayuda a producir modelos de mayor calidad al tomar prestados los parámetros de un modelo previamente entrenado y permite entrenar modelos con menos imágenes.
Nuestro desafío es que nuestros datos no están perfectamente etiquetados: los humanos que ingresan los datos del perfil pueden cometer errores, y de hecho lo hacen. Sin embargo, descubrimos que para muestras de datos suficientemente grandes, las imágenes mal etiquetadas representaban una fracción suficientemente pequeña y el rendimiento del modelo no se vio afectado en más del 2% en precisión.
Flujo de trabajo de ML y máquina de estados
La máquina de estado de Step Functions está desarrollada para ayudar en el reentrenamiento automático del modelo de Amazon Rekognition. Los comentarios se recopilan durante la entrada del perfil: cada vez que el usuario modifica una raza que se ha inferido a partir de una imagen a una raza diferente, se registra la corrección. Esta máquina de estados se activa a partir de un número umbral configurable de correcciones y datos adicionales.
La máquina de estados sigue varios pasos para crear una solución:
- Cree archivos de manifiesto de entrenamiento y prueba que contengan la lista de rutas de imágenes de Amazon Simple Storage Service (Amazon S3) y sus etiquetas para que las utilice Amazon Rekognition.
- Cree un conjunto de datos de Amazon Rekognition utilizando los archivos de manifiesto.
- Entrene una versión del modelo de Amazon Rekognition después de crear el conjunto de datos.
- Inicie la versión del modelo cuando se complete el entrenamiento.
- Evaluar el modelo y producir métricas de desempeño.
- Si las métricas de rendimiento son satisfactorias, actualice la versión del modelo en Parameter Store.
- Espere a que la nueva versión del modelo se propague en las funciones Lambda (20 minutos) y luego detenga el modelo anterior.
Evaluación del modelo
Usamos un conjunto aleatorio del 20% tomado de nuestra muestra de datos para validar nuestro modelo. Debido a que las razas que detectamos son configurables, no utilizamos un conjunto de datos fijo para la validación durante el entrenamiento, pero sí utilizamos un conjunto de evaluación etiquetado manualmente para las pruebas de integración. La superposición del conjunto etiquetado manualmente y las razas detectables del modelo se utiliza para calcular las métricas. Si la precisión de detección de raza del modelo está por encima de un umbral específico, promocionamos el modelo para que se utilice en el punto final.
Las siguientes son algunas capturas de pantalla del flujo de trabajo de predicción de mascotas de Rekognition Custom Labels.


Implementación con AWS CDK
La máquina de estado de Step Functions y la infraestructura asociada (incluidas las funciones de Lambda, los proyectos de CodeBuild y los parámetros de Systems Manager) se implementan con AWS CDK mediante Python. El código AWS CDK sintetiza una plantilla de CloudFormation, que utiliza para implementar toda la infraestructura de la solución.
Integración con la aplicación Petfinder
La aplicación Petfinder accede al punto final de clasificación de imágenes a través del punto final API Gateway mediante una solicitud POST que contiene una carga útil JSON con campos para la ruta de Amazon S3 a la imagen y la cantidad de resultados que se devolverán.
KPI que se verán afectados
Para justificar el costo adicional de ejecutar el punto final de inferencia de imágenes, realizamos experimentos para determinar el valor que el punto final agrega para Petfinder. El uso del endpoint ofrece dos tipos principales de mejora:
- Esfuerzo reducido para los refugios para mascotas que crean los perfiles de mascotas.
- Perfiles de mascotas más completos, que se espera que mejoren la relevancia de la búsqueda
Las métricas para medir el esfuerzo y la integridad del perfil incluyen la cantidad de campos autocompletados que se corrigen, la cantidad total de campos completados y el tiempo para cargar un perfil de mascota. Las mejoras en la relevancia de la búsqueda se infieren indirectamente a partir de la medición de indicadores clave de rendimiento relacionados con las tasas de adopción. Según Purina, después de que la solución se puso en funcionamiento, el tiempo promedio para crear un perfil de mascota en la aplicación Petfinder se redujo de 7 minutos a 4 minutos. Esto supone una gran mejora y un ahorro de tiempo porque en 2022 se cargaron 4 millones de perfiles de mascotas.
Seguridad
Los datos que fluyen a través del diagrama de arquitectura se cifran en tránsito y en reposo, de acuerdo con las mejores prácticas de AWS Well-Architected. Durante todas las interacciones con AWS, un experto en seguridad revisa la solución para garantizar que se proporcione una implementación segura.
Conclusión
Con su solución basada en etiquetas personalizadas de Rekognition, el equipo de Petfinder puede acelerar la creación de perfiles de mascotas para refugios de mascotas, reduciendo la carga administrativa para el personal del refugio. La implementación basada en AWS CDK implementa un flujo de trabajo de Step Functions para automatizar el proceso de capacitación e implementación. Para comenzar a utilizar las etiquetas personalizadas de Rekognition, consulte Introducción a las etiquetas personalizadas de Amazon Rekognition. También puede consultar algunos ejemplos de Step Functions y comenzar con AWS CDK.
Sobre los autores
 Mason Cahill es consultor sénior de DevOps en AWS Professional Services. Le gusta ayudar a las organizaciones a alcanzar sus objetivos comerciales y le apasiona crear y ofrecer soluciones automatizadas en la nube de AWS. Fuera del trabajo, le encanta pasar tiempo con su familia, hacer senderismo y jugar fútbol.
Mason Cahill es consultor sénior de DevOps en AWS Professional Services. Le gusta ayudar a las organizaciones a alcanzar sus objetivos comerciales y le apasiona crear y ofrecer soluciones automatizadas en la nube de AWS. Fuera del trabajo, le encanta pasar tiempo con su familia, hacer senderismo y jugar fútbol.
 Mateo Chasse es consultor de ciencia de datos en Amazon Web Services, donde ayuda a los clientes a crear soluciones escalables de aprendizaje automático. Matthew tiene un doctorado en Matemáticas y disfruta de la escalada en roca y la música en su tiempo libre.
Mateo Chasse es consultor de ciencia de datos en Amazon Web Services, donde ayuda a los clientes a crear soluciones escalables de aprendizaje automático. Matthew tiene un doctorado en Matemáticas y disfruta de la escalada en roca y la música en su tiempo libre.
 Rushikesh Jagtap es un arquitecto de soluciones con más de 5 años de experiencia en servicios de AWS Analytics. Le apasiona ayudar a los clientes a crear soluciones de análisis de datos modernas y escalables para obtener información valiosa a partir de los datos. Fuera del trabajo, le encanta ver Fórmula 1, jugar al bádminton y correr Go Karts.
Rushikesh Jagtap es un arquitecto de soluciones con más de 5 años de experiencia en servicios de AWS Analytics. Le apasiona ayudar a los clientes a crear soluciones de análisis de datos modernas y escalables para obtener información valiosa a partir de los datos. Fuera del trabajo, le encanta ver Fórmula 1, jugar al bádminton y correr Go Karts.
 Tayo Olajide es un experimentado generalista en ingeniería de datos en la nube con más de una década de experiencia en la arquitectura e implementación de soluciones de datos en entornos de nube. Con una pasión por transformar datos sin procesar en conocimientos valiosos, Tayo ha desempeñado un papel fundamental en el diseño y optimización de canales de datos para diversas industrias, incluidas las finanzas, la atención médica y la industria automotriz. Como líder intelectual en el campo, Tayo cree que el poder de los datos radica en su capacidad para impulsar la toma de decisiones informadas y está comprometido a ayudar a las empresas a aprovechar todo el potencial de sus datos en la era de la nube. Cuando no está creando canales de datos, puedes encontrar a Tayo explorando las últimas tendencias en tecnología, haciendo caminatas al aire libre o jugando con dispositivos y software.
Tayo Olajide es un experimentado generalista en ingeniería de datos en la nube con más de una década de experiencia en la arquitectura e implementación de soluciones de datos en entornos de nube. Con una pasión por transformar datos sin procesar en conocimientos valiosos, Tayo ha desempeñado un papel fundamental en el diseño y optimización de canales de datos para diversas industrias, incluidas las finanzas, la atención médica y la industria automotriz. Como líder intelectual en el campo, Tayo cree que el poder de los datos radica en su capacidad para impulsar la toma de decisiones informadas y está comprometido a ayudar a las empresas a aprovechar todo el potencial de sus datos en la era de la nube. Cuando no está creando canales de datos, puedes encontrar a Tayo explorando las últimas tendencias en tecnología, haciendo caminatas al aire libre o jugando con dispositivos y software.





{kind=link}