 NEWSLETTER
NEWSLETTER
The widespread use of large-scale language models (LLMs) in security-critical areas has raised a crucial challenge: how to ensure their compliance with clear security and ethical guidelines. Existing alignment techniques, such as supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), have limitations. Models can still produce harmful content when manipulated, reject legitimate requests, or have difficulty handling unknown scenarios. These issues often arise from the implicit nature of current security training, where models infer standards indirectly from data rather than learning them explicitly. Additionally, models generally lack the ability to deliberate on complex cues, limiting their effectiveness in nuanced or conflictual situations.
OpenAI researchers have presented Deliberative alignmenta new approach that directly teaches models security specifications and trains them to reason about these guidelines before generating responses. By integrating security principles into the reasoning process, this method addresses key weaknesses in traditional alignment techniques. Deliberative alignment focuses on teaching models to explicitly consider relevant policies, allowing them to handle complex scenarios more reliably. Unlike approaches that rely heavily on human-annotated data, this method uses model-generated data and chain-of-thought (CoT) reasoning to achieve better security results. When applied to series or OpenAI models, it has demonstrated greater resistance to jailbreak attacks, fewer rejections of valid requests, and better generalization to unknown situations.
Technical details and benefits
Deliberative Alignment involves a two-stage training process. First, supervised fine tuning (SFT) trains models to reference and reason through security specifications using data sets generated from base models. This step helps incorporate a clear understanding of security principles. In the second stage, reinforcement learning (RL) refines the model's reasoning using a reward model to evaluate performance against safety benchmarks. This training process does not rely on human-annotated completions, reducing the resource demands typically associated with security training. By leveraging synthetic data and CoT reasoning, Deliberative Alignment equips models to address complex ethical scenarios with greater accuracy and efficiency.
Results and insights
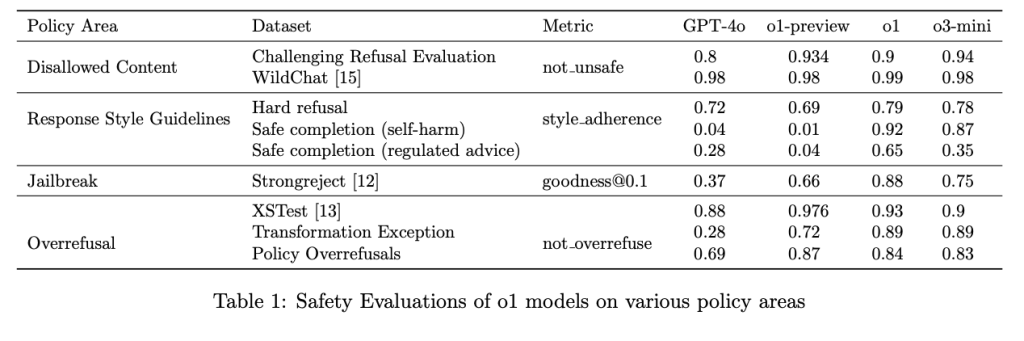
Deliberative Alignment has produced notable improvements in the performance of the series or OpenAI models. The o1 model, for example, outperformed other leading models in resistance to jailbreak prompts, achieving a score of 0.88 on the StrongREJECT benchmark compared to 0.37 for GPT-4o. It also performed well in avoiding unnecessary rejections, with a 93% accuracy rate on benign indications in the XSTest dataset. The method further improved compliance with style guidelines in responses to regulated advice and self-harm prompts. Ablation studies have shown that both the SFT and RL stages are essential to achieve these results. Furthermore, the approach has demonstrated strong generalization to out-of-distribution scenarios such as multilingual and coded prompts, highlighting its robustness.
Conclusion
Deliberative alignment represents a significant advance in aligning language models with security principles. By teaching models to reason explicitly about security policies, it offers a scalable and interpretable solution to complex ethical challenges. The success of the o1 series models illustrates the potential of this approach to improve safety and reliability in ai systems. As ai capabilities continue to evolve, methods like Deliberative Alignment will play a crucial role in ensuring these systems remain aligned with human values and expectations.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}