 NEWSLETTER
NEWSLETTER
Large language models (LLMs) are entering the clinical and medical fields as they grow in capability and versatility. These models have a number of benefits, including the ability to complement or even replace the work typically performed by physicians. This includes providing medical information, keeping track of patient information, and conducting patient consultations.
In the medical profession, one of the main advantages of LLMs is their ability to produce extensive texts, which is necessary to provide comprehensive answers to patient queries. Answers that are accurate and instructive are essential, especially in medical situations where providing false information can have detrimental effects. For example, when a patient asks about the origin of white tongue, the LLM must answer truthfully about possible causes, including bacterial buildup, without spreading myths, such as the idea that the condition is invariably dangerous and irreversible.
(Featured Article) LLMWare.ai Selected for GitHub 2024 Accelerator: Enabling the Next Wave of Innovation in Enterprise RAG with Small, Specialized Language Models
In the medical area there are numerous scenarios in which it is necessary to produce comprehensive and expanded responses. This is particularly crucial when answering patient queries, as the details provided must be true and objective. To ensure the accuracy and consistency of these responses, an automated process is required to evaluate claims made by LLMs.
To further explore this, in a recent study, a team of researchers produced MedLFQA, a specialized reference dataset derived from pre-existing long-form question and answer datasets in the biomedical area. The goal of MedLFQA is to facilitate the automatic assessment of the objective accuracy of responses produced by LLMs. This data set helps determine the accuracy and reliability of the facts offered in these long responses.
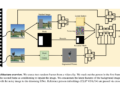
The team has offered a unique framework called OLAPH (Optimizing the Responses of Large Language Models with Preferences to Reduce Hallucinations). OLAPH uses a series of automated assessments to improve the factual accuracy of LLMs. The methodology uses an iterative training process to teach the LLM to favor responses with the highest factual and evaluation metrics scores.
For each question, the OLAPH framework generates several sample responses. Then, using predetermined evaluation criteria, the answer with the highest score is chosen. The LLM then receives further training using this preferred response, moving its subsequent responses closer to the correct and preferred responses. Otherwise, the model would produce false information, but this iterative approach helps limit the problem of hallucinations.
Results have shown considerable improvements in the factual accuracy of LLMs trained with the OLAPH framework, even when compared to measures not expressly included in the training procedure. A 7 billion parameter LLM trained with OLAPH produced extensive responses on par with professional medical responses in terms of quality.
The team has summarized its main contributions as follows.
- The team has published MedLFQA, a reorganized reference dataset for automated evaluation of long text generation produced by LLM in the biomedical field.
- To evaluate the veracity of medical claims provided in long responses, the team has developed two distinct statements that provide a complete picture of LLMs' ability to produce accurate data.
- The OLAPH framework has been introduced, which improves LLM responses through iterative learning and automatic assessment.
- It has been shown that LLMs with 7 billion parameters, when trained using the OLAPH framework, can produce extensive responses that are comparable in factual accuracy to those provided by medical experts.
In conclusion, this study proposes the OLAPH architecture to improve long-term medical responses through iterative training and introduces MedLFQA as a basis for evaluating the factual accuracy of these responses produced by LLMs. The findings show that OLAPH has the potential to greatly improve the reliability of LLMs in producing accurate medical information, which could be crucial for a number of medical applications.
Review the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 42k+ ML SubReddit
Tanya Malhotra is a final year student of University of Petroleum and Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with specialization in artificial intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with a burning interest in acquiring new skills, leading groups and managing work in an organized manner.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>




{kind=link}