 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have introduced impressive capabilities, particularly in reasoning tasks. Models like Openi's O1 use “long-thinking reasoning,” where complex problems are broken down into manageable steps and solutions are refined iteratively. While this approach improves problem solving, it comes at a cost: extended output sequences lead to increased computational time and energy usage. These inefficiencies raise concerns about the scalability and practical usability of such models in real-world applications. Addressing this issue is essential to making LLMs more efficient and widely applicable.
Researchers from Sun Yat-Sen University, China Agricultural University, Tsinghua University, Oxford University, Didichuxing and NTU propose Length scaling (o1-server). This technique seeks to reduce inefficiencies in reasoning models while maintaining precision. The main focus is on optimizing token usage, which is a significant bottleneck in current models. O1-Sirer uses reinforcement learning (RL) techniques to encourage the generation of shorter reasoning paths without sacrificing accuracy.
The process begins with evaluating baseline performance through the pre-broadcast. A custom RL-style loss function then adjusts the reasoning length of the model, ensuring that the generated solutions are proportional to the complexity of the problem. By aligning reasoning length with task difficulty, O1-Pirter reduces computational costs without compromising quality.
Technical details and benefits of O1-PROY
At the heart of O1-server is the length adjustment approach, which balances length and precision of reasoning. Key steps include:
- Reference model sampling: A benchmark model evaluates the quality and length of reasoning by generating multiple solutions for each problem, creating a performance benchmark.
- Reward Feature Design: This involves two components:
- Length reward: Shorter solutions relative to the reference model are encouraged.
- Accuracy reward: Ensures that shorter reasoning paths do not compromise correctness.
- Reinforcement learning framework: Proximal policy optimization (PPO) is used to train the model efficiently. Off-policy training further simplifies workflow and reduces training complexity.
O1-Priter benefits include:
- Improved efficiency: Reduces redundant calculations, leading to faster inference.
- Precision Preservation: Ensures that shorter solutions maintain or even improve accuracy.
- Task adaptability: Dynamically adjusts the depth of reasoning based on the complexity of the problem, making it applicable to a variety of tasks.
Results and ideas
Experiments on mathematical reasoning benchmarks such as Math, GSM8K, and Gaokao show the effectiveness of O1-Pruner. For example:
- The Marco-O1-7B model, tuned with O1-Perser, achieved a 40.5% reduction in solution length while improving accuracy to 76.8%.
- The QWQ-32B pre-model demonstrated a 34.7% reduction in solution length along with a slight increase in accuracy to 89.3%.
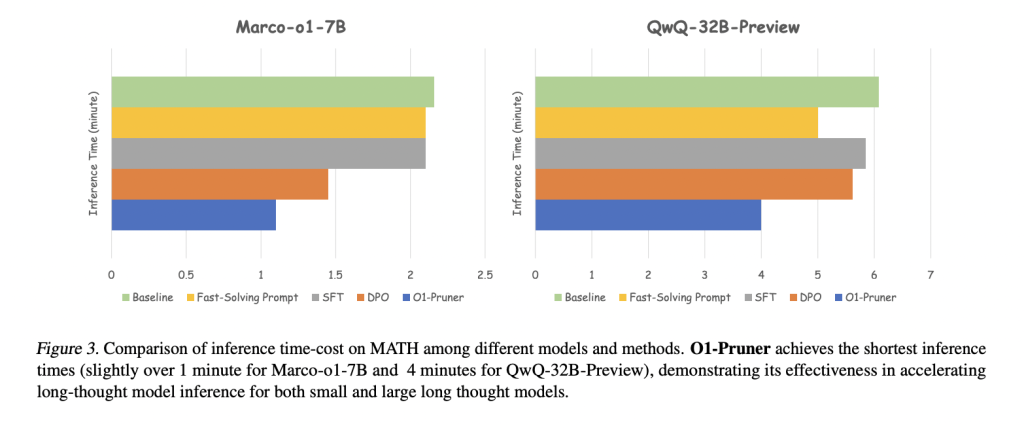
Inference time also improved significantly. In the math data set:
- Marco-O1-7B reduced its inference time from 2 minutes to just over 1 minute.
- QWQ-32B-preview decreased from 6 minutes to approximately 4 minutes.
These results highlight the ability of O1-server to balance accuracy and efficiency. Its superior performance, measured by Accuracy Efficiency Score (AES), establishes it as a better alternative to other methods such as supervised fine-tuning (SFT) and direct preference optimization (DPO).
Conclusion
O1-Sirer demonstrates that efficient reasoning in LLMS can be achieved without compromising accuracy. By harmonizing the length of reasoning with the complexity of the problem, it addresses the computational inefficiencies inherent in long-thinking reasoning. This work lays the foundation for additional advances in the optimization of reasoning models, allowing their application in various real-world scenarios where efficiency and accuracy are equally critical.
Verify he Paper and Github page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our telegram channel and LinkedIn GRsplash. Don't forget to join our 70k+ ml subreddit.
<a target="_blank" href="https://nebius.com/blog/posts/studio-embeddings-vision-and-language-models?utm_medium=newsletter&utm_source=marktechpost&utm_campaign=embedding-post-ai-studio” target=”_blank” rel=”noreferrer noopener”> (Recommended Read) NEBIUS ai Studio Expands with Vision Models, New Language Models, Embeddings, and Lora (Promoted)
Aswin AK is a Consulting Intern at MarktechPost. He is pursuing his dual degree from the Indian Institute of technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and practical experience solving real-life domain challenges.






{kind=link}