 NEWSLETTER
NEWSLETTER
Retrieval-augmented generation (RAG), a technique that improves the efficiency of large language models (LLMs) in handling large amounts of text, is central to natural language processing, particularly in applications such as question-answering, where maintaining the context of information is crucial to generating accurate answers. As language models evolve, researchers strive to push the boundaries by improving how these models process and retrieve relevant information from large-scale textual data.
One of the main problems with current LLMs is the difficulty in managing long contexts. As context length increases, models need help to maintain a clear focus on relevant information, which can lead to a significant drop in the quality of their answers. This problem is particularly pronounced in question-answering tasks, where accuracy is paramount. Models tend to be overwhelmed by the large volume of information, which can cause them to retrieve irrelevant data, thus diluting the accuracy of the answers.
In recent developments, LLMs such as GPT-4 and Gemini have been designed to handle much longer text sequences, with some models supporting up to a million context tokens. However, these advances come with their own set of challenges. While long-context LLMs can, in theory, handle larger inputs, they often introduce unnecessary or irrelevant chunks of information into the process, resulting in a lower accuracy rate. Therefore, researchers are still looking for better solutions to effectively manage long contexts while maintaining the quality of responses and efficiently using computational resources.
Researchers at NVIDIA, based in Santa Clara, California, proposed an order-preserving retrieval and augmented generation (OP-RAG) approach to address these challenges. OP-RAG offers a substantial improvement over traditional RAG methods by preserving the order of retrieved text fragments for processing. Unlike existing RAG systems, which prioritize fragments based on relevance scores, the OP-RAG mechanism preserves the original sequence of the text, ensuring that context and consistency are maintained throughout the retrieval process. This advancement enables a more structured retrieval of relevant information, avoiding the problems of traditional RAG systems that may retrieve highly relevant but out-of-context data.
The OP-RAG method introduces an innovative mechanism that restructures the way information is processed. First, large-scale text is broken down into smaller, sequential chunks. These chunks are then evaluated based on their relevance to the query. Instead of ranking them solely by relevance, OP-RAG ensures that the chunks are kept in their original order, as they appeared in the source document. This sequential preservation helps the model focus on retrieving the most contextually relevant data without introducing irrelevant distractions. The researchers demonstrated that this approach significantly improves the quality of answer generation, particularly in context-heavy scenarios, where maintaining consistency is essential.
The performance of the OP-RAG method was extensively tested against other leading models. NVIDIA researchers conducted experiments using public datasets such as the EN.QA and EN.MC benchmarks from ∞Bench. Their results showed a marked improvement in both accuracy and efficiency compared to traditional long-context LLMs without RAG. For example, on the EN.QA dataset, which contains an average of 150,374 words per context, OP-RAG achieved a maximum F1 score of 47.25 while using 48,000 tokens as input, a significant improvement over models such as GPT-4O. Similarly, on the EN.MC dataset, OP-RAG outperformed other models by a considerable margin, achieving an accuracy of 88.65 with only 24,000 tokens, while the traditional Llama3.1 model without RAG could only achieve an accuracy of 71.62 using 117,000 tokens.
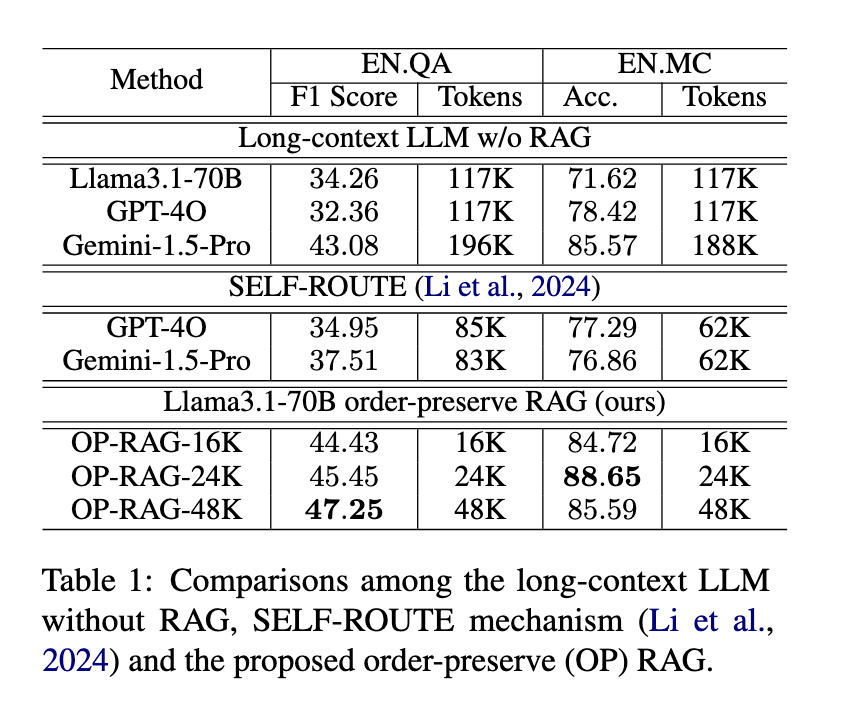
Further comparisons showed that OP-RAG improved the quality of the generated responses and dramatically reduced the number of tokens required, making the model more efficient. Traditional long-context LLMs, such as GPT-4O and Gemini-1.5-Pro, required nearly twice the number of tokens compared to OP-RAG to achieve lower performance scores. This efficiency is particularly valuable in real-world applications, where computational costs and resource allocation are critical factors for deploying large-scale language models.
In conclusion, OP-RAG represents a significant advancement in the field of retrieval-augmented generation, offering a solution to the limitations of long-context LLMs. By preserving the order of retrieved text fragments, the method enables more consistent and contextually relevant response generation, even in large-scale question answering tasks. NVIDIA researchers have demonstrated that this innovative approach outperforms existing methods in terms of quality and efficiency, making it a promising solution for future advancements in natural language processing.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and LinkedInJoin our Telegram Channel.
If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Nikhil is a Consultant Intern at Marktechpost. He is pursuing an integrated dual degree in Materials from Indian Institute of technology, Kharagpur. Nikhil is an ai and Machine Learning enthusiast who is always researching applications in fields like Biomaterials and Biomedical Science. With a strong background in Materials Science, he is exploring new advancements and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}