 NEWSLETTER
NEWSLETTER
Large language models (LLM) have become vital in all domains, allowing high performance applications, such as natural language generation, scientific research and conversational agents. Under these advances are the architecture of the transformer, where the alternative layers of care mechanisms and the advances (FFN) sequentially process the tokenized entrance. However, with an increase in size and complexity, the computational load required for inference grows substantially, creating an efficiency bottleneck. Efficient inference is now a critical concern, with many research groups that focus on strategies that can reduce latency, increase performance and reduce computational costs while maintaining or improve model performance.
In the center of this efficiency problem is the inherently sequential structure of the transformers. The exit of each layer feeds on the next, demanding a strict order and a synchronization, which is especially problematic at scale. As the model sizes expand, the cost of the calculation and sequential communication between the GPUs grows, which leads to reduced efficiency and a higher cost of implementation. This challenge is amplified in scenarios that require a rapid and multiple token generation, as real -time assistants. Reducing this sequential load while maintaining the model of the model presents a key technical obstacle. Unlocking new parallel strategies that preserve precision, but significantly reduce calculation depth is essential to expand the accessibility and scalability of LLM.
Several techniques have emerged to improve efficiency. Quantization reduces the precision of numerical representations to minimize memory and calculation needs, although precision losses often risk, especially at low bits width. Pruning eliminates redundant parameters and simplifies the models, but potentially harms the precision without care. Expert mix models (MOE) activate only a subset of parameters per entrance, making them highly efficient for specific workloads. Even so, they can have a lower performance to intermediate lot sizes due to low hardware use. Although valuable, these strategies have compensation that limit their universal applicability. Consequently, the field seeks methods that offer wide efficiency improvements with less commitments, especially for dense architectures that are simpler to train, deploy and maintain.
Nvidia researchers introduced a new architectural optimization technique named FFN Fusionthat addresses the sequential bottleneck in the transformers identifying FFN sequences that can be executed in parallel. This approach arose from the observation that when the attention layers are eliminated using a puzzle tool, models often retain long sequences of consecutive FFN. These sequences show minimal interdependence and, therefore, can be processed simultaneously. When analyzing the LLM structure as a call-3.1-405b-instrument, the researchers created a new model called Ultra-253b-base when pruning and restructuring the base model through FFN Fusion. This method results in a significantly more efficient model that maintains competitive performance.
FFN Fusion fuses multiple consecutive FFN layers in a single wider FFN. This process is based on mathematical equivalence: by concatenating the weights of several FFN, a single module can occur that behaves as the sum of the original layers but can be calculated in parallel. For example, if three FFNs are stacked sequentially, each depends on the exit of the previous one, its merger eliminates these units by ensuring that the three work with the same entry and their outputs are added. The theoretical basis for this method shows that the fused FFN maintains the same capacity for representation. The researchers carried out a dependency analysis using the cosine distance between FFN exits to identify regions with low interdependence. These regions were considered optimal for fusion, since a minimum change in the direction of Token between the layers indicated the viability of parallel processing.
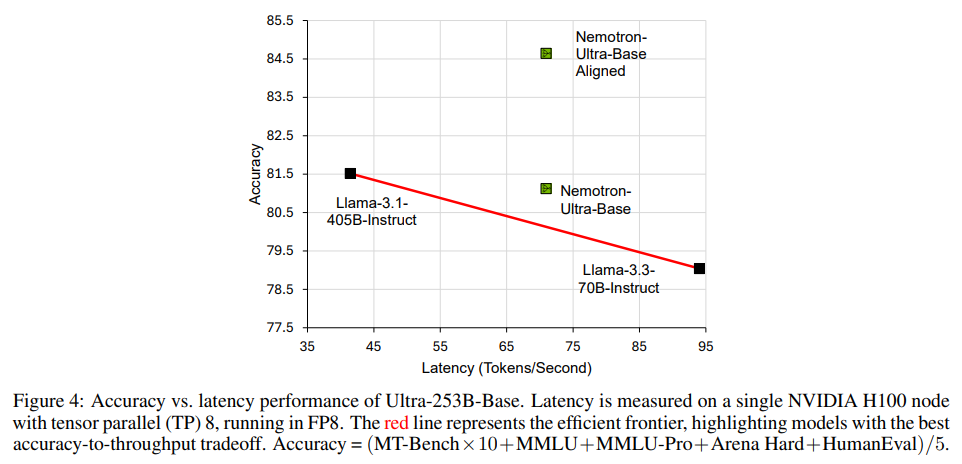
The FFN Fusion application to the Llala-405B model resulted in an Ultra-253B base, which delivered notable profits in the speed and efficiency of resources. Specifically, the new model achieved an improvement of 1.71X in the latency of inference and a computational cost per weed reduced by 35x to a lot by lots of 32. This efficiency was not at the expense of capacity. Ultra-253b-Base obtained 85.17% in MMLU, 72.25% in Mmlu-Pro, 84.92% in hard sand, 86.58% in Humaneval and 9.19 in MT-Bench. These results often coincided or exceeded the original 405B-Parameter model, although ultra-253b-base contained only 253 billion parameters. The use of memory also improved with a 2 × reduction in the KV-Cache requirements. The training process involved distilling 54 billion tokens in an 8K context window, followed by an setting set to the 16k, 32k and 128k contexts. These steps assured that the fused model maintained high precision while benefiting from the reduced size.
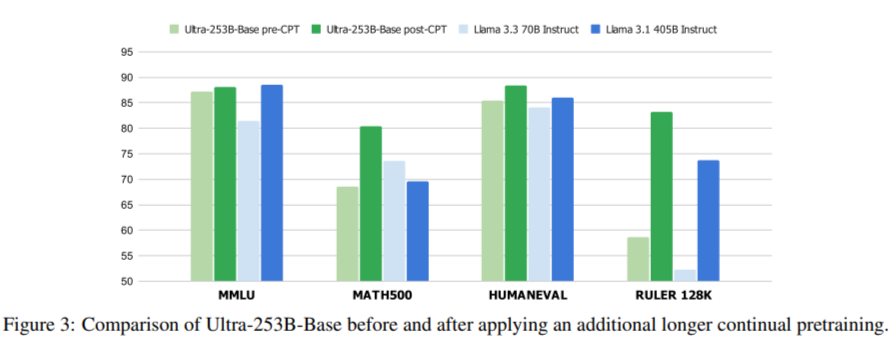
This research demonstrates how the reflective architectural redesign can unlock significant efficiency profits. The researchers showed that FFN layers in transformative architectures are often more independent than what was previously supposed. Its method to quantify the dependence between layers and the structures of transformation models allowed a broader application in models of various sizes. The technique was also validated in a 70b parameter model, which demonstrates generalization. Other experiments indicated that although FFN layers often can be merged with a minimum impact, complete blocking parallel, including attention, introduces greater performance degradation due to stronger interdependencies.
Several key conclusions of FFN Fusion research:
- The FFN fusion technique reduces the sequential calculation in the transformers by parallel to low dependence FFN layers.
- The fusion is achieved by replacing FFN sequences with a single wider FFN using concatenated weights.
- Ultra-253b-Base, derived from flame-3.1-405b, achieves 1.71x faster inference and 35 times a lower token cost.
- The reference results include: 85.17% (MMLU), 72.25% (MMLU-PRO), 86.58% (Humaneval), 84.92% (hard sand) and 9.19 (MT-BENCH).
- The use of memory is cut in half due to KV-Cache optimization.
- FFN fusion is more effective at larger model scales and works well with techniques such as pruning and quantization.
- The complete parallel of the transformer blocking shows potential, but requires more research due to stronger interdependencies.
- A systematic method that uses cosine distance helps identify which FFN sequences are safe to merge.
- The technique is validated in different model sizes, including 49b, 70b and 253b.
- This approach establishes the most friendly LLM designs for hardware and efficient in the hardware.
Verify he Paper. All credit for this investigation goes to the researchers of this project. In addition, feel free to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter And don't forget to join our 85k+ ml of submen.
Asif Razzaq is the CEO of Marktechpost Media Inc .. as a visionary entrepreneur and engineer, Asif undertakes to take advantage of the potential of artificial intelligence for the social good. Its most recent effort is the launch of an artificial intelligence media platform, Marktechpost, which stands out for its deep coverage of automatic learning and deep learning news that is technically solid and easily understandable by a broad audience. The platform has more than 2 million monthly views, illustrating its popularity among the public.






{kind=link}