In today's world, the reliability Of the data solutions it is everything. When we build panels and reports, one expects the numbers reflected there to be correct and updated. According to these numbers, ideas are drawn and measures are taken. For any unforeseen reason, if the panels are broken or if the numbers are incorrect, then it becomes a Fire fighting To fix everything. If the problems are not solved over time, then it damages the trust placed on the data equipment and its solutions.
But why would the panels break or have wrong numbers? If the board was correctly built the first time, then 99% of the time the problem comes from the data that feed the panels, from the data warehouse. Some possible scenarios are:
Few ETL pipes failed, so the new data is not yet in
One table is replaced by a new
Some columns in the table are dropped or renamed
The schemes in the data warehouse have changed
And many more.
There is still the possibility that the problem is on the Tableau site, but in my experience, most of the time, it is always due to some changes in the data warehouse. Although we know the root cause, it is not always easy to start working in a solution. There is There is no central place where you can verify which Tableau data sources depend on specific tables. If you have the Tableau data management complement, you could help, but from what I know, it is difficult to find custom SQL queries used in data sources.
However, the complement is too expensive and most companies do not have it. The real pain begins when you have to go through all the data sources manually to start fixing it. In addition to him, he has a chain of users in his head waiting impatiently a rapid fixation. The solution itself could not be difficult, it would only be a time.
What if we could anticipate these problems and Identify affected data sources before someone noticed a problem? Wouldn't that be great? Well, now there is a way with the painting Metadata API. The Metadata API uses Graphql, a consultation language for API that returns only the data that interests you. For more information about what is possible with Graphql, see Graphql.org.
In this blog post, I will show you how to connect to Tableau metadata API Use of the Python Tableau server customer (TSC) Library to proactively identifyData sources that use specific tables, so that you can act quickly before problems arise. Once you know which Tableau data sources are affected by a specific table, you can make some updates yourself or alert the owners of those data sources about the next changes so that they can be prepared for it.
Connect to the Tableau metadata API
We are going to connect to the Tableau server using TSC. We need to import all the libraries that we would need for exercise!
### Import all required libraries
import tableauserverclient as t
import pandas as pd
import json
import ast
import re
To connect to the Metadata API, you must first create a personal access token in the configuration of your Tableau account. Then update the AND With the token you just created. Update too With your tableu site. If the connection is established correctly, “connected” in the output window will be printed.
### Connect to Tableau server using personal access token
tableau_auth = t.PersonalAccessTokenAuth("", "",
site_id="")
server = t.Server("https://dub01.online.tableau.com/", use_server_version=True)
with server.auth.sign_in(tableau_auth):
print("Connected")
Now we obtain a list of all the data sources published in its place. There are many attributes that you can obtain, but in the case of current use, we keep simple and only obtain the ID, the name and contact information of the owner for each data source. This will be our master list to which we will add all the other information.
############### Get all the list of data sources on your Site
all_datasources_query = """ {
publishedDatasources {
name
id
owner {
name
email
}
}
}"""
with server.auth.sign_in(tableau_auth):
result = server.metadata.query(
all_datasources_query
)
Since I want this blog to focus on how to proactively identify which data sources are affected by a specific table, I will not enter the nuances of the metadata API. To better understand how the consultation works, you can check a very detailed picture. Metadata API documentation.
One thing to keep in mind is that the metadata API returns data in JSON format. Depending on what you are consulting, it will end with multiple Json lists and can be very difficult to turn this into a pandas data frame. For the previous metadata consultation, it will end with a result that you would like below (these are simulated data just to give an idea of how the exit is seen):
We need to convert this JSON answer into a data frame to work. Note that we need to extract the name and email of the owner from within the object of the owner.
### We need to convert the response into dataframe for easy data manipulation
col_names = result('data')('publishedDatasources')(0).keys()
master_df = pd.DataFrame(columns=col_names)
for i in result('data')('publishedDatasources'):
tmp_dt = {k:v for k,v in i.items()}
master_df = pd.concat((master_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T))
# Extract the owner name and email from the owner object
master_df('owner_name') = master_df('owner').apply(lambda x: x.get('name') if isinstance(x, dict) else None)
master_df('owner_email') = master_df('owner').apply(lambda x: x.get('email') if isinstance(x, dict) else None)
master_df.reset_index(inplace=True)
master_df.drop(('index','owner'), axis=1, inplace=True)
print('There are ', master_df.shape(0) , ' datasources in your site')
This is how the structure of master_df It would look like:
Exit example of the code
Once we have the main list, we can move on and start obtaining the names of the tables embedded in the data sources. If it is an avid user of Tableau, you know that there are two ways to select tables in a Tableau data source: one is to directly choose the tables and establish a relationship between them and the other is to use a personalized SQL query with one or more tables to achieve a new resulting table. Therefore, we must address both cases.
Personalized SQL query table processing
The consultation is shown below to obtain the list of all custom SQL used on the site along with their data sources. Note that I have filtered the list to obtain only the first 500 custom SQL inquiries. In case there are more in your organization, you will have to use a displacement to obtain the following custom SQL queries set. There is also an option to use the cursor method in pagination when you want to obtain a large results list (see here). For the sake of simplicity, I only use the compensation method as I know, since there are less than 500 custom SQL queries used on the site.
# Get the data sources and the table names from all the custom sql queries used on your Site
custom_table_query = """ {
customSQLTablesConnection(first: 500){
nodes {
id
name
downstreamDatasources {
name
}
query
}
}
}
"""
with server.auth.sign_in(tableau_auth):
custom_table_query_result = server.metadata.query(
custom_table_query
)
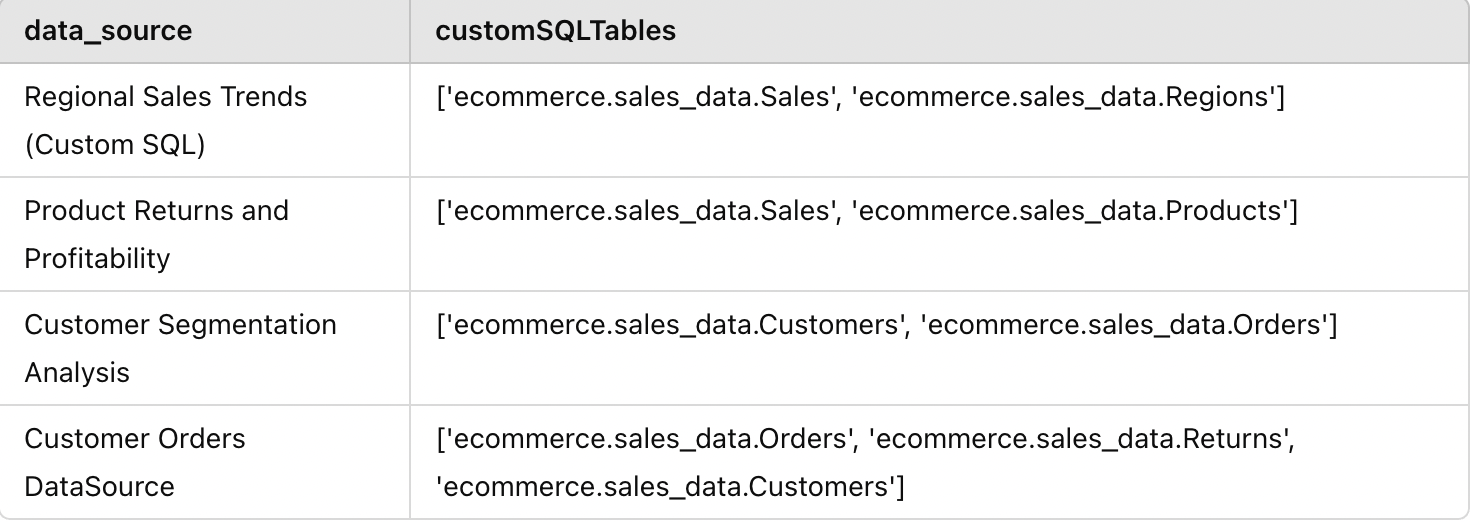
According to our simulated data, this is how our result would be seen:
{
"data": {
"customSQLTablesConnection": {
"nodes": (
{
"id": "csql-1234",
"name": "RegionalSales_CustomSQL",
"downstreamDatasources": (
{
"name": "Regional Sales Trends (Custom SQL)"
}
),
"query": "SELECT r.region_name, SUM(s.sales_amount) AS total_sales FROM ecommerce.sales_data.Sales s JOIN ecommerce.sales_data.Regions r ON s.region_id = r.region_id GROUP BY r.region_name"
},
{
"id": "csql-5678",
"name": "ProfitabilityAnalysis_CustomSQL",
"downstreamDatasources": (
{
"name": "Product Returns and Profitability"
}
),
"query": "SELECT p.product_category, SUM(s.profit) AS total_profit FROM ecommerce.sales_data.Sales s JOIN ecommerce.sales_data.Products p ON s.product_id = p.product_id GROUP BY p.product_category"
},
{
"id": "csql-9101",
"name": "CustomerSegmentation_CustomSQL",
"downstreamDatasources": (
{
"name": "Customer Segmentation Analysis"
}
),
"query": "SELECT c.customer_id, c.location, COUNT(o.order_id) AS total_orders FROM ecommerce.sales_data.Customers c JOIN ecommerce.sales_data.Orders o ON c.customer_id = o.customer_id GROUP BY c.customer_id, c.location"
},
{
"id": "csql-3141",
"name": "CustomerOrders_CustomSQL",
"downstreamDatasources": (
{
"name": "Customer Orders DataSource"
}
),
"query": "SELECT o.order_id, o.customer_id, o.order_date, o.sales_amount FROM ecommerce.sales_data.Orders o WHERE o.order_status = 'Completed'"
},
{
"id": "csql-3142",
"name": "CustomerProfiles_CustomSQL",
"downstreamDatasources": (
{
"name": "Customer Orders DataSource"
}
),
"query": "SELECT c.customer_id, c.customer_name, c.segment, c.location FROM ecommerce.sales_data.Customers c WHERE c.active_flag = 1"
},
{
"id": "csql-3143",
"name": "CustomerReturns_CustomSQL",
"downstreamDatasources": (
{
"name": "Customer Orders DataSource"
}
),
"query": "SELECT r.return_id, r.order_id, r.return_reason FROM ecommerce.sales_data.Returns r"
}
)
}
}
}
As before, when we were creating the master list of data sources, we have also nested JON for subsequent data sources where we would need to extract only the “name”. In the “Consultation” column, the entire custom SQL is downloaded. If we use the regx pattern, we can easily search the names of the table used in the consultation.
We know that the names of the table always come after a union clause and generally follow the format ..
. He It is optional and most of the time they are not used. There were some consultations that I found that they used this format and I ended up only obtaining the names of the database and the scheme, and not the full name of the table. Once we have extracted the names of the data sources and the names of the tables, we need to merge the ranks by data source, since there may be multiple custom SQL queries used in a single data source.
### Convert the custom sql response into dataframe
col_names = custom_table_query_result('data')('customSQLTablesConnection')('nodes')(0).keys()
cs_df = pd.DataFrame(columns=col_names)
for i in custom_table_query_result('data')('customSQLTablesConnection')('nodes'):
tmp_dt = {k:v for k,v in i.items()}
cs_df = pd.concat((cs_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T))
# Extract the data source name where the custom sql query was used
cs_df('data_source') = cs_df.downstreamDatasources.apply(lambda x: x(0)('name') if x and 'name' in x(0) else None)
cs_df.reset_index(inplace=True)
cs_df.drop(('index','downstreamDatasources'), axis=1,inplace=True)
### We need to extract the table names from the sql query. We know the table name comes after FROM or JOIN clause
# Note that the name of table can be of the format ..
# Depending on the format of how table is called, you will have to modify the regex expression
def extract_tables(sql):
# Regex to match database.schema.table or schema.table, avoid alias
pattern = r'(?:FROM|JOIN)s+((?:(w+)|w+).(?:(w+)|w+)(?:.(?:(w+)|w+))?)b'
matches = re.findall(pattern, sql, re.IGNORECASE)
return list(set(matches)) # Unique table names
cs_df('customSQLTables') = cs_df('query').apply(extract_tables)
cs_df = cs_df(('data_source','customSQLTables'))
# We need to merge datasources as there can be multiple custom sqls used in the same data source
cs_df = cs_df.groupby('data_source', as_index=False).agg({
'customSQLTables': lambda x: list(set(item for sublist in x for item in sublist)) # Flatten & make unique
})
print('There are ', cs_df.shape(0), 'datasources with custom sqls used in it')
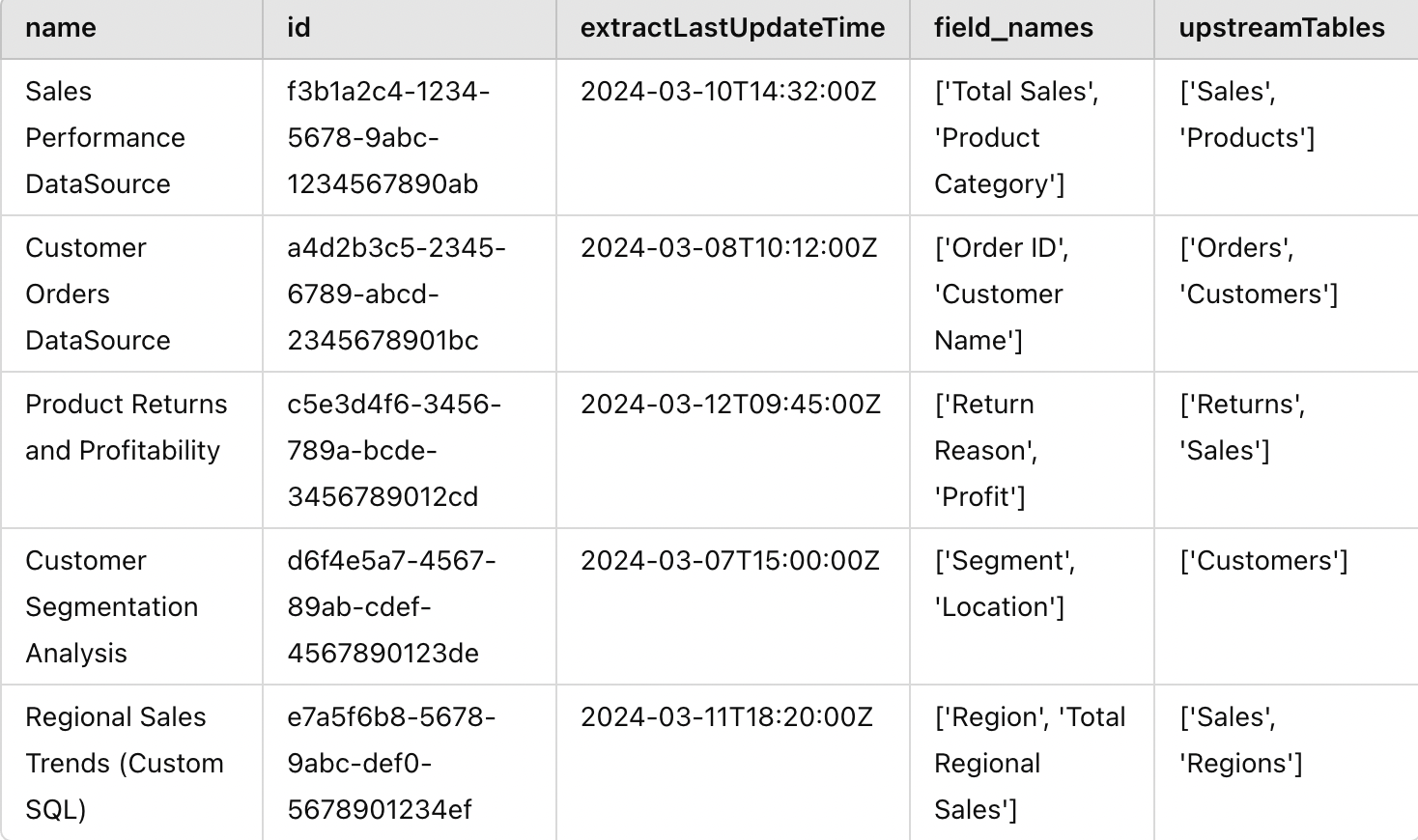
After performing all the previous operations, this is how the structure of cs_df It would look like:
Exit example of the code
Regular tables processing in data sources
Now we need to obtain the list of all the regular tables used in a data source that are not part of custom SQL. There are two ways to do it. Or use the publishedDatasources object and verify upstreamTables or use DatabaseTable and verify upstreamDatasources. I will pass the first method because I want the results at a data source level (basically, I want a code to be reused when I want to verify a specific data source in more detail). Here again, for the sake of simplicity, instead of going to pagination, I am walking through each data source to make sure you have everything. We get the upstreamTables Within the field object, that must be cleaned.
############### Get the data sources with the regular table names used in your site
### Its best to extract the tables information for every data source and then merge the results.
# Since we only get the table information nested under fields, in case there are hundreds of fields
# used in a single data source, we will hit the response limits and will not be able to retrieve all the data.
data_source_list = master_df.name.tolist()
col_names = ('name', 'id', 'extractLastUpdateTime', 'fields')
ds_df = pd.DataFrame(columns=col_names)
with server.auth.sign_in(tableau_auth):
for ds_name in data_source_list:
query = """ {
publishedDatasources (filter: { name: """"+ ds_name + """" }) {
name
id
extractLastUpdateTime
fields {
name
upstreamTables {
name
}
}
}
} """
ds_name_result = server.metadata.query(
query
)
for i in ds_name_result('data')('publishedDatasources'):
tmp_dt = {k:v for k,v in i.items() if k != 'fields'}
tmp_dt('fields') = json.dumps(i('fields'))
ds_df = pd.concat((ds_df, pd.DataFrame.from_dict(tmp_dt, orient='index').T))
ds_df.reset_index(inplace=True)
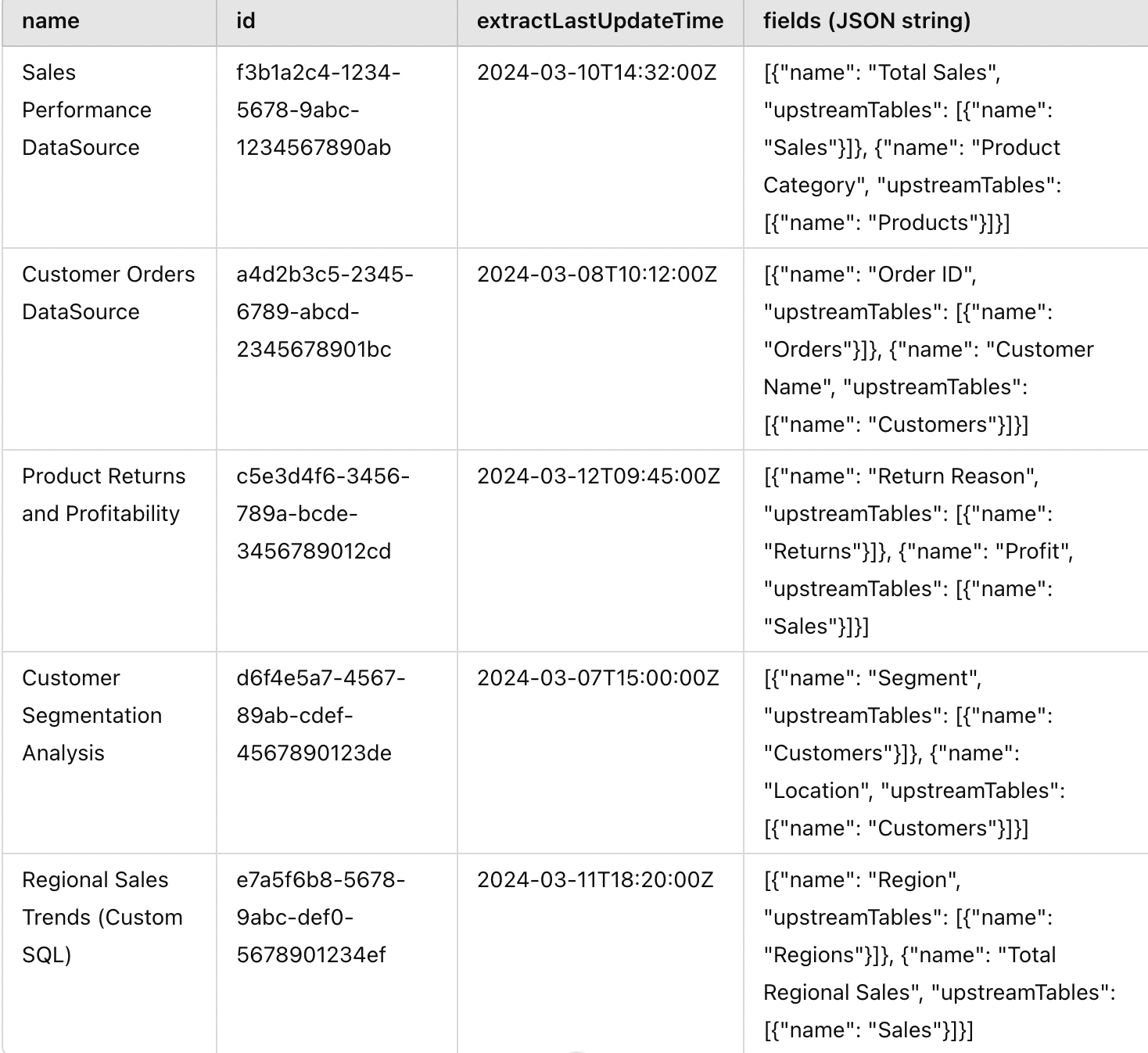
This is how the structure of ds_df It would be seen:
Exit example of the code
We may need to flatten the fields Object and remove field names, as well as the names of the table. Since the names of the table will be repeated several times, we would have to deduce to keep only the only ones.
# Function to extract the values of fields and upstream tables in json lists
def extract_values(json_list, key):
values = ()
for item in json_list:
values.append(item(key))
return values
ds_df("fields") = ds_df("fields").apply(ast.literal_eval)
ds_df('field_names') = ds_df.apply(lambda x: extract_values(x('fields'),'name'), axis=1)
ds_df('upstreamTables') = ds_df.apply(lambda x: extract_values(x('fields'),'upstreamTables'), axis=1)
# Function to extract the unique table names
def extract_upstreamTable_values(table_list):
values = set()a
for inner_list in table_list:
for item in inner_list:
if 'name' in item:
values.add(item('name'))
return list(values)
ds_df('upstreamTables') = ds_df.apply(lambda x: extract_upstreamTable_values(x('upstreamTables')), axis=1)
ds_df.drop(("index","fields"), axis=1, inplace=True)
Once we do the previous operations, the final structure of ds_df Something like like this would be seen:
Exit example of the code
We have all the pieces and now we only have to merge them:
###### Join all the data together
master_data = pd.merge(master_df, ds_df, how="left", on=("name","id"))
master_data = pd.merge(master_data, cs_df, how="left", left_on="name", right_on="data_source")
# Save the results to analyse further
master_data.to_excel("Tableau Data Sources with Tables.xlsx", index=False)
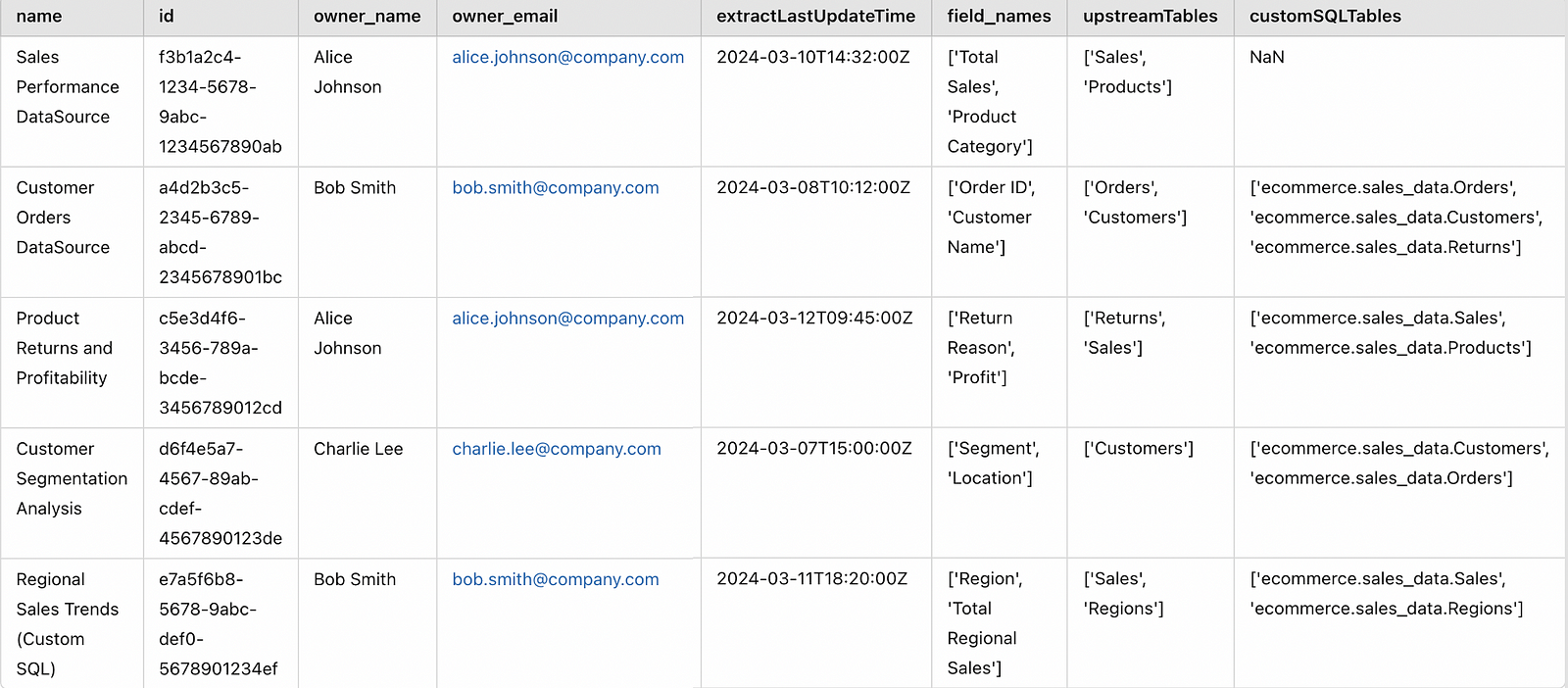
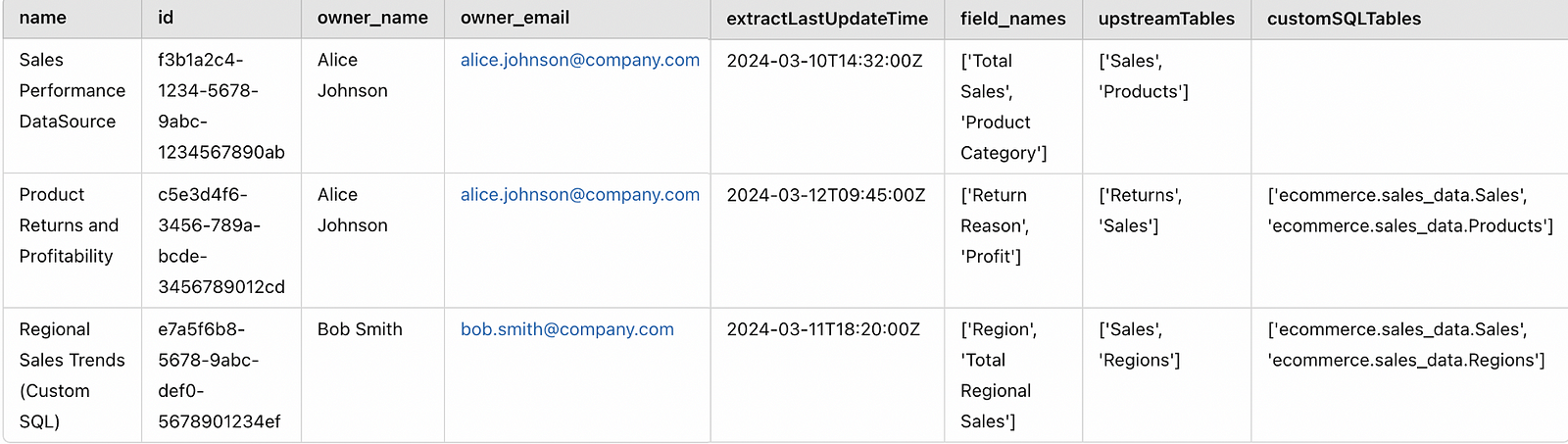
This is our final master_data:
Exit example of the code
Table level impact analysis
Let's say there were some scheme changes in the “sales” table and want to know which data sources will be affected. Then you can simply write a small function that verifies if a table is present in any of the two columns –upstreamTableseither customSQLTables as below.
def filter_rows_with_table(df, col1, col2, target_table):
"""
Filters rows in df where target_table is part of any value in either col1 or col2 (supports partial match).
Returns full rows (all columns retained).
"""
return df(
df.apply(
lambda row:
(isinstance(row(col1), list) and any(target_table in item for item in row(col1))) or
(isinstance(row(col2), list) and any(target_table in item for item in row(col2))),
axis=1
)
)
# As an example
filter_rows_with_table(master_data, 'upstreamTables', 'customSQLTables', 'Sales')
The output is shown below. You can see that this change will affect 3 data sources. You can also alert the owners of the Alice and Bob data source in advance on this so that they can start working in a solution before something is broken in the Tableau panels.
Exit example of the code
You can consult the full version of the code in my github repository here.
This is only one of the possible cases of use of the Tableau metadata API. You can also extract the field names used in custom SQL queries and add to the data set to obtain an impact analysis at the field level. You can also monitor obsolete data sources with the extractLastUpdateTime To see if they have any problem or it is necessary to file if they are no longer used. We can also use the dashboards Object to obtain information at the board level.
Final thoughts
If you have come so far, congratulations. This is just a case of use to automate Tableau data management. It is time to reflect on your own work and think which of those other tasks could automate to facilitate your life. I hope this mini project has served as a pleasant learning experience to understand the power of the Tableau metadata API. If you liked to read this, you will also like another of my blog publications about Tableau, in some of the challenges I faced when dealing with Big.
Also see my previous blog where I explored to build an interactive application with database with Python, Streamlit and SQLite.
Before you go …
Follow me so that you do not miss any new publication that you write in the future; You will find more of my articles in me. You can also connect with me in LinkedIn either <a target="_blank" href="https://twitter.com/sravani_alle” target=”_blank” rel=”noreferrer noopener”>twitter!
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″> (Tagstotranslate) Data management
Get statistical information using Pandas and the YouTube Data APIPhoto by Glenn Carstens-Peters, unpackToday, there are more than 2.7 billion active YouTube users, and for many people, YouTube is not just entertainment but an important source of income. but how does it work? How many views or subscribers can different…
CoinGecko, a leading independent cryptocurrency data aggregator, recently announced the acquisition of Zash. This strategic move is intended to augment CoinGecko's cryptocurrency services by incorporating Zash's nft information into its API, offering users a holistic view of fungible and non-fungible tokens. CoinGecko announces acquisition of Zash CoinGecko Announced Earlier this…
OpenSea, a popular trading platform in the non-fungible token (nft) space, has reportedly warned its users about the safety of their API keys. This action comes after Nansen disclosed that its customer data may have been compromised due to a security incident. On Friday, September 22, the prominent blockchain data…
 NEWSLETTER
NEWSLETTER








{kind=link}