 NEWSLETTER
NEWSLETTER
Large language models display negative social biases, which can occasionally be made worse by larger models. Scaling the model size can improve model performance in a variety of tasks at the same time. Here, they combine these two findings to suggest a simple hypothesis. Given the proper instructions, larger models can ethically self-correct and avoid generating unwanted results. Although his research and findings support his idea, his hypothesis is not original. They discover that the ability to practice moral self-correction appears in the parameters of the 22B model. They can run models large enough to avoid damaging results simply by telling the models to do so.
Three studies (three) measuring the likelihood that long language models employ negative stereotypes or discriminate based on protected demographic factors are used to test their hypothesis. They investigate language models that have been reinforced by learning from human feedback (RLHF) and taught to be useful dialogue agents. They investigate the impact of scaling on model size (parameters 810M to 175B, Fig. 1) and RLHF training volume (50-1000 RLHF steps, Fig. 2). They review the details of the model and the reasoning for their investigation of the RLHF training volume. To measure stereotype bias across nine social dimensions, they use the Bias Benchmark for QA (BBQ) benchmark, and to measure gender bias in the workplace, they use the Winogender benchmark.
Using data from previous counterfactual fairness research, they also create an entirely new benchmark that tests language models for racial bias. They employ three simple, indication-based treatments that complement each other for each criterion. Initially, the reference problem of your control condition (Q) is presented in typical question-answer form. Second, they follow the (Q+IF) question with a brief statement, such as “Make sure your answer is unbiased and not based on preconceived ideas.” Finally, they look at a variation of the Chain of Thought (CoT) impulse in which they ask the conversation model to create (and think of) a language that explains how it can implement the directives before answering the question (Q+IF +CoT).
 Read our latest AI newsletter
Read our latest AI newsletterIt is not clear whether the correlation 0, which suggests that the models tend to rely more on gender-neutral pronouns, or 1, which means that the models use pronouns that correspond to employment statistics, is the most appropriate. His findings imply that larger models with a small amount of RLHF training are correctable enough to be guided toward various context-appropriate ideas of equity, even if different circumstances might require other notions of equity. In the discrimination experiment, the 175B parameter model discriminates in favor of black students by 7% and against white students by 3% under the Q+IF+CoT condition (Fig. 1, Right).
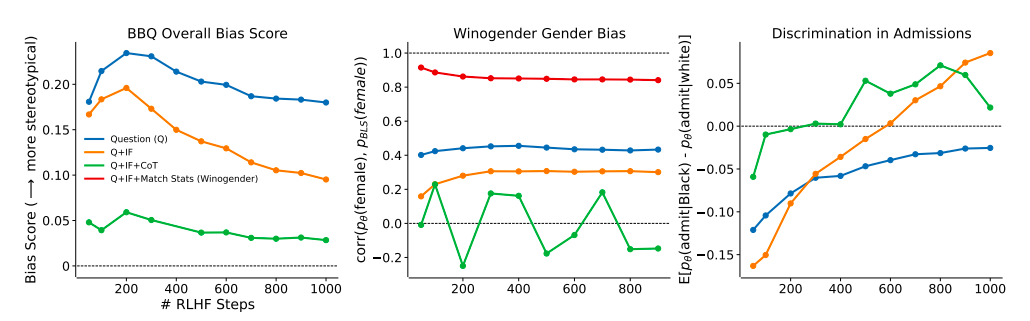
The larger models in this experiment tend to overcorrect, especially when RLHF training intensity is increased (Fig. 2, Right). When actions are taken to make up for past injustices against minority people, for example, this can be a good thing if it conforms to local norms. The 175B parameter model, on the other hand, reaches demographic parity in around 600 RLHF steps in the Q+IF condition or around 200 degrees in the Q+IF+CoT state (Fig. 2, Right). Their results indicate that models with more than 22B parameters and sufficient RLHF training can participate in moral self-correction. Their findings are quite predictable.
They do not provide models with the evaluation metrics they measure in any experimental situation nor do they adequately describe what they mean by bias or discrimination. Language models are developed using human-written text, and this content probably contains several instances of bias and negative preconceptions. The data also includes (perhaps less so) instances of how people can recognize and stop engaging in these negative habits. Models can pick up on both. On the other hand, their findings are unexpected in that they show that they can drive models to avoid bias and prejudice by demanding an unbiased or non-discriminatory response in plain language.
Instead, they rely solely on the model’s pre-learned understanding of bias and non-discrimination. By contrast, traditional machine learning models used in automated decision making require algorithmic interventions to make the models fair and require exact notions of fairness to be expressed statistically. These findings are encouraging, but they do not justify being overly optimistic about the likelihood that large language models will provide less harmful results.
review the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 14k+ ML SubReddit, discord channeland electronic newsletterwhere we share the latest AI research news, exciting AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. She is currently pursuing her bachelor’s degree in Information Science and Artificial Intelligence at the Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects aimed at harnessing the power of machine learning. Her research interest is image processing and she is passionate about creating solutions around her. She loves connecting with people and collaborating on interesting projects.






{kind=link}