 NEWSLETTER
NEWSLETTER
In the era of increasingly large language models and complex neural networks, optimizing model efficiency has become paramount. Weight quantization stands out as a crucial technique to reduce model size and improve inference speed without significant performance degradation. This guide provides a practical approach to implementing and understanding weight quantization, using GPT-2 as our practical example.
Learning objectives
- Understand the fundamentals of weight quantization and its importance in model optimization.
- Learn the differences between ABSMAX and zero point quantization techniques.
- Implement weight quantization methods in GPT-2 using Pytorch.
- Analyze the impact of quantization on memory efficiency, inference speed, and accuracy.
- Visualize quantified weight distributions using histograms for insights.
- Evaluate model performance after quantization through text generation and perplexity metrics.
- Explore the benefits of quantization for deploying models to resource-constrained devices.
This article was published as part of the Data Science Blogathon.
Understand the basics of weight quantification
Weight quantization converts high-precision floating-point weights (typically 32-bit) to lower-precision representations (commonly 8-bit integers). This process significantly reduces model size and memory usage while attempting to preserve model performance. The key challenge lies in maintaining model accuracy while reducing numerical precision.
Why quantize?
- Memory efficiency: Reducing precision from 32 bits to 8 bits can theoretically reduce model size by 75%
- Faster inference: Integer operations are generally faster than floating point operations
- Lower energy consumption: Reduced memory bandwidth and simpler calculations lead to power savings
- Implementation Flexibility: Smaller models can be deployed on devices with resources
Practical implementation
Let's get to the implementation of two popular quantization methods: ABSMAX quantization and zero point quantization.
Environment Settings
First, we will set up our development environment with the necessary dependencies:
import seaborn as sns
import torch
import numpy as np
from transformers import AutoModelForCausalLM, AutoTokenizer
from copy import deepcopy
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import seaborn as snsNext we will look for the implementation of quantization methods:
ABSMAX quantization
The ABSMAX quantization method scales the weights based on the maximum absolute value in the tensor:
# Define quantization functions
def absmax_quantize(x):
scale = 100 / torch.max(torch.abs(x)) # Adjusted scale
X_quant = (scale * x).round()
X_dequant = X_quant / scale
return X_quant.to(torch.int8), X_dequantThis method works by:
- Find the maximum absolute value in the weight tensor
- Calculate a scaling factor to fit values within the INT8 range
- Scale and round values
- Provide quantified and decanted versions
Key advantages:
- Simple implementation
- Good preservation of large values
- Symmetric quantization around zero
Zero point quantization
Zero-point quantization adds an offset to better handle skewed distributions:
def zeropoint_quantize(x):
x_range = torch.max(x) - torch.min(x)
x_range = 1 if x_range == 0 else x_range
scale = 200 / x_range
zeropoint = (-scale * torch.min(x) - 128).round()
X_quant = torch.clip((x * scale + zeropoint).round(), -128, 127)
X_dequant = (X_quant - zeropoint) / scale
return X_quant.to(torch.int8), X_dequantProduction:
Using device: cudaThis method:
- Calculates the full range of values
- Determines the scale and zero point parameters
- Apply scale and change
- Clips values to ensure int8 limits
Benefits:
- Better handling of asymmetric distributions
- Improved representation of values close to zero
- Often results in better overall accuracy
Loading and preparing the model
Let's apply these quantization methods to a real model. We'll use GPT-2 as our example:
# Load model and tokenizer
model_id = 'gpt2'
model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Print model size
print(f"Model size: {model.get_memory_footprint():,} bytes")Production:
Quantization process: weights and model
Dive in to apply quantization techniques to both individual weights and the entire model. This step ensures reduced memory usage and computational efficiency while maintaining performance.
# Quantize and visualize weights
weights_abs_quant, _ = absmax_quantize(weights)
weights_zp_quant, _ = zeropoint_quantize(weights)
# Quantize the entire model
model_abs = deepcopy(model)
model_zp = deepcopy(model)
for param in model_abs.parameters():
_, dequantized = absmax_quantize(param.data)
param.data = dequantized
for param in model_zp.parameters():
_, dequantized = zeropoint_quantize(param.data)
param.data = dequantizedViewing quantified weight distributions
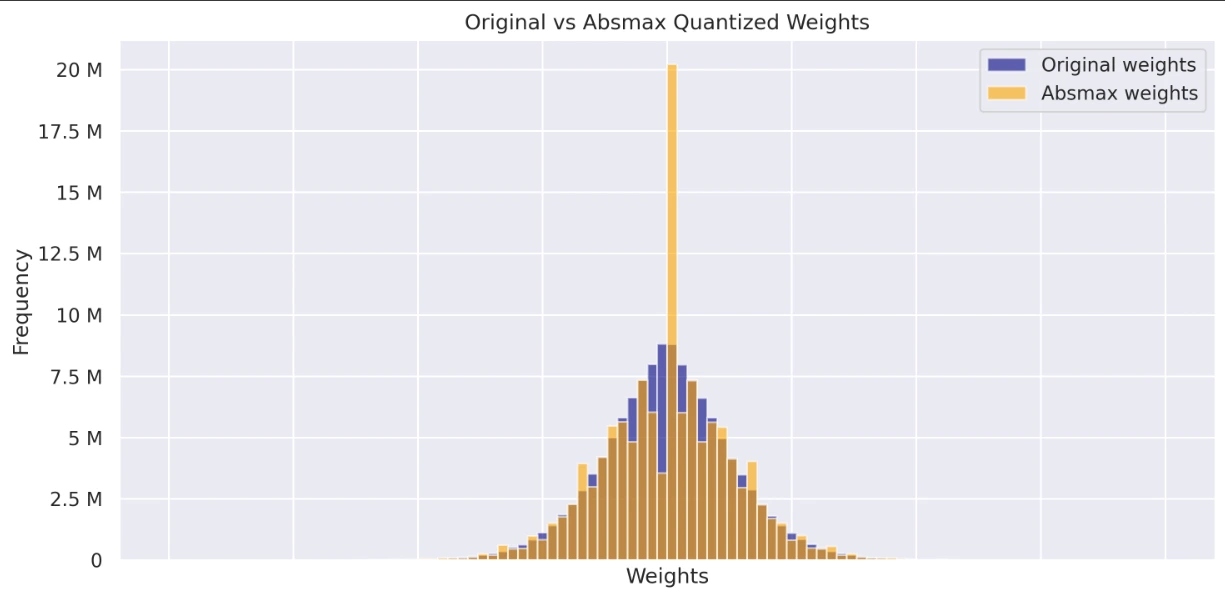
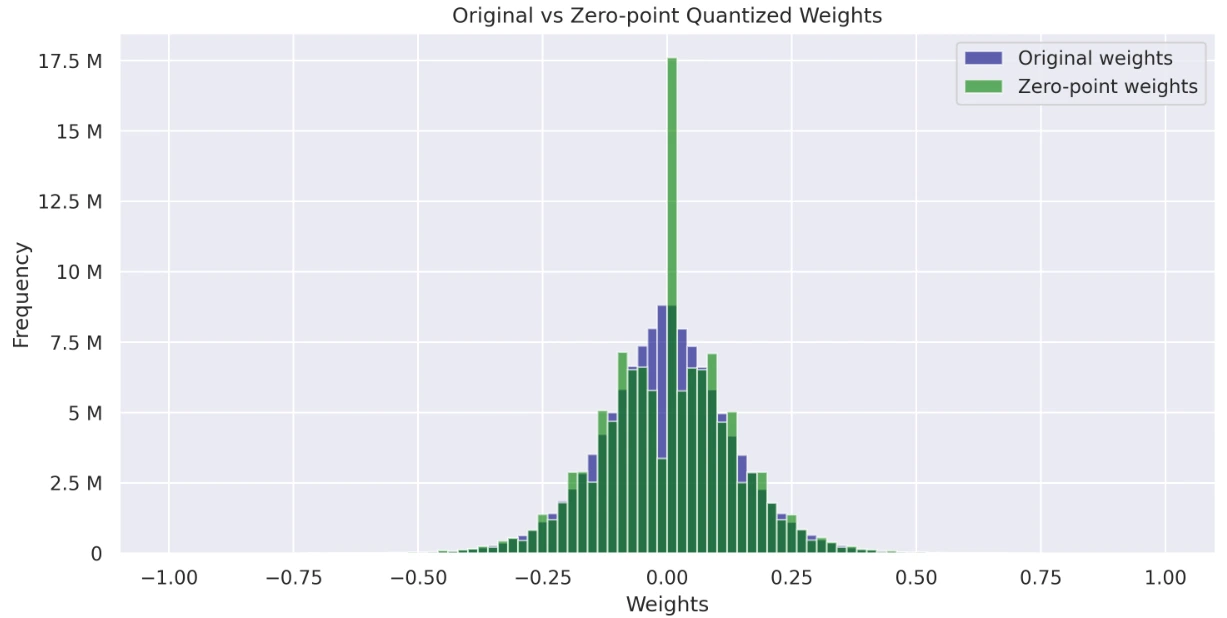
View and compare the weight distributions of the original, ABSMAX quantized, and zero-point models. These histograms provide information about how quantization affects the weight values and their overall distribution.
# Visualize histograms of weights
def visualize_histograms(original_weights, absmax_weights, zp_weights):
sns.set_theme(style="darkgrid")
fig, axs = plt.subplots(2, figsize=(10, 10), dpi=300, sharex=True)
axs(0).hist(original_weights, bins=100, alpha=0.6, label="Original weights", color="navy", range=(-1, 1))
axs(0).hist(absmax_weights, bins=100, alpha=0.6, label="Absmax weights", color="orange", range=(-1, 1))
axs(1).hist(original_weights, bins=100, alpha=0.6, label="Original weights", color="navy", range=(-1, 1))
axs(1).hist(zp_weights, bins=100, alpha=0.6, label="Zero-point weights", color="green", range=(-1, 1))
for ax in axs:
ax.legend()
ax.set_xlabel('Weights')
ax.set_ylabel('Frequency')
ax.yaxis.set_major_formatter(ticker.EngFormatter())
axs(0).set_title('Original vs Absmax Quantized Weights')
axs(1).set_title('Original vs Zero-point Quantized Weights')
plt.tight_layout()
plt.show()
# Flatten weights for visualization
original_weights = np.concatenate((param.data.cpu().numpy().flatten() for param in model.parameters()))
absmax_weights = np.concatenate((param.data.cpu().numpy().flatten() for param in model_abs.parameters()))
zp_weights = np.concatenate((param.data.cpu().numpy().flatten() for param in model_zp.parameters()))
visualize_histograms(original_weights, absmax_weights, zp_weights)The code includes a comprehensive display function:
- Chart showing original weights vs. ABSMAX weights
- Chart showing original weights vs. zero point weights
Production:
Performance evaluation
Evaluating the impact of quantization on model performance is essential to ensure efficiency and accuracy. We measure how well the quantized models perform compared to the original.
Text generation
Explore how quantized models generate text and compare the quality of the outputs to the original model predictions.
def generate_text(model, input_text, max_length=50):
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
output = model.generate(inputs=input_ids,
max_length=max_length,
do_sample=True,
top_k=30,
pad_token_id=tokenizer.eos_token_id,
attention_mask=input_ids.new_ones(input_ids.shape))
return tokenizer.decode(output(0), skip_special_tokens=True)
# Generate text with original and quantized models
original_text = generate_text(model, "The future of ai is")
absmax_text = generate_text(model_abs, "The future of ai is")
zp_text = generate_text(model_zp, "The future of ai is")
print(f"Original model:\n{original_text}")
print("-" * 50)
print(f"Absmax model:\n{absmax_text}")
print("-" * 50)
print(f"Zeropoint model:\n{zp_text}")This code compares text generation outputs from three models: the original, a quantized “ABSMAX” model, and a quantized “ZeroPoint” model. It uses a Generate_Text function to generate text based on an input indicator, sampling with a Top-K value of 30. Finally, it prints the results of all three models.
Production:

# Perplexity evaluation
def calculate_perplexity(model, text):
encodings = tokenizer(text, return_tensors="pt").to(device)
input_ids = encodings.input_ids
with torch.no_grad():
outputs = model(input_ids, labels=input_ids)
return torch.exp(outputs.loss)
long_text = "artificial intelligence is a transformative technology that is reshaping industries."
ppl_original = calculate_perplexity(model, long_text)
ppl_absmax = calculate_perplexity(model_abs, long_text)
ppl_zp = calculate_perplexity(model_zp, long_text)
print(f"\nPerplexity (Original): {ppl_original.item():.2f}")
print(f"Perplexity (Absmax): {ppl_absmax.item():.2f}")
print(f"Perplexity (Zero-point): {ppl_zp.item():.2f}")The code calculates perplexity (a measure of how well a model predicts text) for a given input using three models: the original models, quantized “ABSMAX”, and quantized “ZeroPoint”. Less perplexity indicates better performance. Prints the perplexity scores for comparison.
Production:

You can access the Colab link here.
Advantages of weight quantification
Next we will analyze the advantages of weight quantization:
- Memory efficiency: Quantization reduces model size by up to 75%, allowing for faster loading and inference.
- Faster inference: Integer operations are faster than floating point operations, leading to faster model execution.
- Lower energy consumption: Reduced memory bandwidth and simplified computation lead to power savings, essential for edge devices and mobile deployment.
- Implementation Flexibility: Smaller models are easier to implement on resource-constrained hardware (e.g., mobile phones, embedded devices).
- Minimum performance degradation: With the right quantization strategy, models can retain most of their accuracy despite reduced precision.
Conclusion
Weight quantization plays a crucial role in improving the efficiency of large language models, particularly when it comes to deploying them on resource-constrained devices. By converting high-precision weights into lower-precision integer representations, we can significantly reduce memory usage, improve inference speed, and lower power consumption, all without severely impacting model performance.
In this guide, we explore two popular quantization techniques, Absmax quantization and zero-point quantization, using GPT-2 as a practical example. Both techniques demonstrated the ability to reduce the model's memory footprint and computational requirements while maintaining a high level of accuracy in text generation tasks. However, the zero-point quantization method, with its asymmetric approach, generally resulted in better preservation of model accuracy, especially for non-symmetric weight distributions.
key control
- ABSMAX quantization is simpler and works well for symmetric weight distributions, although it may not capture asymmetric distributions as effectively as zero-point quantization.
- Zero-point quantization offers a more flexible approach by introducing an offset to handle skewed distributions, often leading to better precision and more efficient representation of weights.
- Quantization is essential for implementing large models in real-time applications where computational resources are limited.
- Although the quantization process reduces the precision, it is possible to keep the model performance close to the original with appropriate tuning and quantization strategies.
- Visualization techniques such as histograms can provide information about how quantization affects the model weights and the distribution of values in the tensors.
Frequently asked questions
A. Weight quantization reduces the precision of a model's weights, typically from 32-bit floating point values to lower precision integers (e.g., 8-bit integers), to save memory and computation while maintaining the performance.
A. While quantization reduces model memory footprint and inference time, it can lead to a slight degradation in accuracy. However, if done correctly, the loss of accuracy is minimal.
A. Yes, quantization can be applied to any neural network model, including language models, vision models, and other deep learning architectures.
A. You can implement quantization by creating functions to scale and round the model weights, then apply them across all parameters. Libraries such as Pytorch provide native support for some quantization techniques, although custom implementations, as shown in the guide, offer flexibility.
A. Weight quantization is most effective for large models where reducing memory and compute footprint is critical. However, very small models may not benefit as much from quantization.
The media shown in this article is not the property of Analytics Vidhya and is used at the author's discretion.

My name is Nilesh Dwivedi, and I am excited to join this vibrant community of bloggers and readers. I am currently in my first year of BTech, specializing in Data Science and artificial intelligence at IIIT Dharwad. I am passionate about technology and data science and hope to write more blogs.
(Tagstotranslate) Blogathon




