 NEWSLETTER
NEWSLETTER
Language models (LMs) face significant challenges related to privacy and copyright because they are trained on large amounts of text data. The inadvertent inclusion of private and copyrighted content in training datasets has raised legal and ethical issues, including copyright lawsuits and compliance requirements with regulations such as the GDPR. Data owners are increasingly demanding the removal of their data from trained models, highlighting the need for effective machine unlearning techniques. These advances have spurred research into methods that can transform existing trained models to behave as if they had never been exposed to certain data, while maintaining overall performance and efficiency.
Researchers have repeatedly attempted to address the challenges posed by machine unlearning in language models. Exact unlearning methods, which aim to make the unlearned model identical to a retrained model without the forgotten data, have been developed for simple models such as text modeling machines and naive Bayesian classifiers. However, these approaches are computationally infeasible for modern large language models.
Approximate unlearning methods have emerged as more practical alternatives. These include parameter optimization techniques such as gradient ascent, location-based unlearning that focuses on specific model units, and context-based unlearning that modifies model outputs using external knowledge. Researchers have also explored the application of unlearning to specific downstream tasks and to eliminate deleterious behaviors in language models.
Evaluation methods for machine unlearning in language models have primarily focused on specific tasks, such as question answering or sentence completion. Metrics such as familiarity scores and comparisons with retrained models have been used to assess the effectiveness of unlearning. However, existing evaluations often lack comprehensiveness and do not adequately address real-world deployment considerations such as scalability and sequential unlearning requests.
Researchers from the University of Washington, Princeton University, the University of Southern California, the University of Chicago, and Google Research present MUSE (Machine Unlearning Six-Way Evaluation), a comprehensive framework designed to evaluate the effectiveness of machine unlearning algorithms for language models. This systematic approach evaluates six critical properties that address data owners’ and model implementers’ requirements for practical unlearning. MUSE examines the ability of unlearning algorithms to eliminate word-by-word memorization, knowledge memorization, and privacy leakage, while assessing their ability to preserve utility, scale effectively, and maintain performance across multiple unlearning requests. By applying this framework to evaluate eight representative machine unlearning algorithms on datasets focused on unlearning Harry Potter books and news articles, MUSE provides a holistic view of the current state and limitations of unlearning techniques in real-world scenarios.
MUSE proposes a comprehensive set of evaluation metrics that address the expectations of both the data owner and the model implementer regarding machine unlearning in language models. The framework consists of six key criteria:
Data Owner Expectations:
1. Without word-by-word memorization: This is measured by telling the model the beginning of a sequence from the forgotten set and comparing the model's continuation to the true continuation using the ROUGE-L F1 score.
2. Without knowledge memorization: This is assessed by testing the model's ability to answer questions derived from the forget set, using ROUGE scores to compare the answers generated by the model with the true answers.
3. No privacy leaks: It was evaluated using a membership inference attack (MIA) method to detect whether the model retains information indicating that the forgotten set was part of the training data.
Model implementer expectations:
4. Utility preservation: It is measured by evaluating the performance of the model on the retention set using the knowledge memorization metric.
5. Scalability: It is evaluated by examining the performance of the model on forgotten sets of different sizes.
6. Sustainability: It is analyzed by monitoring the model performance over sequential unlearning requests.
MUSE evaluates these metrics on two representative datasets: NEWS (BBC news articles) and BOOKS (Harry Potter series), providing a realistic testbed for evaluating unlearning algorithms in practical scenarios.
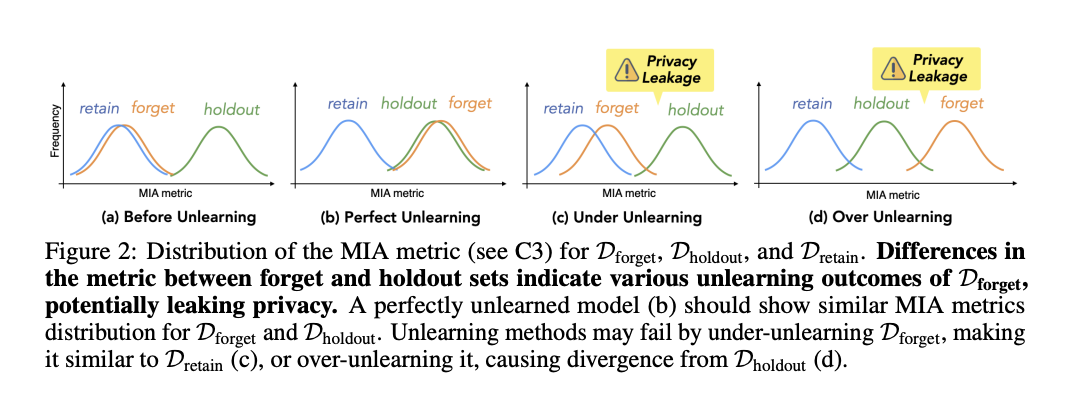
The evaluation of eight unlearning methods from the MUSE framework revealed significant challenges in machine unlearning for language models. While most methods effectively eliminated word and knowledge memorization, they struggled with privacy leakage, often with insufficient or excessive unlearning. All methods significantly degraded model utility, with some models becoming unusable. Scalability issues arose as forgotten set sizes increased, and sustainability proved problematic with sequential unlearning requests, leading to progressive performance degradation. These findings underscore significant drawbacks and limitations of current unlearning techniques, highlighting the pressing need for more effective and balanced approaches to meet the expectations of both the data owner and the implementer.
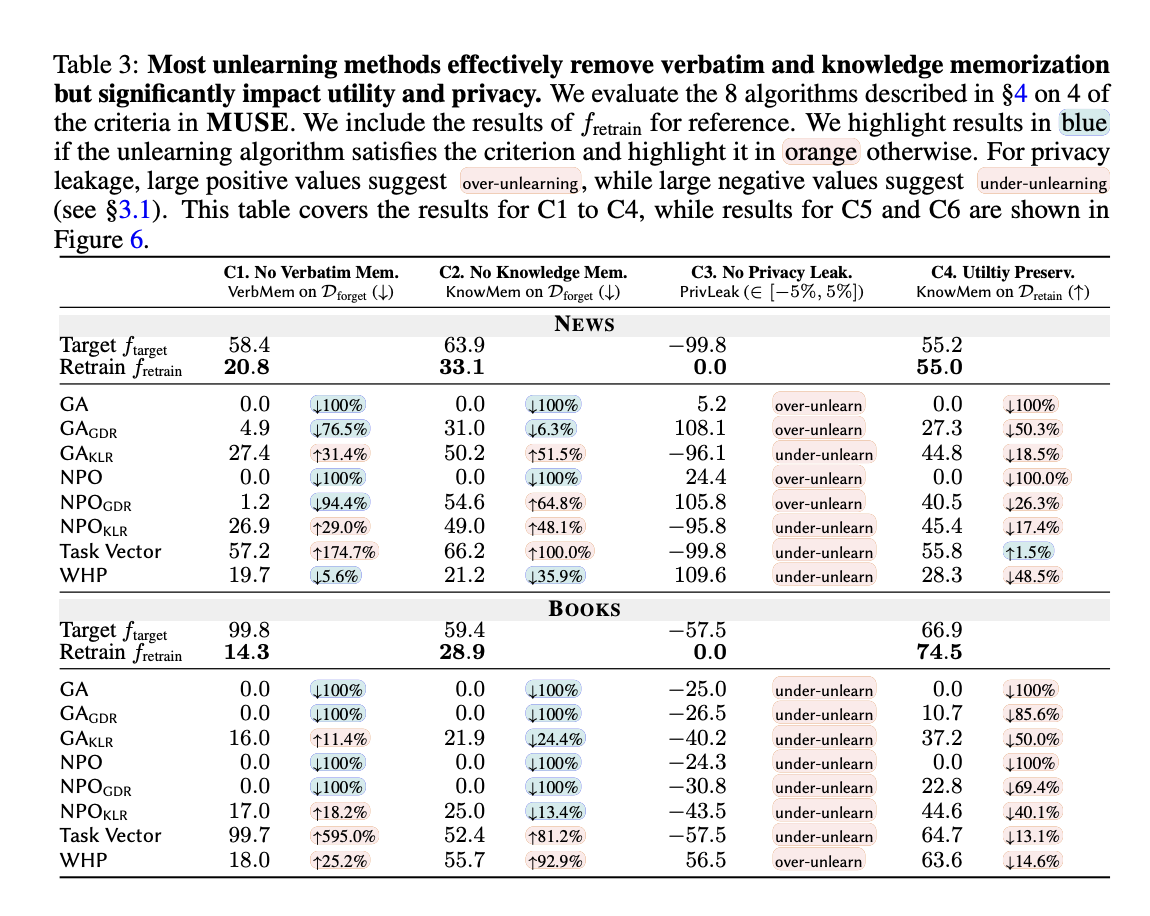
This research presents MUSEa comprehensive machine unlearning evaluation benchmark, assesses six key properties that are crucial for both data owners and model implementers. The evaluation reveals that while current unlearning methods effectively prevent content memorization, they do so at a substantial cost to model utility on the retained data. Furthermore, these methods often result in significant privacy leakage and suffer from scalability and sustainability issues when handling large-scale content removal or successive unlearning requests. These findings underscore the limitations of existing approaches and emphasize the urgent need to develop more robust and balanced machine unlearning techniques that can better address the complex requirements of real-world applications.
Review the Paper and Project. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Subreddit with over 46 billion users
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}