 NEWSLETTER
NEWSLETTER
Los juegos en línea y las comunidades sociales ofrecen funciones de chat de voz y texto para que sus usuarios se comuniquen. Aunque los chats de voz y texto a menudo favorecen las bromas amistosas, también pueden generar problemas como incitación al odio, acoso cibernético, acoso y estafas. Hoy en día, muchas empresas dependen únicamente de moderadores humanos para revisar el contenido tóxico. Sin embargo, verificar las infracciones en el chat requiere mucho tiempo, es propenso a errores y su escalabilidad es difícil.
En esta publicación, presentamos soluciones que permiten la moderación de chats de audio y texto mediante varios servicios de AWS, incluidos Amazon Transcribe, Amazon Comprehend, Amazon Bedrock y Amazon OpenSearch Service.
Las plataformas sociales buscan una solución de moderación lista para usar que sea sencilla de iniciar, pero también requieren personalización para gestionar diversas políticas. La latencia y el costo también son factores críticos que deben tenerse en cuenta. Al orquestar la clasificación de la toxicidad con modelos de lenguaje grandes (LLM) utilizando IA generativa, ofrecemos una solución que equilibra la simplicidad, la latencia, el costo y la flexibilidad para satisfacer diversos requisitos.
El código de muestra para esta publicación está disponible en el repositorio de GitHub.
Flujo de trabajo de moderación del chat de audio
Un flujo de trabajo de moderación de chat de audio podría iniciarse cuando un usuario denuncia a otros usuarios en una plataforma de juegos por violaciones de políticas como malas palabras, incitación al odio o acoso. Esto representa un enfoque pasivo para la moderación de audio. El sistema graba todas las conversaciones de audio sin un análisis inmediato. Cuando se recibe un informe, el flujo de trabajo recupera los archivos de audio relacionados e inicia el proceso de análisis. Luego, un moderador humano revisa la conversación reportada e investiga su contenido para determinar si viola la política de la plataforma.
Alternativamente, el flujo de trabajo podría activarse de forma proactiva. Por ejemplo, en una sala de chat de audio social, el sistema podría grabar todas las conversaciones y aplicar análisis.
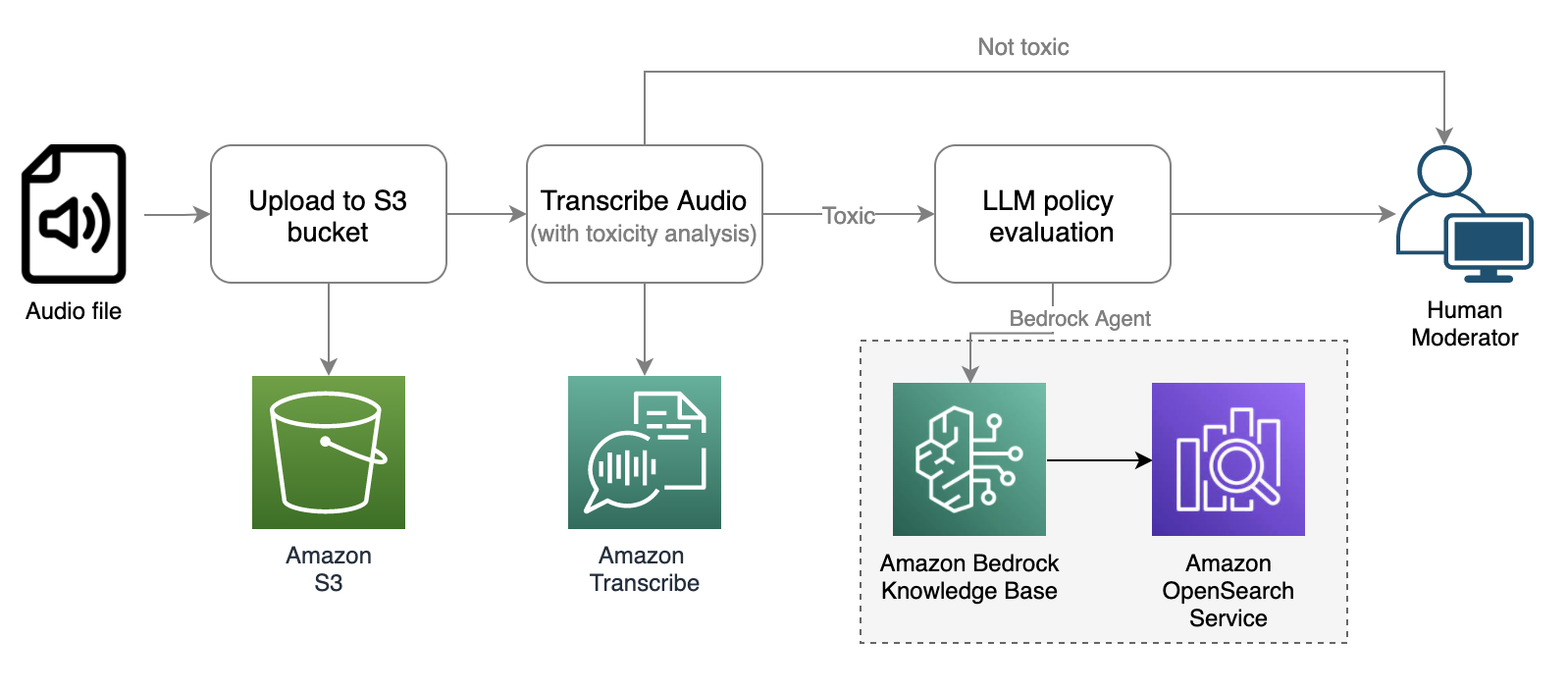
Tanto los enfoques pasivos como los proactivos pueden desencadenar el siguiente proceso de análisis de audio.
El flujo de trabajo de moderación de audio implica los siguientes pasos:
- El flujo de trabajo comienza con la recepción del archivo de audio y su almacenamiento en un depósito de Amazon Simple Storage Service (Amazon S3) para que Amazon Transcribe pueda acceder a él.
- La Amazonia Transcribe
StartTranscriptionJobLa API se invoca con la detección de toxicidad habilitada. Amazon Transcribe convierte el audio en texto y proporciona información adicional sobre el análisis de toxicidad. Para obtener más información sobre el análisis de toxicidad, consulte Marcar lenguaje dañino en conversaciones habladas con Amazon Transcribe ToxicityDetection. - Si el análisis de toxicidad arroja una puntuación de toxicidad que excede un cierto umbral (por ejemplo, 50%), podemos utilizar las bases de conocimiento de Amazon Bedrock para evaluar el mensaje con respecto a políticas personalizadas mediante LLM.
- El moderador humano recibe un informe detallado de moderación de audio que destaca los segmentos de conversación considerados tóxicos y que violan la política, lo que le permite tomar una decisión informada.
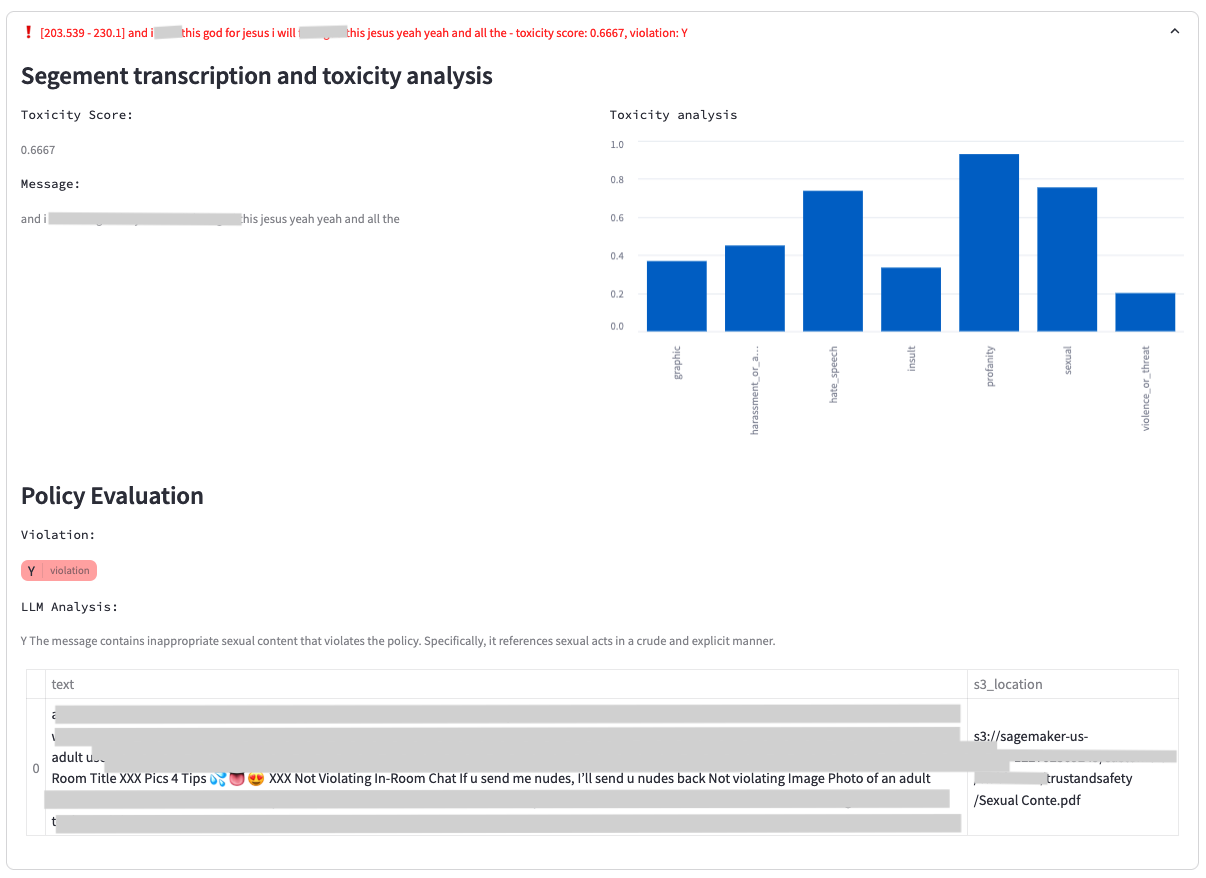
La siguiente captura de pantalla muestra una aplicación de ejemplo que muestra un análisis de toxicidad para un segmento de audio. Incluye la transcripción original, los resultados del análisis de toxicidad de Amazon Transcribe y el análisis realizado utilizando una base de conocimientos de Amazon Bedrock a través del modelo Amazon Bedrock Anthropic Claude V2.
El análisis LLM proporciona un resultado de infracción (S o N) y explica el fundamento detrás de la decisión del modelo con respecto a la infracción de la política. Además, la base de conocimientos incluye los documentos de políticas a los que se hace referencia y utilizados en la evaluación, lo que proporciona a los moderadores un contexto adicional.
Detección de toxicidad de Amazon Transcribe
Amazon Transcribe es un servicio de reconocimiento automático de voz (ASR) que facilita a los desarrolladores agregar capacidad de conversión de voz a texto a sus aplicaciones. El flujo de trabajo de moderación de audio utiliza la detección de toxicidad de Amazon Transcribe, que es una capacidad impulsada por el aprendizaje automático (ML) que utiliza señales basadas en audio y texto para identificar y clasificar contenido tóxico basado en voz en siete categorías, incluido el acoso sexual, el discurso de odio y las amenazas. , abuso, malas palabras, insultos y lenguaje gráfico. Además de analizar el texto, la detección de toxicidad utiliza señales del habla, como tonos y tono, para identificar intenciones tóxicas en el habla.
El flujo de trabajo de moderación de audio activa la evaluación de políticas del LLM solo cuando el análisis de toxicidad excede un umbral establecido. Este enfoque reduce la latencia y optimiza los costos mediante la aplicación selectiva de LLM, filtrando una parte importante del tráfico.
Utilice la ingeniería rápida de LLM para adaptarse a políticas personalizadas
Los modelos de detección de toxicidad previamente entrenados de Amazon Transcribe y Amazon Comprehend proporcionan una taxonomía de toxicidad amplia, comúnmente utilizada por las plataformas sociales para moderar el contenido generado por el usuario en formatos de audio y texto. Aunque estos modelos previamente entrenados detectan eficientemente problemas con baja latencia, es posible que necesite una solución para detectar infracciones de las políticas específicas de su empresa o dominio comercial, algo que los modelos previamente entrenados por sí solos no pueden lograr.
Además, detectar violaciones en conversaciones contextuales, como identificar aseo sexual infantil conversaciones, requiere una solución personalizable que implica considerar los mensajes del chat y el contexto fuera de él, como la edad, el sexo y el historial de conversaciones del usuario. Aquí es donde los LLM pueden ofrecer la flexibilidad necesaria para ampliar estos requisitos.
Amazon Bedrock es un servicio totalmente administrado que ofrece una selección de modelos básicos (FM) de alto rendimiento de empresas líderes en inteligencia artificial. Estas soluciones utilizan Anthropic Claude v2 de Amazon Bedrock para moderar transcripciones de audio y mensajes de chat de texto mediante una plantilla de mensajes flexible, como se describe en el siguiente código:
La plantilla contiene marcadores de posición para la descripción de la política, el mensaje de chat y reglas adicionales que requieren moderación. El modelo Anthropic Claude V2 ofrece respuestas en el formato indicado (S o N), junto con un análisis que explica por qué cree que el mensaje viola la política. Este enfoque le permite definir categorías de moderación flexibles y articular sus políticas en lenguaje humano.
El método tradicional de entrenar un modelo de clasificación interno implica procesos engorrosos, como anotación de datos, capacitación, pruebas e implementación de modelos, que requieren la experiencia de científicos de datos e ingenieros de ML. Los LLM, por el contrario, ofrecen un alto grado de flexibilidad. Los usuarios empresariales pueden modificar las indicaciones en lenguaje humano, lo que mejora la eficiencia y reduce los ciclos de iteración en el entrenamiento del modelo ML.
Bases de conocimiento de Amazon Bedrock
Aunque la ingeniería rápida es eficiente para personalizar políticas, inyectar políticas y reglas extensas directamente en las indicaciones de LLM para cada mensaje puede introducir latencia y aumentar el costo. Para abordar esto, utilizamos las bases de conocimiento de Amazon Bedrock como un sistema administrado de generación aumentada de recuperación (RAG). Esto le permite administrar el documento de política de manera flexible, permitiendo que el flujo de trabajo recupere solo los segmentos de política relevantes para cada mensaje de entrada. Esto minimiza la cantidad de tokens enviados a los LLM para su análisis.
Puede utilizar la Consola de administración de AWS para cargar los documentos de políticas en un depósito de S3 y luego indexar los documentos en una base de datos vectorial para una recuperación eficiente. El siguiente es un flujo de trabajo conceptual administrado por una base de conocimientos de Amazon Bedrock que recupera documentos de Amazon S3, divide el texto en fragmentos e invoca el modelo de incrustaciones de texto Titan de Amazon Bedrock para convertir los fragmentos de texto en vectores, que luego se almacenan en el vector. base de datos.
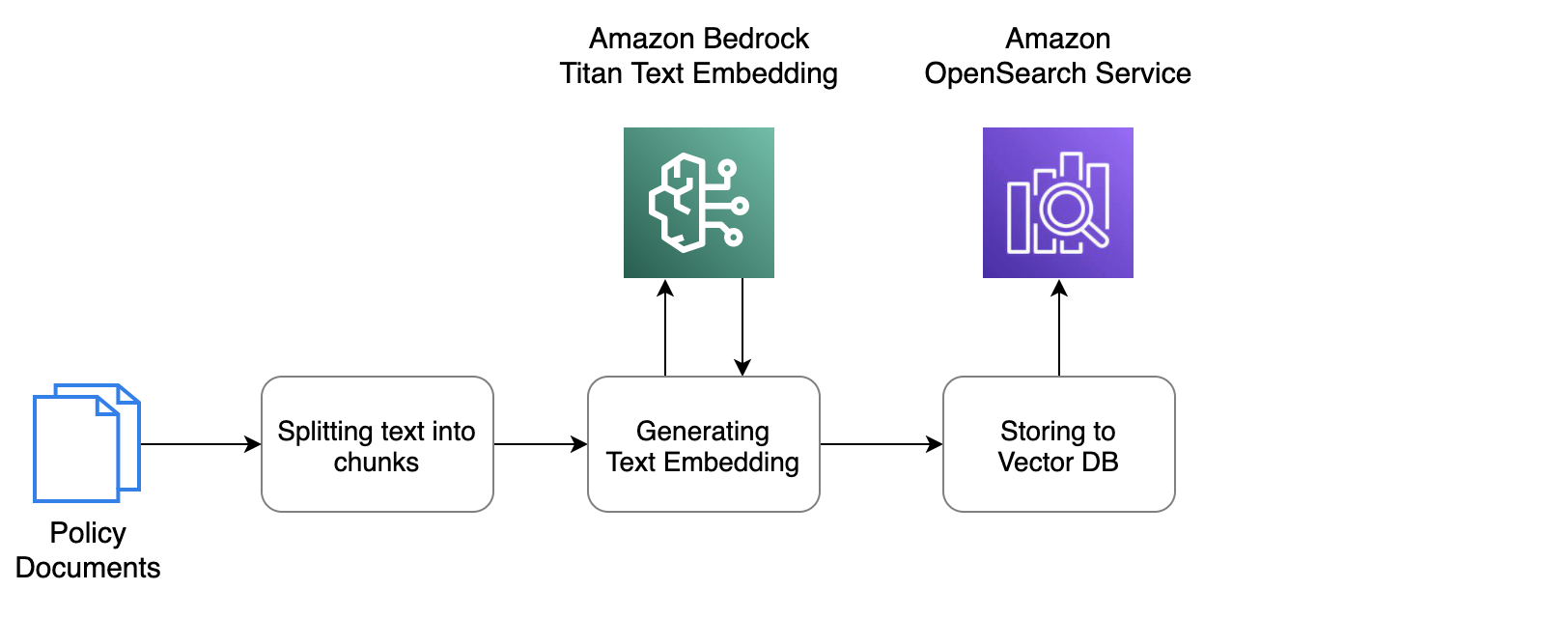
En esta solución, utilizamos Amazon OpenSearch Service como almacén de vectores. Abrir búsqueda es un paquete de software de código abierto escalable, flexible y extensible para aplicaciones de búsqueda, análisis, monitoreo de seguridad y observabilidad, con licencia Apache 2.0. OpenSearch Service es un servicio totalmente administrado que simplifica la implementación, escala y operación de OpenSearch en la nube de AWS.
Una vez indexado el documento en OpenSearch Service, el flujo de trabajo de moderación de audio y texto envía mensajes de chat, lo que activa el siguiente flujo de consulta para una evaluación de políticas personalizada.
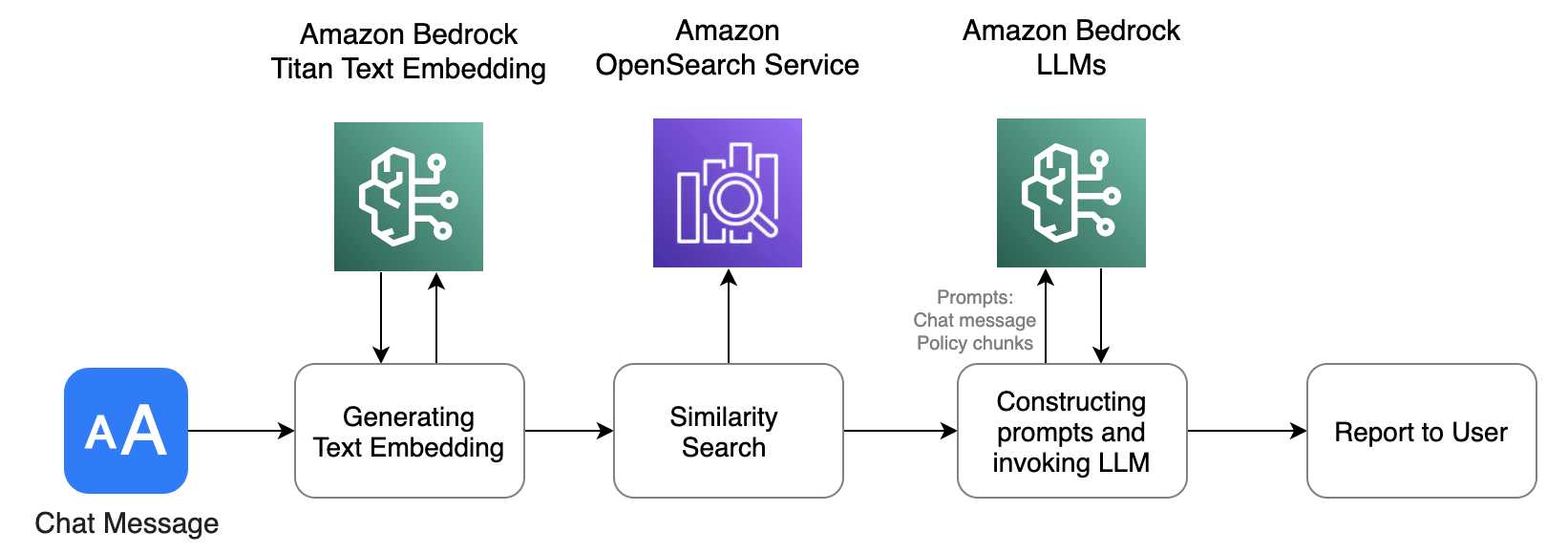
El proceso es similar al flujo de trabajo de iniciación. Primero, el mensaje de texto se convierte en incrustaciones de texto mediante la API de incrustación de texto Titan de Amazon Bedrock. Estas incrustaciones se utilizan luego para realizar una búsqueda vectorial en la base de datos del servicio OpenSearch, que ya se ha completado con incrustaciones de documentos. La base de datos devuelve fragmentos de políticas con la puntuación de coincidencia más alta, relevantes para el mensaje de texto de entrada. Luego redactamos mensajes que contienen tanto el mensaje de chat de entrada como el segmento de política, que se envían a Anthropic Claude V2 para su evaluación. El modelo LLM devuelve un resultado de análisis basado en las instrucciones solicitadas.
Para obtener instrucciones detalladas sobre cómo crear una nueva instancia con su documento de política en una base de conocimientos de Amazon Bedrock, consulte Bases de conocimientos que ahora ofrecen una experiencia RAG totalmente administrada en Amazon Bedrock.
Flujo de trabajo de moderación de chat de texto
El flujo de trabajo de moderación del chat de texto sigue un patrón similar al de la moderación de audio, pero utiliza el análisis de toxicidad de Amazon Comprehend, que está diseñado para la moderación de texto. La aplicación de muestra admite una interfaz para cargar archivos de texto masivos en formato CSV o TXT y proporciona una interfaz de mensaje único para pruebas rápidas. El siguiente diagrama ilustra el flujo de trabajo.
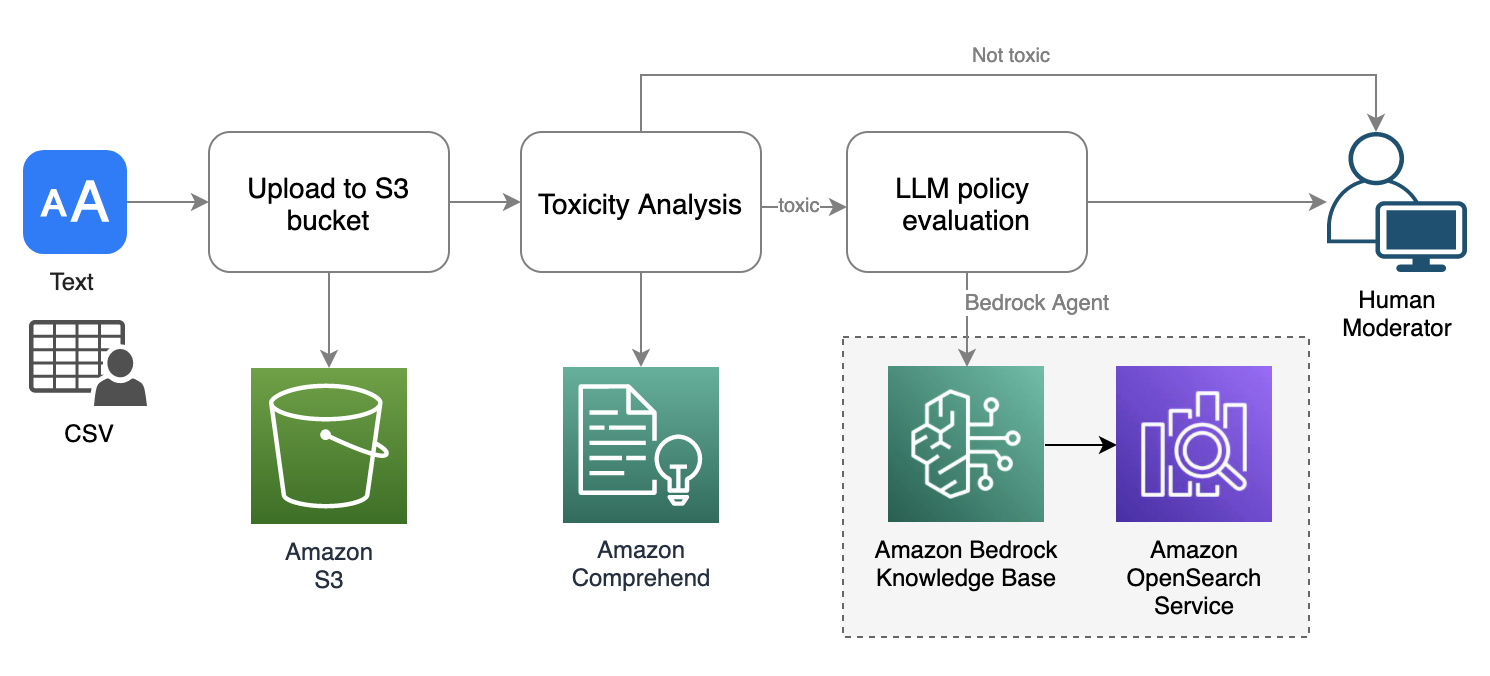
El flujo de trabajo de moderación de texto implica los siguientes pasos:
- El usuario carga un archivo de texto en un depósito de S3.
- El análisis de toxicidad de Amazon Comprehend se aplica al mensaje de texto.
- Si el análisis de toxicidad arroja una puntuación de toxicidad que excede un cierto umbral (por ejemplo, 50%), utilizamos una base de conocimientos de Amazon Bedrock para evaluar el mensaje con respecto a políticas personalizadas utilizando Anthropic Claude V2 LLM.
- Se envía un informe de evaluación de políticas al moderador humano.
Amazon Comprender el análisis de toxicidad
En el flujo de trabajo de moderación de texto, utilizamos el análisis de toxicidad de Amazon Comprehend para evaluar el nivel de toxicidad de los mensajes de texto. Amazon Comprehend es un servicio de procesamiento de lenguaje natural (NLP) que utiliza ML para descubrir información y conexiones valiosas en el texto. La API de detección de toxicidad de Amazon Comprehend asigna una puntuación de toxicidad general al contenido de texto, que oscila entre 0 y 1, lo que indica la probabilidad de que sea tóxico. También clasifica el texto en las siguientes categorías y proporciona una puntuación de confianza para cada una: hate_speechgráfico, harrassement_or_abusesexuales, violence_or_threatinsultos y malas palabras.
En este flujo de trabajo de moderación de texto, el análisis de toxicidad de Amazon Comprehend desempeña un papel crucial a la hora de identificar si el mensaje de texto entrante contiene contenido tóxico. De manera similar al flujo de trabajo de moderación de audio, incluye una condición para activar la evaluación de la política LLM posterior solo cuando el análisis de toxicidad arroja una puntuación que excede un umbral predefinido. Esta optimización ayuda a reducir la latencia general y el costo asociado con el análisis LLM.
Resumen
En esta publicación, presentamos soluciones para la moderación de chats de audio y texto utilizando servicios de AWS, incluidos Amazon Transcribe, Amazon Comprehend, Amazon Bedrock y OpenSearch Service. Estas soluciones utilizan modelos previamente entrenados para el análisis de toxicidad y están orquestadas con LLM de IA generativa para lograr el equilibrio óptimo en precisión, latencia y costo. También le permiten definir con flexibilidad sus propias políticas.
Puede experimentar la aplicación de muestra siguiendo las instrucciones en la repositorio de GitHub.
Sobre el Autor
 Lana Zhang es arquitecto de soluciones senior en el equipo de servicios de inteligencia artificial de AWS WWSO, y se especializa en inteligencia artificial y aprendizaje automático para moderación de contenido, visión por computadora, procesamiento del lenguaje natural e inteligencia artificial generativa. Con su experiencia, se dedica a promover las soluciones de IA/ML de AWS y a ayudar a los clientes a transformar sus soluciones comerciales en diversas industrias, incluidas las redes sociales, los juegos, el comercio electrónico, los medios, la publicidad y el marketing.
Lana Zhang es arquitecto de soluciones senior en el equipo de servicios de inteligencia artificial de AWS WWSO, y se especializa en inteligencia artificial y aprendizaje automático para moderación de contenido, visión por computadora, procesamiento del lenguaje natural e inteligencia artificial generativa. Con su experiencia, se dedica a promover las soluciones de IA/ML de AWS y a ayudar a los clientes a transformar sus soluciones comerciales en diversas industrias, incluidas las redes sociales, los juegos, el comercio electrónico, los medios, la publicidad y el marketing.





{kind=link}