 NEWSLETTER
NEWSLETTER
Introducción
En el dinámico mundo del desarrollo de software, la eficiencia y la precisión son de suma importancia. Las herramientas avanzadas que mejoran estos aspectos pueden transformar significativamente la forma en que los desarrolladores crean y mantienen el software. La mayoría de las tecnologías actuales admiten la codificación aprovechando el poder de la inteligencia artificial (IA). Mejoran activamente el proceso de codificación al automatizar tareas rutinarias, optimizar el código e identificar y resolver errores rápidamente. La última de estas innovaciones son los modelos Granite Code de IBM. Estos modelos básicos de código abierto se centran en proporcionar soluciones prácticas para optimizar el desarrollo de código en varias plataformas. Este artículo explora la arquitectura, el desarrollo y las capacidades de los modelos Granite Code de IBM.
¿Qué son los modelos de código de granito?
Los modelos de código Granite de IBM son una serie notable de modelos básicos abiertos diseñados para inteligencia de código. Estos modelos mejoran enormemente la productividad de los desarrolladores al automatizar tareas complejas, reducir las tasas de error y acortar los tiempos de desarrollo. Adecuados para una variedad de aplicaciones, desde dispositivos portátiles hasta sistemas empresariales extensos, los modelos de código Granite son vitales en el panorama moderno del desarrollo de software acelerado.
Arquitectura de los modelos de código Granite de IBM
La arquitectura de Granite Code Models de IBM es específicamente “sólo decodificador”, centrándose en generar o transformar texto basado en la entrada. Esta configuración destaca en tareas en las que comprender y generar código similar al humano es crucial. Como resultado, puede producir correcciones y sugerencias de código precisas y contextualmente apropiadas de manera más efectiva.
Configuraciones detalladas del modelo
IBM ofrece modelos de código Granite en una variedad de tamaños para adaptarse a diversas necesidades y entornos computacionales. Los modelos varían desde un modelo de 3 mil millones de parámetros, ideal para entornos con recursos de hardware limitados, hasta un modelo de 34 mil millones de parámetros diseñado para tareas más exigentes. Los modelos incluyen configuraciones 3B, 8B, 20B y 34B, que cubren un amplio espectro de aplicaciones, desde software en el dispositivo hasta soluciones empresariales complejas basadas en servidor.
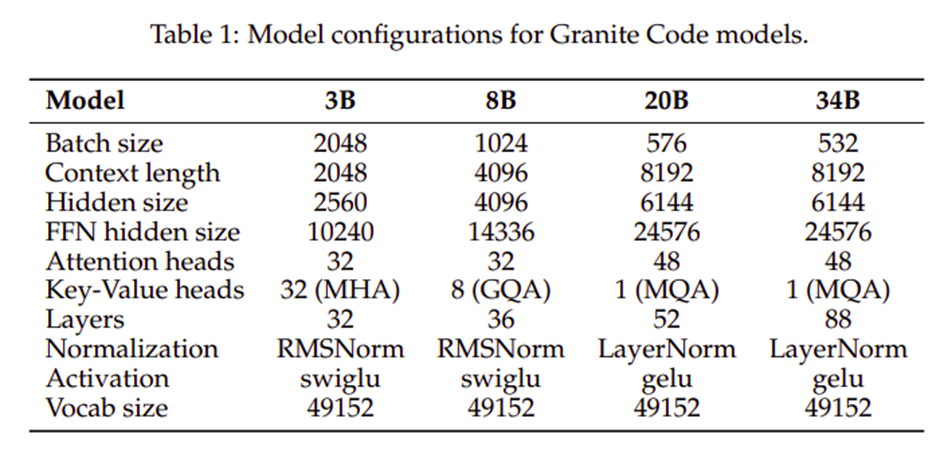
Cada modelo está diseñado para equilibrar el rendimiento con la eficiencia computacional, lo que refleja el compromiso de IBM de ofrecer herramientas de IA potentes y accesibles. Estos modelos aprovechan una arquitectura decodificadora de transformador con configuraciones específicas, como prenormalización y varios mecanismos de atención diseñados para mejorar sus capacidades generativas y su eficiencia.
Proceso de formación de modelos de código de granito
Los modelos Granite Code de IBM se benefician de un riguroso proceso de recopilación de datos, que se adhiere a estrictos estándares éticos. Inicialmente, los modelos base se entrenan en un amplio conjunto de datos que incluye de 3 a 4 billones de tokens de 116 lenguajes de programación. Esto garantiza que los modelos desarrollen una comprensión profunda de diversas sintaxis y lenguajes de programación.
La formación de estos modelos se desarrolla en dos fases estratégicas. La primera fase implica enseñar a los modelos los aspectos fundamentales de los lenguajes de programación utilizando el vasto corpus de datos de código. En la segunda fase, la capacitación implica 500 mil millones de tokens adicionales de una combinación cuidadosamente seleccionada de código de alta calidad y datos en lenguaje natural. Este enfoque mejora las capacidades de razonamiento de los modelos y su capacidad para comprender y ejecutar instrucciones complejas del desarrollador. Esta capacitación de dos fases garantiza que los modelos no solo sean competentes en la generación de código, sino que también sobresalgan en la interpretación y el seguimiento de instrucciones de programación detalladas.
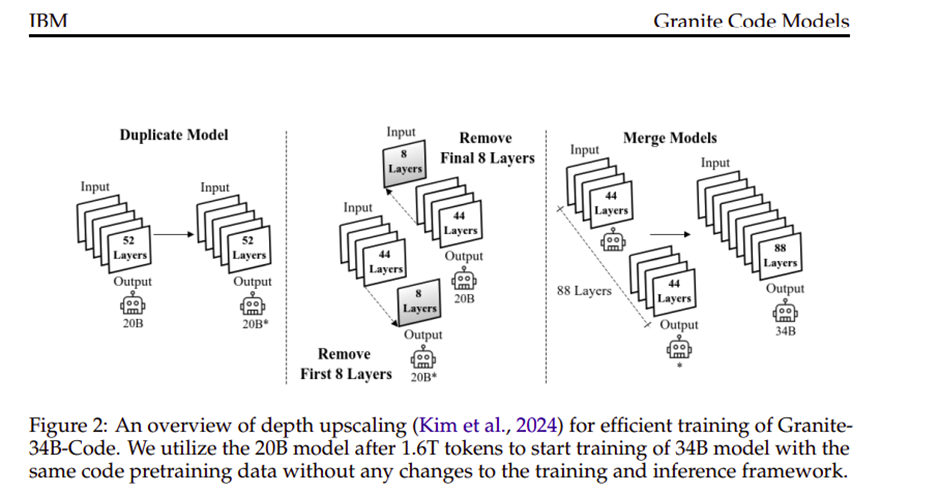
Para optimizar estos modelos, IBM ha utilizado técnicas de vanguardia, como programas de tasa de aprendizaje adaptativos y métodos sofisticados de regularización. Estas estrategias evitan el sobreajuste y garantizan que los modelos sigan siendo generalizables en diferentes entornos y tareas de codificación.
Ajuste de instrucciones y adaptabilidad del modelo
El ajuste de instrucciones mejora significativamente el rendimiento de los modelos Granite Code. Al entrenar modelos para que sigan directivas específicas, comprenden y ejecutan mejor las tareas según las instrucciones de los desarrolladores. Este ajuste alinea los resultados de los modelos más estrechamente con las expectativas del usuario, aumentando así su utilidad y precisión en aplicaciones prácticas.
Mediante el ajuste de instrucciones, los modelos de código de Granite han mostrado mejoras notables en el razonamiento y la resolución de problemas. Por ejemplo, estos modelos ahora pueden deducir de manera más efectiva los problemas subyacentes en un bloque de código y sugerir soluciones más precisas. También destacan en la generación de código que se adhiere a restricciones u objetivos determinados, lo que demuestra una comprensión más profunda de contextos de programación complejos.
Desempeño y Evaluación
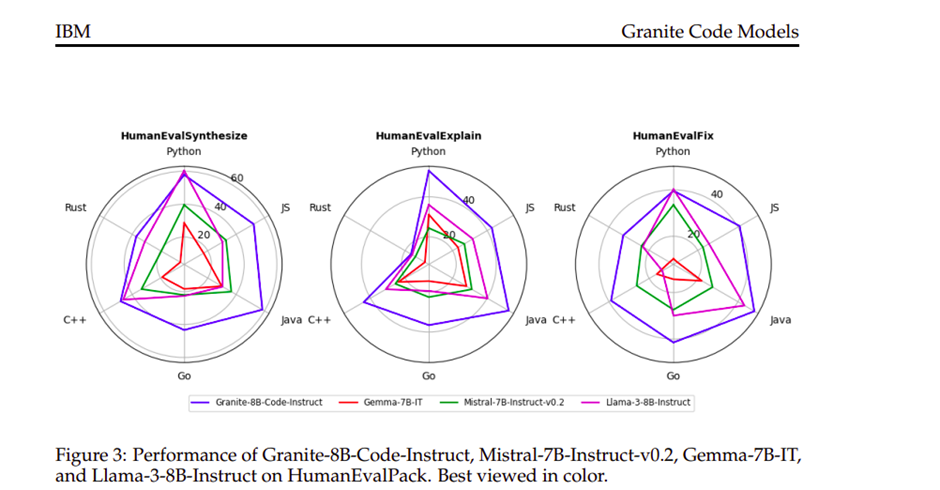
Los modelos de código de Granite son excepcionalmente expertos en el manejo de múltiples lenguajes de programación, lo que los convierte en herramientas muy versátiles para desarrolladores de todo el mundo. Ya sea Pitón, Java o lenguajes más nuevos como Go y Rust, estos modelos se adaptan y responden con gran precisión. Ayudan a completar el código, corregir errores e incluso realizar tareas complejas de refactorización de código.
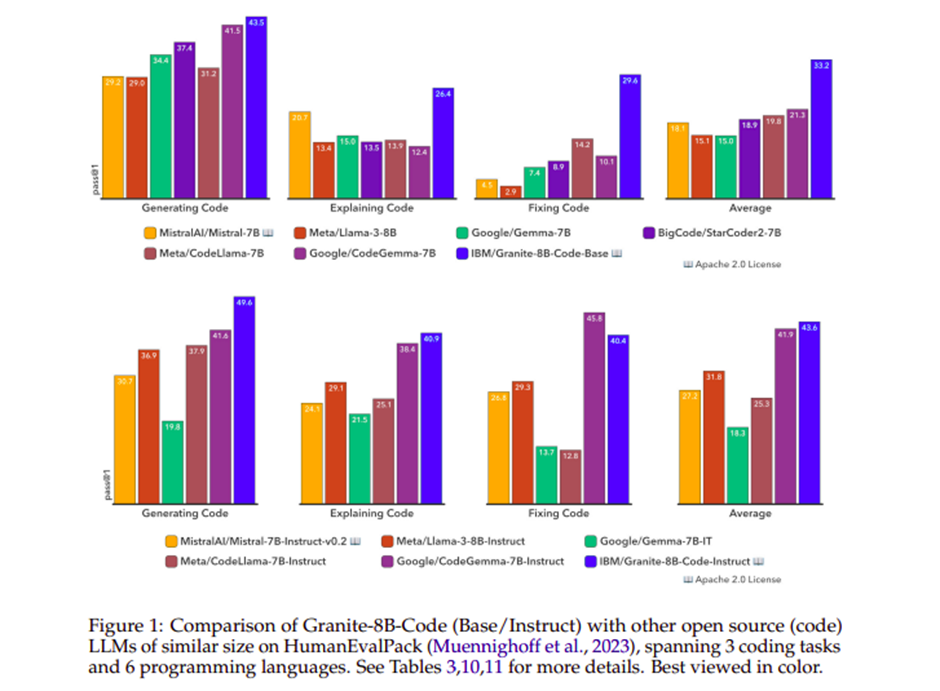
En las pruebas comparativas, los modelos de código Granite demuestran consistentemente un rendimiento superior en comparación con otros modelos líderes de inteligencia de código. Estas evaluaciones son críticas ya que verifican la efectividad de los modelos bajo diversas condiciones computacionales y específicas de la tarea. Estos modelos demuestran un rendimiento excepcional en todos los tamaños y puntos de referencia, superando con frecuencia a otros modelos de código abierto, incluso aquellos con el doble de parámetros.
Por ejemplo, el modelo Granite-8B-Code-Base supera significativamente a sus homólogos, como CodeGemma-8B, en el punto de referencia HumanEvalPack, logrando una puntuación del 33,2% en comparación con el 21,3%. Esto es particularmente digno de mención dado que se entrenó con menos tokens (4,5 billones en comparación con 7,5 billones). Además, las variantes ajustadas a las instrucciones de los modelos Granite se destacan en tareas que involucran instrucciones en lenguaje natural, ofreciendo una gama más amplia de capacidades de codificación y un rendimiento superior en tareas de generación, corrección y explicación de código.
Integración en el desarrollo de software
Los modelos de código de Granite mejoran significativamente el panorama del desarrollo de software al proporcionar herramientas sofisticadas impulsadas por IA. Estos modelos son expertos en interactuar con entornos de codificación existentes, lo que los convierte en una parte esencial de las estrategias de desarrollo modernas.
Los modelos de código de Granite agilizan varios aspectos del proceso de desarrollo de software, tales como:
- Codigo de GENERACION: Genere automáticamente código repetitivo, acelerando el desarrollo.
- Autocompletar: Sugiera fragmentos de código en tiempo real, lo que reduce el esfuerzo de escritura y minimiza los errores.
- Corrección de errores: Identificar y corregir errores en el código, mejorando la calidad del software.
- Revisión de código: Analice el código en busca de posibles mejoras, asegurándose de que se sigan las mejores prácticas.
- Documentación: Genere automáticamente comentarios y documentación, mejorando la legibilidad y el mantenimiento del código.
Accesibilidad del código abierto y contribución de la comunidad
IBM ha puesto a disposición Granite Code Models bajo una licencia Apache 2.0, lo que garantiza que sean accesibles para desarrolladores, investigadores y organizaciones de todo el mundo. Esta licencia de código abierto permite tanto el uso comercial como la modificación, lo que permite la innovación y la personalización para satisfacer diversas necesidades. Al compartir estos modelos con la comunidad de código abierto, IBM fomenta un entorno colaborativo donde las mejoras e iteraciones pueden mejorar continuamente la tecnología.
La comunidad juega un papel vital en la evolución de Granite Code Models. Los desarrolladores y entusiastas pueden contribuir probando los modelos en diferentes entornos, enviando informes de errores y proponiendo nuevas funciones. Además, los programadores pueden contribuir con código que mejore las funcionalidades del modelo o amplíe la compatibilidad con más lenguajes de programación y herramientas de desarrollo. Esta participación de la comunidad mejora los modelos y al mismo tiempo garantiza que sigan siendo relevantes y eficaces para una amplia gama de aplicaciones.
Consideraciones éticas y transparencia
Las consideraciones éticas son fundamentales para el desarrollo y la implementación de modelos de código de granito. IBM garantiza un cumplimiento riguroso de altos estándares éticos en el uso de datos, centrándose especialmente en la privacidad, la seguridad y la inclusión. Los modelos se entrenan exclusivamente con datos con licencia permisiva. Además, todos los procesos, desde la recopilación de datos hasta la capacitación de modelos, se documentan en detalle y se ponen a disposición del público, lo que garantiza la transparencia. Esta documentación incluye el origen ético de los datos, estrictos protocolos de procesamiento de datos para eliminar información confidencial y el uso de datos que respeten los derechos de privacidad.
En entornos regulados, se prioriza el uso responsable de estos modelos para garantizar que no afecten negativamente a las aplicaciones de software críticas. IBM se compromete a monitorear y actualizar continuamente los modelos para cumplir con los estándares legales y regulatorios globales. Esta vigilancia continua garantiza que, a medida que la tecnología evoluciona, lo haga de forma segura y en consonancia con las normas y expectativas de la sociedad. Esto refuerza la confianza y la confiabilidad en contextos empresariales.
Desafíos y desarrollo futuro
Si bien los modelos de código de granito son muy eficaces, enfrentan varias limitaciones y desafíos técnicos. Un problema importante es el manejo de bases de código muy grandes. Esto puede poner a prueba las capacidades de procesamiento de los modelos, especialmente a escalas más pequeñas. Además, a pesar de los avances, sigue habiendo una brecha en la comprensión profunda del contexto en comparación con los programadores humanos. Esto es especialmente evidente en escenarios complejos o llenos de matices que requieren un mayor nivel de conocimiento y creatividad.
La investigación y el desarrollo futuros de los modelos de código Granite podrían centrarse en ampliar su versatilidad lingüística para incluir lenguajes de programación menos conocidos, mejorando su utilidad. También es esencial aumentar su eficiencia con conjuntos de datos más grandes sin sacrificar el rendimiento. Se podría integrar un procesamiento avanzado del lenguaje natural para mejorar la comprensión de los modelos de las instrucciones del desarrollador para obtener resultados más precisos y relevantes.
Además, explorar las aplicaciones educativas de estos modelos podría ayudar a los nuevos programadores a dominar la codificación y la depuración. Las mejoras continuas en las técnicas de aprendizaje adaptativo permitirían a estos modelos actualizar continuamente su base de conocimientos. Esto les ayudaría a adaptarse rápidamente a los cambios en los lenguajes de programación y las tendencias de desarrollo de software.
Conclusión
Los modelos Granite Code de IBM mejoran significativamente el desarrollo de software al automatizar y optimizar las tareas de codificación a través de capacidades avanzadas de IA. Estos modelos de codificación de código abierto agilizan procesos como la generación de código, la corrección de errores y la documentación, mejorando la productividad en diversos entornos de programación.
Comprometida con el desarrollo ético de la IA, IBM garantiza la transparencia en el uso de datos y la capacitación de modelos, promoviendo un uso seguro y responsable en entornos profesionales. De cara al futuro, la investigación y la colaboración comunitaria continua perfeccionarán aún más estos modelos, ampliarán su aplicación y mantendrán su relevancia en un panorama tecnológico en rápida evolución.






{kind=link}