 NEWSLETTER
NEWSLETTER
Introducción
Si eres principiante y estás empezando a aprender MLOps, es posible que tengas una pregunta: ¿Qué son MLOps?
En palabras simples, MLOps (Machine Learning Operations) es un conjunto de prácticas para la colaboración y comunicación entre científicos de datos y profesionales de operaciones. La aplicación de estas prácticas aumenta la calidad, simplifica el proceso de gestión y automatiza el despliegue de modelos de Machine Learning y Deep Learning en entornos de producción a gran escala. Es más fácil alinear los modelos con las necesidades comerciales y los requisitos regulatorios. En este artículo, implementaremos nuestro proyecto usando Prefect y CometML.
En este proyecto MLOps, construiremos el mejor modelo de aprendizaje automático posible utilizando hiperparámetros óptimos para predecir el precio de venta de un Bulldozer. Como sabrá, una topadora es un vehículo potente para excavaciones y zanjas poco profundas.
Objetivos de aprendizaje
- Aprenda los conceptos de MLOps y el flujo de trabajo de ML de un extremo a otro.
- Implementar canalización MLOps con Prefect y CometML.
- Cree flujos de trabajo de aprendizaje automático automatizados y reproducibles.
- Evaluar y monitorear modelos de ML.
- Experiencia MLOps de extremo a extremo.
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
¿Qué es Prefect y CometML?
Prefecto
Prefecto es una biblioteca Python de código abierto que le ayuda a definir, programar y gestionar bien los flujos de trabajo de datos. Simplifica la organización y automatización de flujos de trabajo de datos complejos, lo que facilita las tareas. Algunos ejemplos son la extracción, transformación y entrenamiento de modelos de datos. Puedes hacerlos de forma sistemática y repetible.
pip install prefectOtra cosa que debo mencionar es Prefect Cloud. Prefect Cloud es una plataforma basada en la nube proporcionada por Prefect para administrar, orquestar y monitorear flujos de trabajo de datos en MLOps.
CometaML
CometaML es una plataforma para gestionar y rastrear experimentos de aprendizaje automático en MLOps. Proporciona herramientas para control de versiones, colaboración y visualización de resultados. Ayuda a agilizar el desarrollo y el seguimiento de modelos de aprendizaje automático.
pip install comet_mlEl proyecto MLOps: comencemos.
Exploración de datos
A medida que construimos un modelo de aprendizaje automático de un extremo a otro, nos centraremos más en el ciclo de vida del aprendizaje automático que en la construcción de modelos.
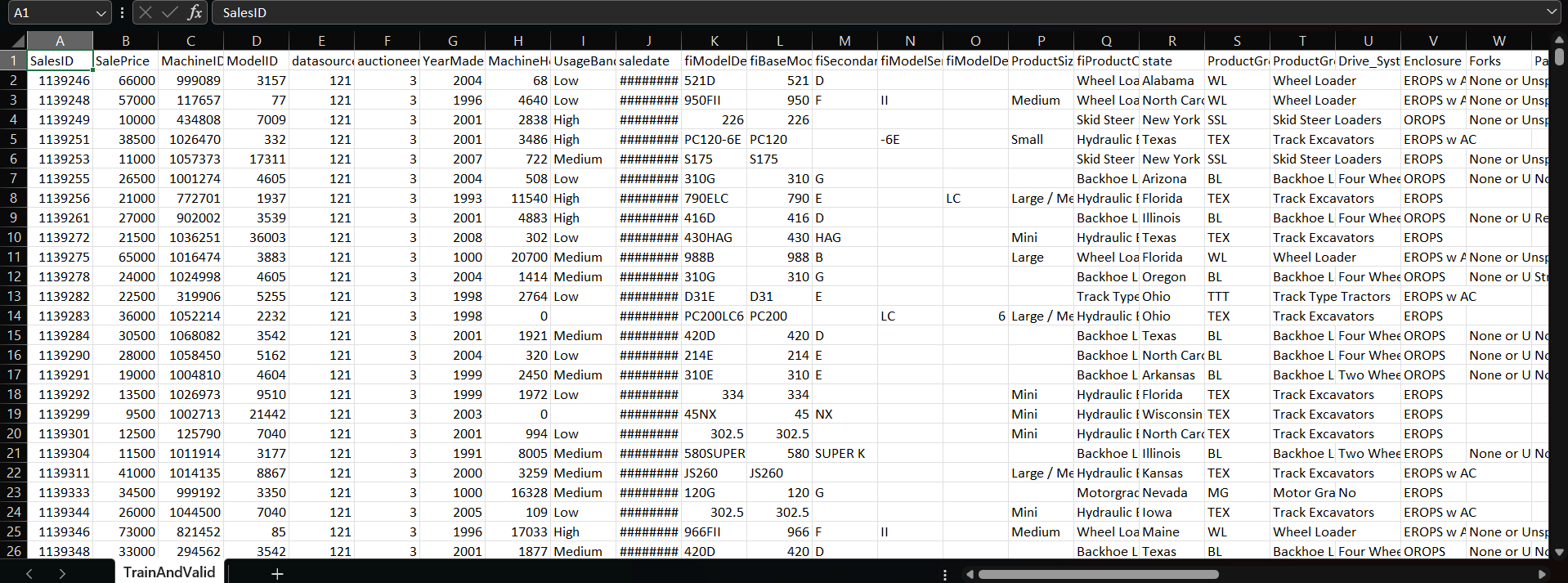
Si observa el conjunto de datos, verá que hay 53 columnas. Usaremos las 52 columnas para características de entrada o x, y dado que nuestra variable objetivo es Precio de venta, esta será la y. En la parte de exploración de datos, realizamos todo tipo de exploraciones, desde df.info() hasta trazar valores faltantes mediante un diagrama de dispersión. Encontrarás todos los pasos en mi cuaderno en el repositorio de GitHub. También puede descargar el conjunto de datos desde allí. Ahora, comencemos a trabajar en el proyecto.
Configurar un entorno virtual
¿Qué es el entorno virtual y por qué lo necesitamos?
Un entorno virtual es un espacio de trabajo de Python autónomo para aislar las dependencias del proyecto.
Instala muchas bibliotecas en su computadora para varios proyectos. Es posible que haya instalado Python3.11, pero a veces necesita Python3.9 para otro proyecto. Para evitar conflictos, es necesario configurar un entorno virtual.
Creando un entorno virtual
python -m venv myenv
#then for activation
myenv\Scripts\activatepython3 -m venv myenv
#then for activation
source myenv/bin/activateEstructura de archivos
Configurar CometML y Prefecto
Para configurar CometML, debe crear un archivo llamado .comet.config en el directorio de su proyecto y definir sus parámetros de configuración. A continuación se muestra un ejemplo de cómo se puede estructurar un archivo .comet.config básico:
(comet)
api_key = your_api_key
workspace = your_workspace
project_name = your_project_nameDeberías registrarte para Cometa para api_key, espacio de trabajo y nombre_proyecto. Echemos un vistazo a cómo configurar una cuenta Comet.
Configurar una cuenta Comet
- Por favor cree una nueva cuenta. Es fácil y gratis.
Clave API
- Cuando se cree su cuenta en la esquina superior derecha, haga clic en su avatar y luego seleccione Configuración de la cuenta.
- Para obtener la clave API, haga clic en la pestaña Claves API. Su clave API actual se muestra allí. Haga clic en Copiar para copiar la clave API.
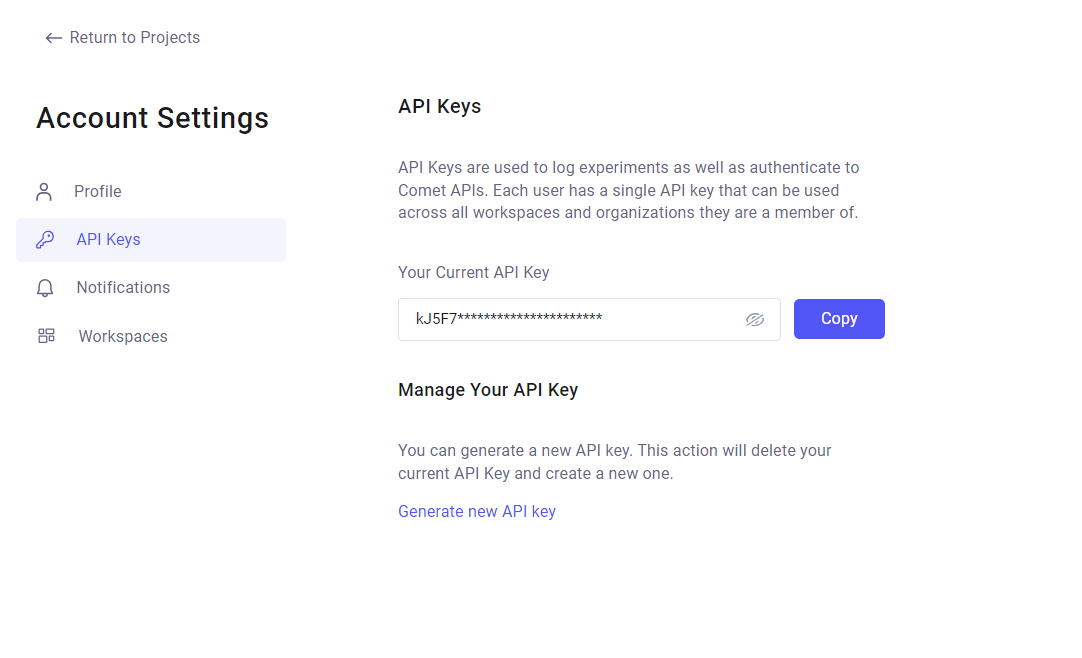
- Puede ver el nombre de su espacio de trabajo y el nombre del proyecto en la pestaña Espacios de trabajo.
Ahora configuremos Prefecto.
Configurar el prefecto
Prefect proporciona una plataforma en la nube y una API para gestionar y monitorear los flujos de trabajo. Al registrarnos, podemos utilizar Prefect Cloud. Tiene un panel para rastrear los flujos de trabajo. Puede configurar notificaciones, analizar registros y más. Lo interesante es que podemos implementar nuestro modelo de aprendizaje automático.
pip install -U prefectVer el Guía de instalación para más detalles.
- Paso 2: Conéctese a la API de Prefect
La funcionalidad de Prefect se basa en una API de backend en la nube. La API gestiona la ejecución de flujos de trabajo y canalizaciones de datos. Necesitamos conectar la instalación de Prefect a esta API. Esto desbloquea funciones útiles. Por ejemplo, se puede utilizar un panel central para observar la ejecución del flujo de trabajo. También te permite configurar notificaciones. Puede obtenerlos cuando las tareas fallan, analizar registros y realizar un seguimiento del historial de tareas. Por último, le permite escalar cargas de trabajo en un clúster. Podemos crear flujos de trabajo localmente sin la API. Pero no podemos hacerlos operativos o listos para la producción. Prefect Cloud maneja la programación y los reintentos. Sigue los límites establecidos a través de la API. Entonces, usar Prefect con su servicio API ofrece una plataforma sin servidor. Sirve para gestionar flujos de trabajo complejos sin necesidad de alojar a sus propios coordinadores.
- Crea una nueva cuenta o inicia sesión en
- Utilice el comando CLI de inicio de sesión en la nube perfecto para
Inicio de sesión perfecto en la nube
Elija Iniciar sesión con un navegador web y haga clic en el botón Autorizar en la ventana abierta del navegador.
Instancia de servidor Prefect autohospedado
También puede ejecutar esto en su máquina local. Ver el tutorial por ayuda. Tenga en cuenta que debe alojar su propio servidor y ejecutar sus flujos en su propia infraestructura.
- Paso 3: Convierte tu función en un flujo perfecto
Ver el flujo.py archivo donde agregué el decorador @flow. Esta es la forma más rápida de empezar con Prefect. Un “Flujo” es un gráfico acíclico dirigido (DAG) que representa un flujo de trabajo. En Prefect, una tarea es una unidad de trabajo fundamental en el flujo de trabajo. Discutiremos las tareas más adelante en este tutorial.
5 pasos para implementar este proyecto MLOps usando Prefect y CometML
Aquí están los 5 pasos para implementar el proyecto MLops usando Prefect y CometML
Paso 1: ingesta de datos
En este paso, ingerimos nuestros datos de nuestra carpeta de datos. Echemos un vistazo a nuestro archivo ingest_data.py dentro de la carpeta de pasos.
class IngestData:
"""Ingests data from a CSV file."""
def __init__(self, data_path: str):
self.data_path = data_path
def get_data(self):
logging.info(f"Ingest data from {self.data_path}")
return pd.read_csv(self.data_path)
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def ingest_df(data_path: str) -> pd.DataFrame:
"""
Ingest data from the specified path and return a DataFrame.
Args:
data_path (str): The path to the data file.
Returns:
pd.DataFrame: A pandas DataFrame containing the ingested data.
"""
try:
ingest_obj = IngestData(data_path)
df = ingest_obj.get_data()
print(f"Ingesting data from {data_path}")
experiment.log_metric("data_ingestion_status", 1)
return df
except Exception as e:
logging.error(f"Error while ingesting data: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()En Prefect, una tarea es una unidad de trabajo fundamental en un flujo de trabajo. Representa una unidad de cálculo individual o una operación que debe realizarse. Entonces, en este caso, nuestra primera tarea es ingerir los datos.
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))Este decorador de tareas de Prefecto especifica los parámetros de almacenamiento en caché, utiliza task_input_hash como función de clave de caché y establece una caducidad de caché de una hora. Puede obtener más información sobre esto en el documento prefecto.
Paso 2: limpiar datos
En este paso, limpiaremos nuestros datos y el siguiente código devolverá X_train, X_test, y_train, y_test, para entrenar y probar nuestro modelo ML. Echemos un vistazo
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def clean_df(data: pd.DataFrame) -> Tuple(
Annotated(pd.DataFrame, 'X_train'),
Annotated(pd.DataFrame, 'X_test'),
Annotated(pd.Series, 'y_train'),
Annotated(pd.Series, 'y_test'),
):
"""
Data cleaning class which preprocesses the data and divides it into train and test data.
Args:
data: pd.DataFrame
"""
try:
preprocess_strategy = DataPreprocessStrategy()
data_cleaning = DataCleaning(data, preprocess_strategy)
preprocessed_data = data_cleaning.handle_data()
divide_strategy = DataDivideStrategy()
data_cleaning = DataCleaning(preprocessed_data, divide_strategy)
X_train, X_test, y_train, y_test = data_cleaning.handle_data()
logging.info(f"Data Cleaning Complete")
experiment.log_metric("data_cleaning_status", 1)
return X_train, X_test, y_train, y_test
except Exception as e:
logging.error(e)
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()
Hasta este punto, si observa el código anterior con atención, podría estar pensando, ¿dónde están definidos DataPreprocessStrategy() y DataDivideStrategy() dentro de la carpeta del modelo? Nosotros definimos estos métodos; echemos un vistazo
class DataPreprocessStrategy(DataStrategy):
"""
Data preprocessing strategy which preprocesses the data.
"""
def handle_data(self, data: pd.DataFrame) -> pd.DataFrame:
try:
"""
Performs transformations on df and returns transformaed df.
"""
# Convert 'saledate' column to datetime
data('saledate') = pd.to_datetime(data('saledate'))
data("saleYear") = data.saledate.dt.year
data("saleMonth") = data.saledate.dt.month
data("saleDay") =data.saledate.dt.day
data("saleDayOfWeek") = data.saledate.dt.dayofweek
data("saleDayOfYear") = data.saledate.dt.dayofyear
data.drop("saledate", axis=1, inplace=True)
# Fill the numeric row with median
for label, content in data.items():
if pd.api.types.is_numeric_dtype(content):
if pd.isnull(content).sum():
# Add a binary column which tells us if the data was missing
# or not
data(label+"is_missing") = pd.isnull(content)
# Fill missing numeric values with median
data(label) = content.fillna(content.median())
# Filled categorical missing data and turn categories into numbers
if not pd.api.types.is_numeric_dtype(content):
data(label+"is_missing") = pd.isnull(content)
# We add +1 to the category code because pandas encodes
# missing categories as -1
data(label) = pd.Categorical(content).codes+1
return data
except Exception as e:
logging.error("Error in Data handling: {}".format(e))
raise e
En mi GitHub repositorio, puede encontrar todos los métodos.
Paso 3: modelo de tren
Entrenaremos un modelo de regresión lineal simple utilizando la biblioteca de aprendizaje Scikit.
# Create a CometML experiment
experiment = Experiment()
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def train_model(
X_train: pd.DataFrame,
X_test: pd.DataFrame,
y_train: pd.Series,
y_test: pd.Series,
config: ModelNameConfig = ModelNameConfig(),
) -> RegressorMixin:
"""
Train a regression model based on the specified configuration.
Args:
X_train (pd.DataFrame): Training data features.
X_test (pd.DataFrame): Testing data features.
y_train (pd.Series): Training data target.
y_test (pd.Series): Testing data target.
config (ModelNameConfig): Model configuration.
Returns:
RegressorMixin: Trained regression model.
"""
try:
model = None
if config.model_name == "random_forest_regressor":
model = RandomForestRegressor(n_estimators=40,
min_samples_leaf=1,
min_samples_split=14,
max_features=0.5,
n_jobs=-1,
max_samples=None,
random_state=42)
trained_model = model.fit(X_train, y_train)
# Save the trained model to a file
model_filename = "trained_model.pkl"
with open(model_filename, 'wb') as model_file:
pickle.dump(trained_model, model_file)
print("train model finished")
experiment.log_metric("model_training_status", 1)
return trained_model
else:
raise ValueError("Model name not supported")
except Exception as e:
logging.error(f"Error in train model: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()Paso 4: evaluar el modelo
# Create a CometML experiment
experiment = Experiment()
@task(cache_key_fn=task_input_hash, cache_expiration=timedelta(hours=1))
def evaluate_model(
model: RegressorMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple(Annotated(float, "r2"),
Annotated(float, "rmse"),
):
"""
Args:
model: RegressorMixin
x_test: pd.DataFrame
y_test: pd.Series
Returns:
r2_score: float
rmse: float
"""
try:
prediction = model.predict(X_test)
# Using the MSE class for mean squared error calculation
mse_class = MSE()
mse = mse_class.calculate_score(y_test, prediction)
experiment.log_metric("MSE", mse)
# Using the R2Score class for R2 score calculation
r2_class = R2Score()
r2 = r2_class.calculate_score(y_test, prediction)
experiment.log_metric("R2Score", r2)
# Using the RMSE class for root mean squared error calculation
rmse_class = RMSE()
rmse = rmse_class.calculate_score(y_test, prediction)
experiment.log_metric("RMSE", rmse)
# Log metrics to CometML
experiment.log_metric("model_evaluation_status", 1)
print("Evaluate model finished")
return r2, rmse
except Exception as e:
logging.error(f"Error in evaluation: {e}")
raise e
finally:
# Ensure that the experiment is ended to log all data
experiment.end()Hemos registrado todas esas métricas, como puntuación r2, mse y rmse. Puedes ver el código anterior. Podemos visualizar esas matrices en el panel de CometML. Sin embargo, cuando ejecuta el flujo, puede ver el panel. En el siguiente paso, lo discutimos.
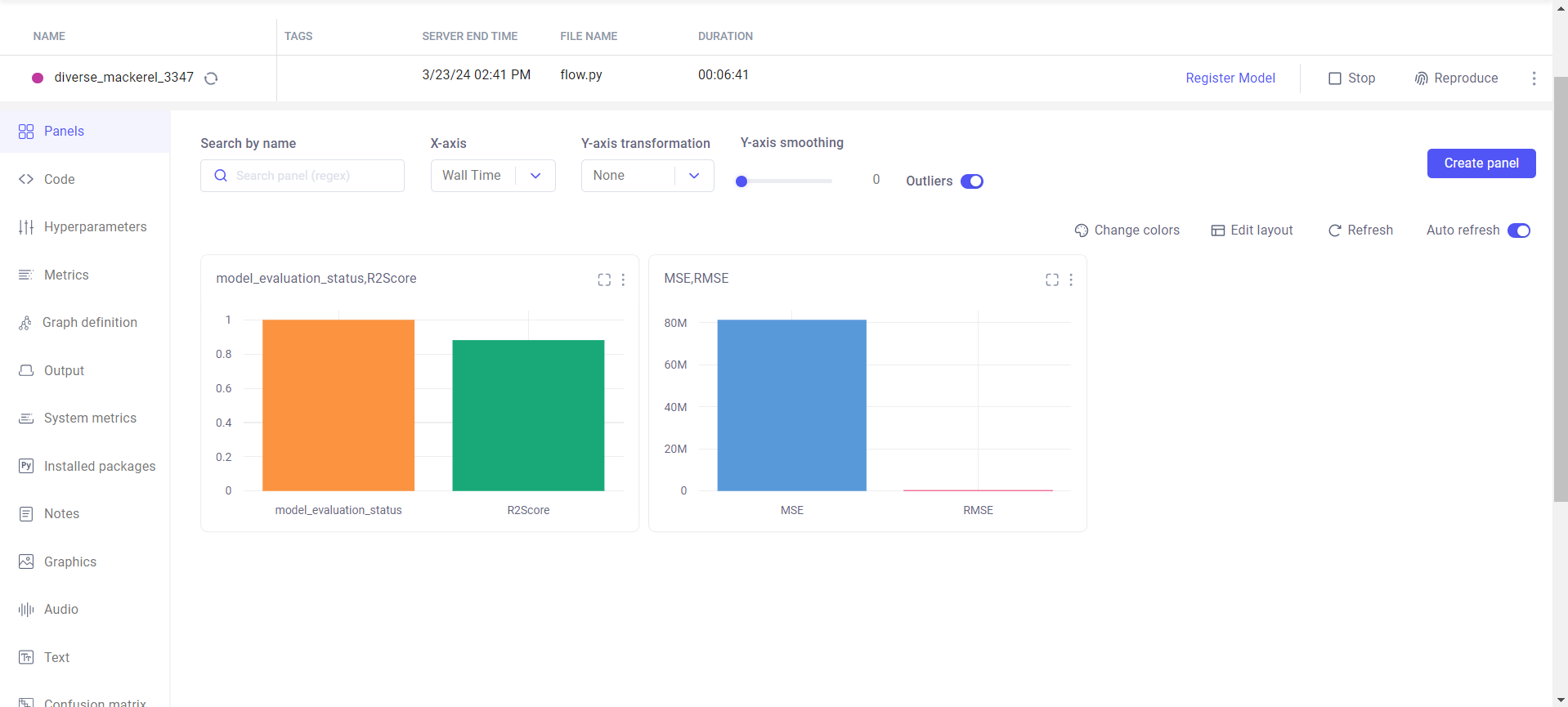
Paso 5: ejecutar el flujo (el paso final)
Tenemos que seguir la corriente.
Importamos todas las tareas y flujos al archivo flow.py y ejecutamos nuestro flujo desde allí.
python3 flow.pyfrom prefect import flow
from steps. ingest_data import ingest_df
from steps.clean_data import clean_df
from steps.train_model import train_model
from steps.evaluation import evaluate_model
## import comet_ml at the top of your file
from comet_ml import Experiment
## Create an experiment with your api key
@flow(retries=3, retry_delay_seconds=5, log_prints=True)
def my_flow():
data_path="/home/dhrubaubuntu/gigs_projects/Bulldozer-price-prediction/data/TrainAndValid.csv"
df = ingest_df(data_path)
X_train, X_test, y_train, y_test = clean_df(df)
model = train_model(X_train, X_test, y_train, y_test)
r2_score, rmse = evaluate_model(model, X_test, y_test)
# Run the Prefect Flow
if __name__ == "__main__":
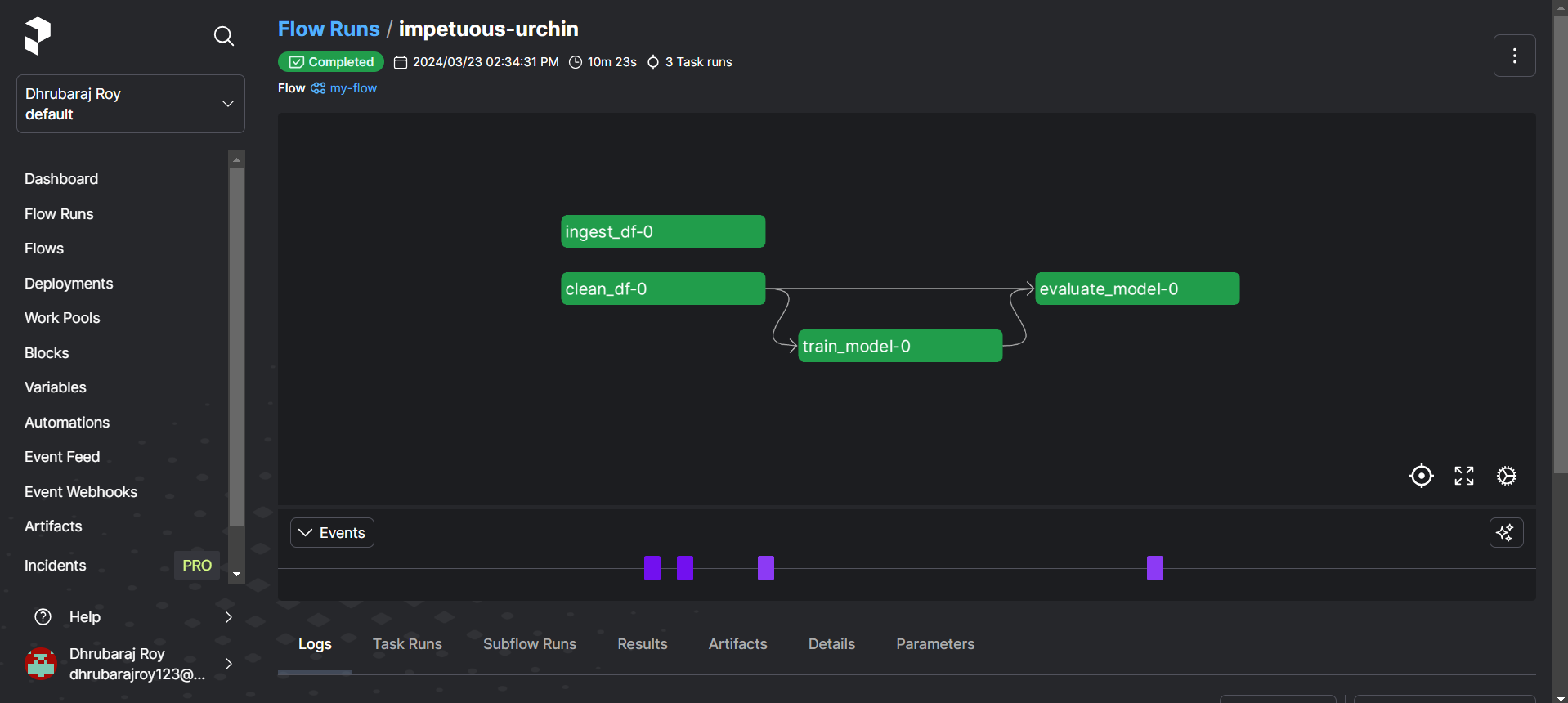
my_flow()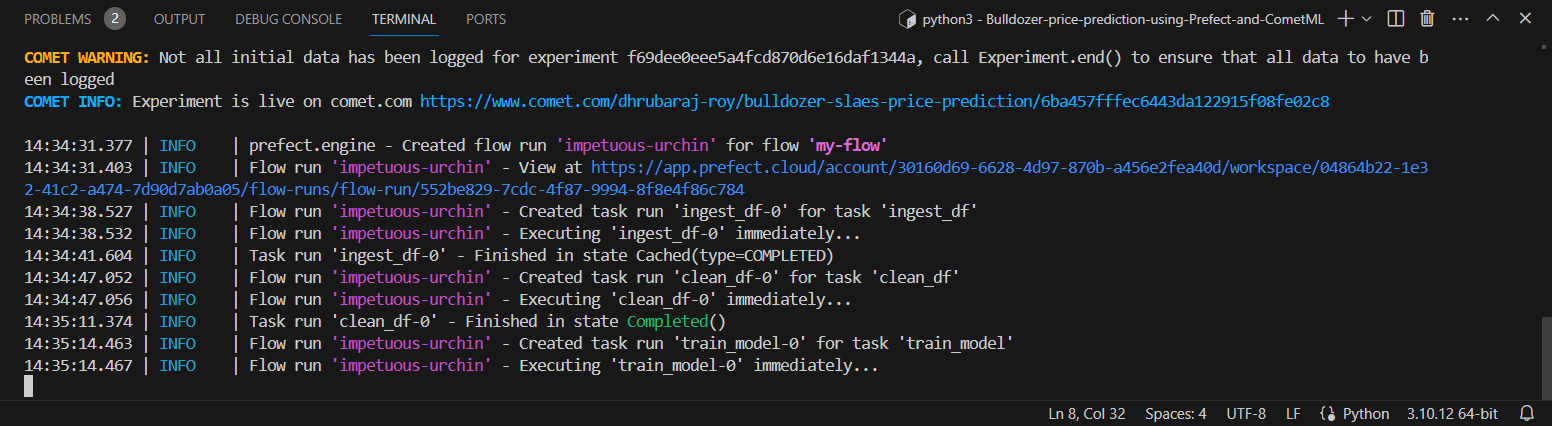
Aquí puede ver todos los paneles de flujo de ejecución en Prefect
Conclusión
La implementación de MLOps de un extremo a otro permite a las organizaciones ampliar de manera confiable las soluciones de aprendizaje automático en producción. Este tutorial demostró un flujo de trabajo automatizado para predecir autonomías de vehículos eléctricos utilizando bibliotecas de código abierto como Prefect y CometML.
Los aspectos más destacados del proyecto incluyen:
- Orquestar una canalización de ML con Prefect implica manejar pasos que van desde la ingesta de datos, el preprocesamiento, el desarrollo de modelos, la evaluación y el monitoreo.
- Seguimiento de experimentos en CometML para visualizar métricas del modelo como puntuaciones RMSE y R2 a lo largo del tiempo para compararlas.
- Monitoreo de ejecuciones de flujo de trabajo en Prefect Cloud que muestra la duración de las tareas.
En general, esta exhibición implementa las mejores prácticas de automatización, reproducibilidad y monitoreo de la ciencia de datos en un flujo de trabajo estructurado crítico para los sistemas de aprendizaje automático del mundo real. Extender y poner en funcionamiento a la producción puede aprovechar aún más la escalabilidad de Prefect en la gestión de flujos a gran escala en la infraestructura distribuida.
Conclusiones clave
Algunas conclusiones clave de este tutorial de MLOps de un extremo a otro incluyen:
- La implementación de MLOps mejora los científicos de datos y la colaboración de TI con prácticas de automatización y DevOps.
- Prefect permite la creación de flujos de trabajo y canales de datos sólidos para ingerir, procesar, entrenar y evaluar modelos.
- CometML proporciona una manera sencilla de realizar un seguimiento de los experimentos de ML con registro y visualización.
- Orquestar el ciclo de vida del aprendizaje automático de un extremo a otro garantiza que los modelos sigan siendo relevantes a medida que llegan nuevos datos.
- Monitorear las ejecuciones del flujo de trabajo ayuda a identificar y solucionar fallas rápidamente.
- MLOps desbloquea una experimentación más rápida al simplificar el reentrenamiento y la implementación de modelos actualizados.
Preguntas frecuentes
Respuesta. MLOps para aprendizaje automático es un conjunto de prácticas que tiene como objetivo optimizar y automatizar el ciclo de vida del aprendizaje automático de un extremo a otro, incluido el desarrollo, la implementación y el mantenimiento de modelos, para mejorar la colaboración y la eficiencia en los equipos de operaciones y ciencia de datos.
Respuesta. Prefect es una biblioteca Python de código abierto para la gestión del flujo de trabajo. Permite la creación, programación y orquestación de flujos de trabajo de datos y tareas comúnmente utilizadas en procesos de automatización y ciencia de datos. Simplifica los flujos de trabajo complejos, centrándose en la flexibilidad, la confiabilidad y el monitoreo.
Respuesta. CometML es una plataforma para la experimentación y colaboración del aprendizaje automático. Proporciona herramientas para rastrear, comparar y optimizar experimentos de aprendizaje automático, lo que permite a los equipos registrar y compartir detalles, métricas y visualizaciones de experimentos para mejorar el desarrollo de modelos y la colaboración.
Respuesta. Prefect se utiliza para la gestión del flujo de trabajo en ciencia de datos y automatización. Ayuda a optimizar y organizar flujos de trabajo de datos complejos, lo que facilita el diseño, la programación y el seguimiento coherente de las tareas. Prefect se emplea comúnmente para el procesamiento de datos, el entrenamiento de modelos de aprendizaje automático y otras operaciones centradas en datos, proporcionando un marco para crear, ejecutar y administrar flujos de trabajo de manera eficiente.
Respuesta. MLflow es una plataforma de código abierto para gestionar el ciclo de vida del aprendizaje automático de un extremo a otro, incluido el seguimiento de experimentos, empaquetar código en ejecuciones reproducibles y compartir e implementar modelos. Comet es una plataforma para la experimentación y colaboración del aprendizaje automático, que se centra en el seguimiento de experimentos, visualizaciones y funciones de colaboración. Proporciona un centro centralizado para que los equipos analicen y compartan resultados. Si bien ambos admiten el seguimiento de experimentos, MLflow ofrece características adicionales de empaquetado e implementación de modelos, mientras que Comet enfatiza las capacidades de colaboración y visualización.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





{kind=link}