 NEWSLETTER
NEWSLETTER
Hoy, nos complace anunciar el modelo de lenguaje grande (LLM) Mixtral-8x22B, desarrollado por ai/” target=”_blank” rel=”noopener”>Mistral ai, está disponible para que los clientes a través de amazon SageMaker JumpStart lo implementen con un solo clic para ejecutar inferencia. Puede probar este modelo con SageMaker JumpStart, un centro de aprendizaje automático (ML) que brinda acceso a algoritmos y modelos para que pueda comenzar rápidamente con ML. En esta publicación, explicamos cómo descubrir e implementar el modelo Mixtral-8x22B.
¿Qué es Mixtral 8x22B?
Mixtral 8x22B es el último modelo de pesas abiertas de Mistral ai y ai/news/mixtral-8x22b/” target=”_blank” rel=”noopener”>establece un nuevo estándar de rendimiento y eficiencia de los modelos de cimentación disponibles, según lo medido por Mistral ai en los puntos de referencia estándar de la industria. Es un modelo escaso de Mezcla de Expertos (SMoE) que utiliza sólo 39 mil millones de parámetros activos de 141 mil millones, lo que ofrece rentabilidad para su tamaño. Continuando con la creencia de Mistral ai en el poder de los modelos disponibles públicamente y su amplia distribución para promover la innovación y la colaboración, Mixtral 8x22B se lanza bajo Apache 2.0, lo que hace que el modelo esté disponible para exploración, prueba e implementación. Mixtral 8x22B es una opción atractiva para los clientes que seleccionan entre modelos disponibles públicamente y priorizan la calidad, y para aquellos que desean una mayor calidad en modelos de tamaño mediano, como Mixtral 8x7B y GPT 3.5 Turbo, manteniendo al mismo tiempo un alto rendimiento.
Mixtral 8x22B proporciona los siguientes puntos fuertes:
- Capacidades nativas multilingües en inglés, francés, italiano, alemán y español.
- Fuertes capacidades matemáticas y de codificación.
- Capaz de realizar llamadas a funciones que permiten el desarrollo de aplicaciones y la modernización de la pila tecnológica a escala.
- Ventana contextual de 64.000 tokens que permite recuperar información precisa de documentos grandes
Acerca de Mistral ai
Mistral ai es una empresa con sede en París fundada por investigadores experimentados de Meta y Google DeepMind. Durante su tiempo en DeepMind, Arthur Mensch (CEO de Mistral) fue un colaborador principal en proyectos clave de LLM como Flamingo y Chinchilla, mientras que Guillaume Lample (Científico jefe de Mistral) y Timothée Lacroix (CTO de Mistral) lideraron el desarrollo de LLaMa LLM durante su tiempo. en Meta. El trío forma parte de una nueva generación de fundadores que combinan una profunda experiencia técnica y operativa trabajando en tecnología de aprendizaje automático de última generación en los laboratorios de investigación más grandes. Mistral ai ha defendido modelos básicos pequeños con rendimiento superior y compromiso con el desarrollo de modelos. Continúan ampliando la frontera de la inteligencia artificial (IA) y haciéndola accesible para todos con modelos que ofrecen una rentabilidad inigualable para sus respectivos tamaños, ofreciendo una atractiva relación rendimiento-coste. Mixtral 8x22B es una continuación natural de la familia de modelos disponibles públicamente de Mistral ai que incluye Mistral 7B y Mixtral 8x7B, también disponibles en SageMaker JumpStart. Más recientemente, Mistral lanzó modelos comerciales de nivel empresarial, y Mistral Large ofrece un rendimiento de primer nivel y supera a otros modelos populares con dominio nativo en varios idiomas.
¿Qué es SageMaker JumpStart?
Con SageMaker JumpStart, los profesionales del aprendizaje automático pueden elegir entre una lista cada vez mayor de modelos básicos de mejor rendimiento. Los profesionales del aprendizaje automático pueden implementar modelos básicos en instancias dedicadas de amazon SageMaker dentro de un entorno aislado de red y personalizar modelos utilizando SageMaker para el entrenamiento y la implementación de modelos. Ahora puede descubrir e implementar Mixtral-8x22B con unos pocos clics en amazon SageMaker Studio o mediante programación a través del SDK de SageMaker Python, lo que le permite derivar el rendimiento del modelo y controles MLOps con funciones de SageMaker como amazon SageMaker Pipelines, amazon SageMaker Debugger o registros de contenedores. . El modelo se implementa en un entorno seguro de AWS y bajo los controles de su VPC, lo que proporciona cifrado de datos en reposo y en tránsito.
SageMaker también se adhiere a marcos de seguridad estándar como ISO27001 y SOC1/2/3, además de cumplir con varios requisitos reglamentarios. Se admiten marcos de cumplimiento como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA), la Ley de Responsabilidad y Portabilidad del Seguro Médico (HIPAA) y el Estándar de Seguridad de Datos de la Industria de Tarjetas de Pago (PCI DSS) para garantizar el manejo, almacenamiento y y el proceso cumplen estrictos estándares de seguridad.
La disponibilidad de SageMaker JumpStart depende del modelo; Mixtral-8x22B v0.1 actualmente es compatible con las regiones de AWS Este de EE. UU. (Norte de Virginia) y Oeste de EE. UU. (Oregón).
Descubre modelos
Puede acceder a los modelos básicos de Mixtral-8x22B a través de SageMaker JumpStart en la interfaz de usuario de SageMaker Studio y el SDK de SageMaker Python. En esta sección, repasamos cómo descubrir los modelos en SageMaker Studio.
SageMaker Studio es un entorno de desarrollo integrado (IDE) que proporciona una única interfaz visual basada en web donde puede acceder a herramientas diseñadas específicamente para realizar todos los pasos de desarrollo de ML, desde la preparación de datos hasta la creación, el entrenamiento y la implementación de sus modelos de ML. Para obtener más detalles sobre cómo comenzar y configurar SageMaker Studio, consulte amazon SageMaker Studio.
En SageMaker Studio, puede acceder a SageMaker JumpStart eligiendo Buen inicio en el panel de navegación.
Desde la página de inicio de SageMaker JumpStart, puede buscar “Mixtral” en el cuadro de búsqueda. Verá resultados de búsqueda que muestran Mixtral 8x22B Instruct, varios modelos Mixtral 8x7B y modelos Dolphin 2.5 y 2.7.
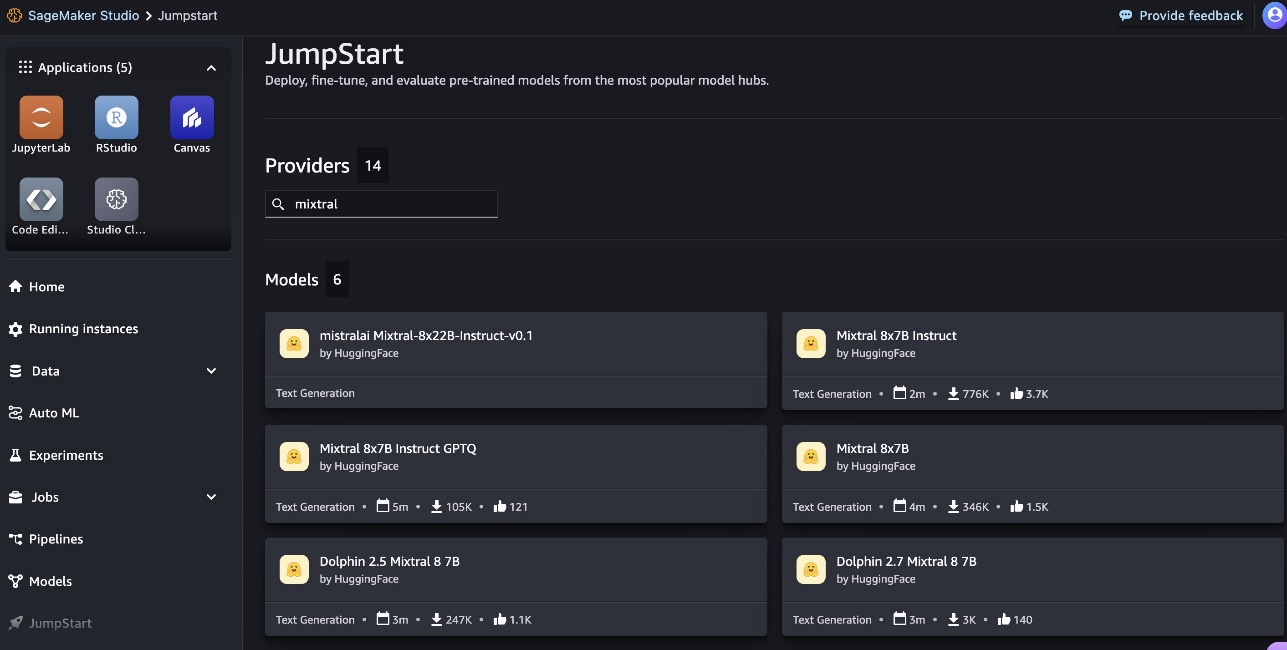
Puede elegir la tarjeta de modelo para ver detalles sobre el modelo, como la licencia, los datos utilizados para entrenar y cómo utilizarlo. También encontrarás el Desplegar que puede utilizar para implementar el modelo y crear un punto final.
SageMaker tiene habilitado el registro, el monitoreo y la auditoría sin problemas para los modelos implementados con integraciones nativas con servicios como AWS CloudTrail para el registro y el monitoreo para proporcionar información sobre las llamadas API y amazon CloudWatch para recopilar métricas, registros y datos de eventos para proporcionar información sobre el recurso del modelo. utilización.
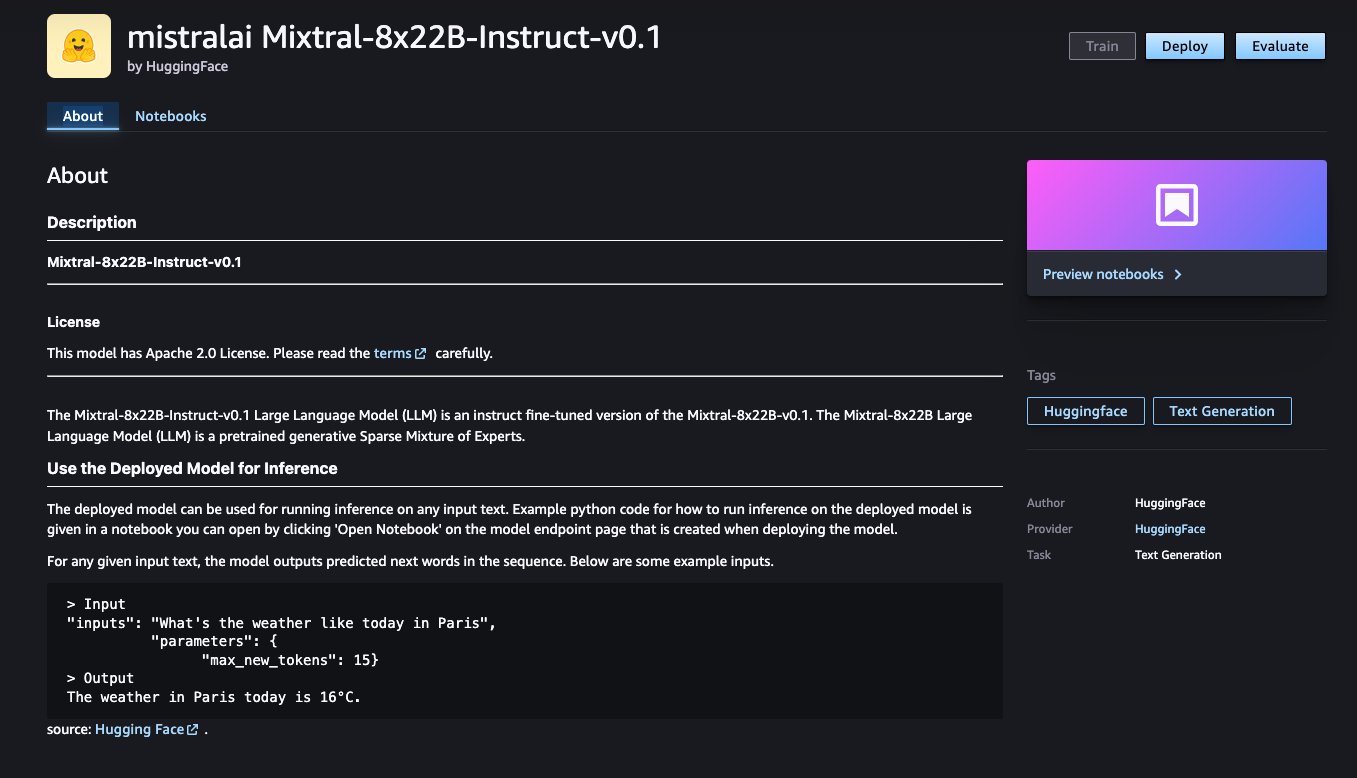
Implementar un modelo
La implementación comienza cuando usted elija Desplegar. Una vez finalizada la implementación, se crea un punto final. Puede probar el punto final pasando una carga útil de solicitud de inferencia de muestra o seleccionando su opción de prueba mediante el SDK. Cuando seleccione la opción para usar el SDK, verá un código de ejemplo que puede usar en su editor de cuaderno preferido en SageMaker Studio. Esto requerirá un rol y una política de AWS Identity and Access Management (IAM) adjuntos para restringir el acceso al modelo. Además, si elige implementar el punto final del modelo dentro de SageMaker Studio, se le pedirá que elija un tipo de instancia, un recuento de instancias inicial y un recuento máximo de instancias. Los tipos de instancia ml.p4d.24xlarge y ml.p4de.24xlarge son los únicos tipos de instancia admitidos actualmente para Mixtral 8x22B Instruct v0.1.
Para implementar usando el SDK, comenzamos seleccionando el modelo Mixtral-8x22b, especificado por el model_id con valor huggingface-llm-mistralai-mixtral-8x22B-instruct-v0-1. Puede implementar cualquiera de los modelos seleccionados en SageMaker con el siguiente código. De manera similar, puede implementar la instrucción Mixtral-8x22B utilizando su propio ID de modelo.
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModelo.
Una vez implementado, puede ejecutar inferencia contra el punto final implementado a través del predictor de SageMaker:
Indicaciones de ejemplo
Puede interactuar con un modelo Mixtral-8x22B como cualquier modelo de generación de texto estándar, donde el modelo procesa una secuencia de entrada y genera las siguientes palabras predichas en la secuencia. En esta sección, proporcionamos indicaciones de ejemplo.
Instrucción Mixtral-8x22b
La versión adaptada a las instrucciones de Mixtral-8x22B acepta instrucciones formateadas en las que los roles de conversación deben comenzar con un mensaje del usuario y alternar entre instrucciones del usuario y asistente (respuesta modelo). El formato de instrucción debe respetarse estrictamente; de lo contrario, el modelo generará resultados subóptimos. La plantilla utilizada para crear un mensaje para el modelo Instruct se define de la siguiente manera:
y are special tokens for beginning of string (BOS) and end of string (EOS), whereas (INST) y (/INST) son cadenas regulares.
El siguiente código muestra cómo puede formatear el mensaje en formato de instrucción:
Mensaje de resumen
Puede utilizar el siguiente código para obtener una respuesta para un resumen:
El siguiente es un ejemplo del resultado esperado:
Mensaje de traducción multilingüe
Puede utilizar el siguiente código para obtener una respuesta para una traducción multilingüe:
El siguiente es un ejemplo del resultado esperado:
Codigo de GENERACION
Puede utilizar el siguiente código para obtener una respuesta para la generación de código:
Obtendrá el siguiente resultado:
razonamiento y matematicas
Puede utilizar el siguiente código para obtener una respuesta de razonamiento y matemáticas:
Obtendrá el siguiente resultado:
Limpiar
Una vez que haya terminado de ejecutar el cuaderno, elimine todos los recursos que creó en el proceso para que se detenga su facturación. Utilice el siguiente código:
Conclusión
En esta publicación, le mostramos cómo comenzar con Mixtral-8x22B en SageMaker Studio e implementar el modelo para inferencia. Dado que los modelos básicos están previamente entrenados, pueden ayudar a reducir los costos de capacitación e infraestructura y permitir la personalización para su caso de uso. Visite SageMaker JumpStart en SageMaker Studio ahora para comenzar.
Ahora que conoce Mistral ai y sus modelos Mixtral 8x22B, le recomendamos que implemente un punto final en SageMaker para realizar pruebas de inferencia y probar las respuestas usted mismo. Consulte los siguientes recursos para obtener más información:
Sobre los autores
 Marco Punio es un arquitecto de soluciones centrado en la estrategia de IA generativa, soluciones de IA aplicadas y en la realización de investigaciones para ayudar a los clientes a hiperescalar en AWS. Es un tecnólogo calificado apasionado por el aprendizaje automático, la inteligencia artificial y las fusiones y adquisiciones. Marco reside en Seattle, WA, y le gusta escribir, leer, hacer ejercicio y crear aplicaciones en su tiempo libre.
Marco Punio es un arquitecto de soluciones centrado en la estrategia de IA generativa, soluciones de IA aplicadas y en la realización de investigaciones para ayudar a los clientes a hiperescalar en AWS. Es un tecnólogo calificado apasionado por el aprendizaje automático, la inteligencia artificial y las fusiones y adquisiciones. Marco reside en Seattle, WA, y le gusta escribir, leer, hacer ejercicio y crear aplicaciones en su tiempo libre.
 Preston Tuggle es un arquitecto senior de soluciones especializado que trabaja en IA generativa.
Preston Tuggle es un arquitecto senior de soluciones especializado que trabaja en IA generativa.
 Junio ganó es gerente de producto de amazon SageMaker JumpStart. Se centra en hacer que los modelos básicos sean fácilmente detectables y utilizables para ayudar a los clientes a crear aplicaciones de IA generativa. Su experiencia en amazon también incluye aplicación de compra móvil y entrega de última milla.
Junio ganó es gerente de producto de amazon SageMaker JumpStart. Se centra en hacer que los modelos básicos sean fácilmente detectables y utilizables para ayudar a los clientes a crear aplicaciones de IA generativa. Su experiencia en amazon también incluye aplicación de compra móvil y entrega de última milla.
 Dr. Ashish Khaitan es un científico aplicado senior con algoritmos integrados de amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
Dr. Ashish Khaitan es un científico aplicado senior con algoritmos integrados de amazon SageMaker y ayuda a desarrollar algoritmos de aprendizaje automático. Obtuvo su doctorado en la Universidad de Illinois Urbana-Champaign. Es un investigador activo en aprendizaje automático e inferencia estadística, y ha publicado numerosos artículos en conferencias NeurIPS, ICML, ICLR, JMLR, ACL y EMNLP.
 shane rai es especialista principal en GenAI de la Organización Mundial de Especialistas de AWS (WWSO). Trabaja con clientes de todos los sectores para resolver sus necesidades comerciales más apremiantes e innovadoras utilizando la amplia gama de servicios de IA/ML basados en la nube de AWS, incluidas ofertas de modelos de proveedores de modelos básicos de primer nivel.
shane rai es especialista principal en GenAI de la Organización Mundial de Especialistas de AWS (WWSO). Trabaja con clientes de todos los sectores para resolver sus necesidades comerciales más apremiantes e innovadoras utilizando la amplia gama de servicios de IA/ML basados en la nube de AWS, incluidas ofertas de modelos de proveedores de modelos básicos de primer nivel.
 Hemant Singh es un Científico Aplicado con experiencia en amazon SageMaker JumpStart. Obtuvo su maestría del Instituto Courant de Ciencias Matemáticas y su B.tech del IIT Delhi. Tiene experiencia trabajando en una amplia gama de problemas de aprendizaje automático dentro del dominio del procesamiento del lenguaje natural, la visión por computadora y el análisis de series temporales.
Hemant Singh es un Científico Aplicado con experiencia en amazon SageMaker JumpStart. Obtuvo su maestría del Instituto Courant de Ciencias Matemáticas y su B.tech del IIT Delhi. Tiene experiencia trabajando en una amplia gama de problemas de aprendizaje automático dentro del dominio del procesamiento del lenguaje natural, la visión por computadora y el análisis de series temporales.






{kind=link}