 NEWSLETTER
NEWSLETTER
Today we are pleased to announce that Mistral-NeMo-Base-2407 and Mistral-NeMo-Instruction-2407—twelve billion large language models of parameters <a target="_blank" href="https://mistral.ai/” target=”_blank” rel=”noopener”>Mistral ai that excel at text generation, are available to customers through amazon SageMaker JumpStart. You can test these models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models that can be deployed with a single click to run inference. In this post, we explain how to discover, implement, and use the Mistral-NeMo-Instruct-2407 and Mistral-NeMo-Base-2407 models for a variety of real-world use cases.
Overview of Mistral-NeMo-Instruct-2407 and Mistral-NeMo-Base-2407
<a target="_blank" href="https://mistral.ai/news/mistral-nemo/” target=”_blank” rel=”noopener”>Mistral NemoA powerful 12B parameter model developed through collaboration between Mistral ai and NVIDIA and released under the Apache 2.0 license, is now available in SageMaker JumpStart. This model represents a significant advance in the capabilities and accessibility of multilingual ai.
Key Features and Capabilities
Mistral NeMo features a 128k token context window, enabling processing of long and extensive content. The model demonstrates strong performance in reasoning, world knowledge, and coding accuracy. Both the basic pretrained and instruction-tuned checkpoints are available under the Apache 2.0 license, making them accessible to researchers and enterprises. Quantization-aware training of the model facilitates optimal FP8 inference performance without compromising quality.
Multilingual support
Mistral NeMo is designed for global applications, with strong performance in multiple languages, including English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic and Hindi. This multilingual capability, combined with integrated function calling and a wide context window, helps make advanced ai more accessible across diverse linguistic and cultural landscapes.
Tekken: advanced tokenization
The model uses Tekken, an innovative tokenizer based on tiktoken. Trained in over 100 languages, Tekken offers improved compression efficiency for natural language text and source code.
SageMaker JumpStart Overview
SageMaker JumpStart is a fully managed service that offers next-generation core templates for a variety of use cases, including content writing, code generation, question answering, writing, summarizing, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of machine learning applications. One of the key components of SageMaker JumpStart is Model Hub, which offers a wide catalog of pre-trained models, such as DBRX, for a variety of tasks.
You can now discover and deploy both Mistral NeMo models with a few clicks in amazon SageMaker Studio or programmatically through the SageMaker Python SDK, allowing you to derive model performance checks and machine learning operations (MLOps) with features from amazon SageMaker as amazon SageMaker Pipelines. amazon SageMaker debugger or container logs. The model is deployed in a secure AWS environment and under the controls of its virtual private cloud (VPC), which helps support data security.
Prerequisites
To test both NeMo models in SageMaker JumpStart, you will need the following prerequisites:
Discover Mistral NeMo models on SageMaker JumpStart
You can access NeMo models through SageMaker JumpStart in the SageMaker Studio user interface and the SageMaker Python SDK. In this section, we go over how to discover models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single, web-based visual interface where you can access tools specifically designed to perform ML development steps, from data preparation to building, training, and deploying. your ML models. For more details about getting started and setting up SageMaker Studio, see amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart by choosing Begin in the navigation panel.
Then choose HugsFace.
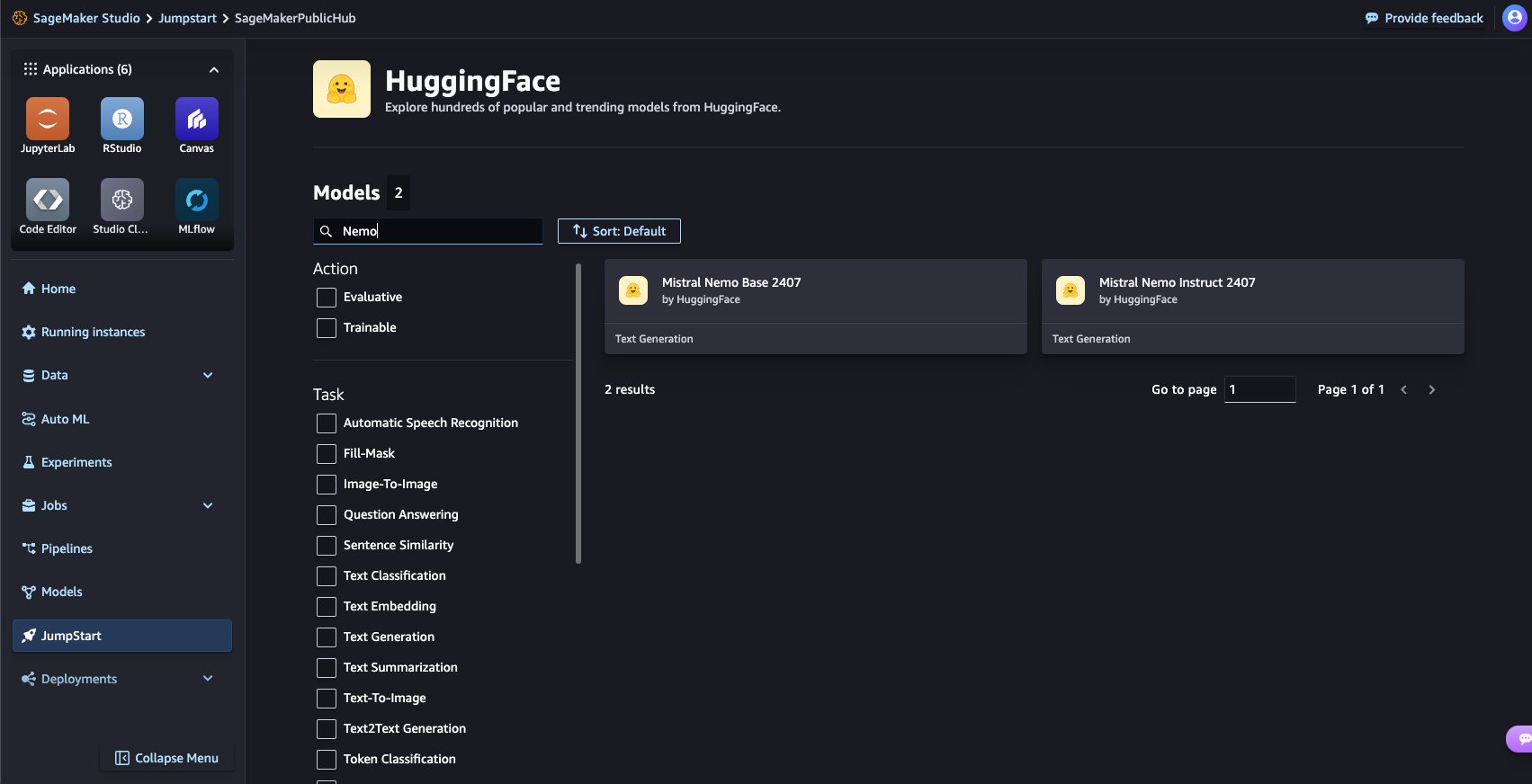
From the SageMaker JumpStart home page, you can search for NeMo in the search box. The search results will show Mistral NeMo Instruction and Mistral Nemo Base.
You can choose the model card to view details about the model, such as the license, the data used to train, and how to use the model. You will also find the Deploy to deploy the model and create an endpoint.
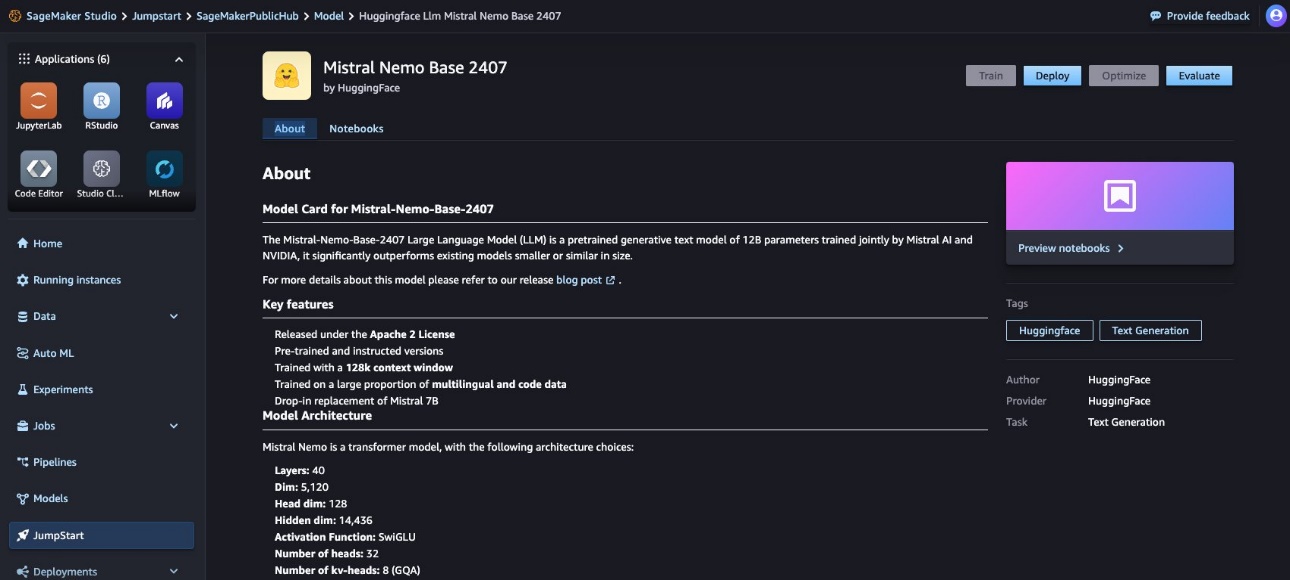
Deploy the model to SageMaker JumpStart
Deployment begins when you choose the Deploy button. Once the deployment is complete, you will see an endpoint being created. You can test the endpoint by passing a sample inference request payload or by selecting the test option using the SDK. When you select the option to use the SDK, you'll see sample code that you can use in the notebook editor of your choice in SageMaker Studio.
Deploy the model with SageMaker Python SDK
To deploy using the SDK, we start by selecting the Mistral NeMo Base model, specified by the model_id with the value huggingface-llm-mistral-nemo-base-2407. You can implement your choice of the selected models in SageMaker with the following code. Similarly, you can implement NeMo Instruct using your own model ID.
This deploys the model to SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these settings by specifying non-default values in JumpStartModel. The EULA value must be explicitly set to True to accept the end user license agreement (EULA). Also make sure you have the service limit at the account level to use ml.g6.12xlarge for endpoint use as one or more instances. You can follow the instructions in AWS Service Quotas to request a service quota increase. Once deployed, you can run inference against the deployed endpoint via the SageMaker predictor:
One important thing to note here is that we are using the <a target="_blank" href="https://docs.djl.ai/master/docs/serving/serving/docs/lmi/index.html” target=”_blank” rel=”noopener”>djl-lmi v12 inference containerso we are following the <a target="_blank" href="https://docs.djl.ai/master/docs/serving/serving/docs/lmi/user_guides/chat_input_output_schema.html” target=”_blank” rel=”noopener”>large model inference chat completion API scheme by sending a payload to both Mistral-NeMo-Base-2407 and Mistral-NeMo-Instruct-2407.
Mistral-NeMo-Base-2407
You can interact with the Mistral-NeMo-Base-2407 model like other standard text generation models, where the model processes an input sequence and generates the next predicted words in the sequence. In this section, we provide some example messages and sample results. Please note that the base model does not have adjusted instructions.
Complete text
Tasks that involve predicting the next token or filling in missing tokens in a sequence:
The following is the result:
Mistral NeMo Instruction
The Mistral-NeMo-Instruct-2407 model is a quick demonstration that the base model can be tuned to achieve convincing performance. You can follow the steps provided to deploy the model and use the model_id value of huggingface-llm-mistral-nemo-instruct-2407 instead.
The instruction-tuned NeMo model can be tested with the following tasks:
Code generation
Mistral NeMo Instruct demonstrates comparative strengths for coding tasks. Mistral claims that its Tekken tokenizer for NeMo is about 30% more efficient at compressing source code. For example, see the following code:
The following is the result:
The model demonstrates strong performance in code generation tasks, with the completion_tokens offering insight into how tokenizer code compression effectively optimizes the representation of programming languages using fewer tokens.
Advanced mathematics and reasoning.
The model also reports strengths in mathematical and reasoning accuracy. For example, see the following code:
The following is the result:
In this task, let's test Mistral's new Tekken tokenizer. Mistral claims that the tokenizer is two times and three times more efficient at compressing Korean and Arabic, respectively.
Here we use some text to translate:
We configure our message to instruct the model about Korean and Arabic translation:
Then we can configure the payload:
The following is the result:
The translation results demonstrate how the number of completion_tokens Usage is significantly reduced, even for tasks that are typically token-intensive, such as translations involving languages such as Korean and Arabic. This improvement is possible thanks to the optimizations provided by the Tekken tokenizer. This reduction is particularly valuable for token-intensive applications, including summarization, language generation, and multi-turn conversations. By improving token efficiency, Tekken's tokenizer allows more tasks to be handled within the same resource constraints, making it an invaluable tool for optimizing workflows where token usage directly impacts performance and cost. .
Clean
Once you have finished running the notebook, be sure to delete any resources you created in the process to avoid additional billing. Use the following code:
Conclusion
In this post, we show you how to get started with Mistral NeMo Base and Instruct in SageMaker Studio and deploy the model for inference. Since the base models are pre-trained, they can help reduce training and infrastructure costs and allow customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
For more Mistral resources on AWS, see the Mistral-on-AWS GitHub Repository.
About the authors
 Nithiyan Vijayaswaran is a solutions architect specializing in generative ai on the AWS Third Party Model Science team. His area of focus is Generative ai and AWS ai Accelerators. He has a Bachelor's degree in Computer Science and Bioinformatics.
Nithiyan Vijayaswaran is a solutions architect specializing in generative ai on the AWS Third Party Model Science team. His area of focus is Generative ai and AWS ai Accelerators. He has a Bachelor's degree in Computer Science and Bioinformatics.
 Preston Tuggle is a specialized Senior Solutions Architect working on generative ai.
Preston Tuggle is a specialized Senior Solutions Architect working on generative ai.
 shane rai is a Senior Generative ai Specialist with the AWS Worldwide Specialist Organization (WWSO). It works with customers across industries to solve their most pressing and innovative business needs using the broad range of cloud-based ai/ML services provided by AWS, including model offerings from top-tier base model providers.
shane rai is a Senior Generative ai Specialist with the AWS Worldwide Specialist Organization (WWSO). It works with customers across industries to solve their most pressing and innovative business needs using the broad range of cloud-based ai/ML services provided by AWS, including model offerings from top-tier base model providers.






{kind=link}