 NEWSLETTER
NEWSLETTER
Today, we are pleased to announce that Mistral 7B base models, developed by Mistral ai, are available for customers through Amazon SageMaker JumpStart to deploy with a single click to run inference. With 7 billion parameters, Mistral 7B can be easily customized and quickly deployed. You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models to get you started quickly with ML. In this post, we explain how to discover and implement the Mistral 7B model.
What is Mistral 7B?
Mistral 7B is a basic model developed by Mistral ai, which supports English text and code generation capabilities. It supports a variety of use cases, such as text summarization, classification, text completion, and code completion. To demonstrate the model’s easy customization, Mistral ai also released a Mistral 7B Instruct model for chat use cases, fine-tuned using a variety of publicly available conversation data sets.
Mistral 7B is a transformative model and uses pooled query attention and sliding window attention to achieve faster inference (low latency) and handle longer sequences. Group query attention is an architecture that combines multi-query and multi-head attention to achieve output quality close to multi-head attention and speed comparable to multi-query attention. Sliding window attention uses the stacked layers of a transformer to serve in the past beyond the window size to increase the length of the context. Mistral 7B has a context length of 8000 tokens, demonstrates low latency and high throughput, and has strong performance compared to larger model alternatives, providing low memory requirements in a 7B model size. The model is available under permission. apache 2.0 licensefor unrestricted use.
What is SageMaker JumpStart?
With SageMaker JumpStart, machine learning professionals can choose from a growing list of top-performing base models. Machine learning professionals can deploy basic models to dedicated Amazon SageMaker instances within a network-isolated environment and customize models using SageMaker for model training and deployment.
You can now discover and deploy Mistral 7B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, allowing you to derive model performance and MLOps controls with SageMaker functions such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger or container registries. The model is deployed in a secure AWS environment and under the controls of your VPC, which helps ensure data security.
Discover models
You can access the basic Mistral 7B models through SageMaker JumpStart in the SageMaker Studio user interface and the SageMaker Python SDK. In this section, we go over how to discover models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single, web-based visual interface where you can access tools specifically designed to perform all ML development steps, from data preparation to authoring, training, and deployment. implementation of your ML models. For more details about getting started and setting up SageMaker Studio, see Amazon SageMaker Studio.
In SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and pre-built solutions, at Pre-built and automated solutions.
From the SageMaker JumpStart home page, you can search for solutions, templates, notebooks, and other resources. You can find Mistral 7B in the Basic models: text generation carousel.
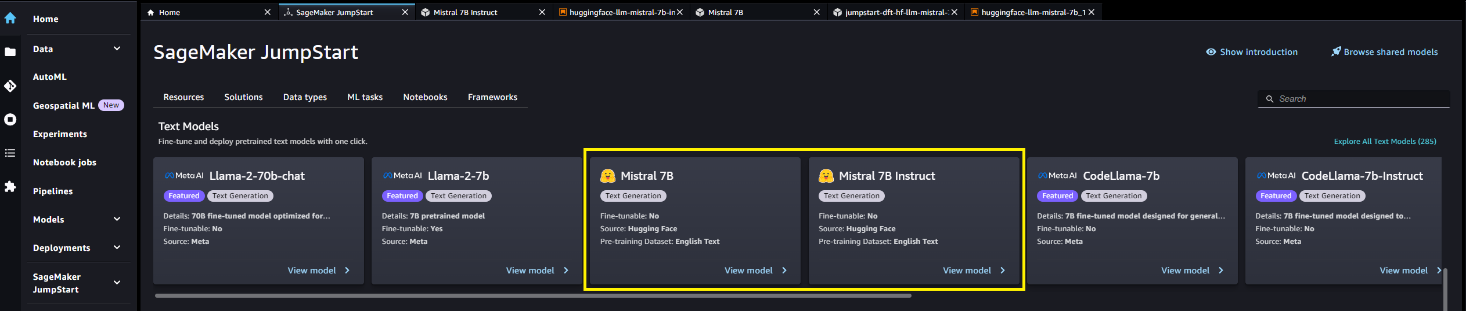
You can also find other model variants by choosing Explore all text models or searching for “Mistral”.
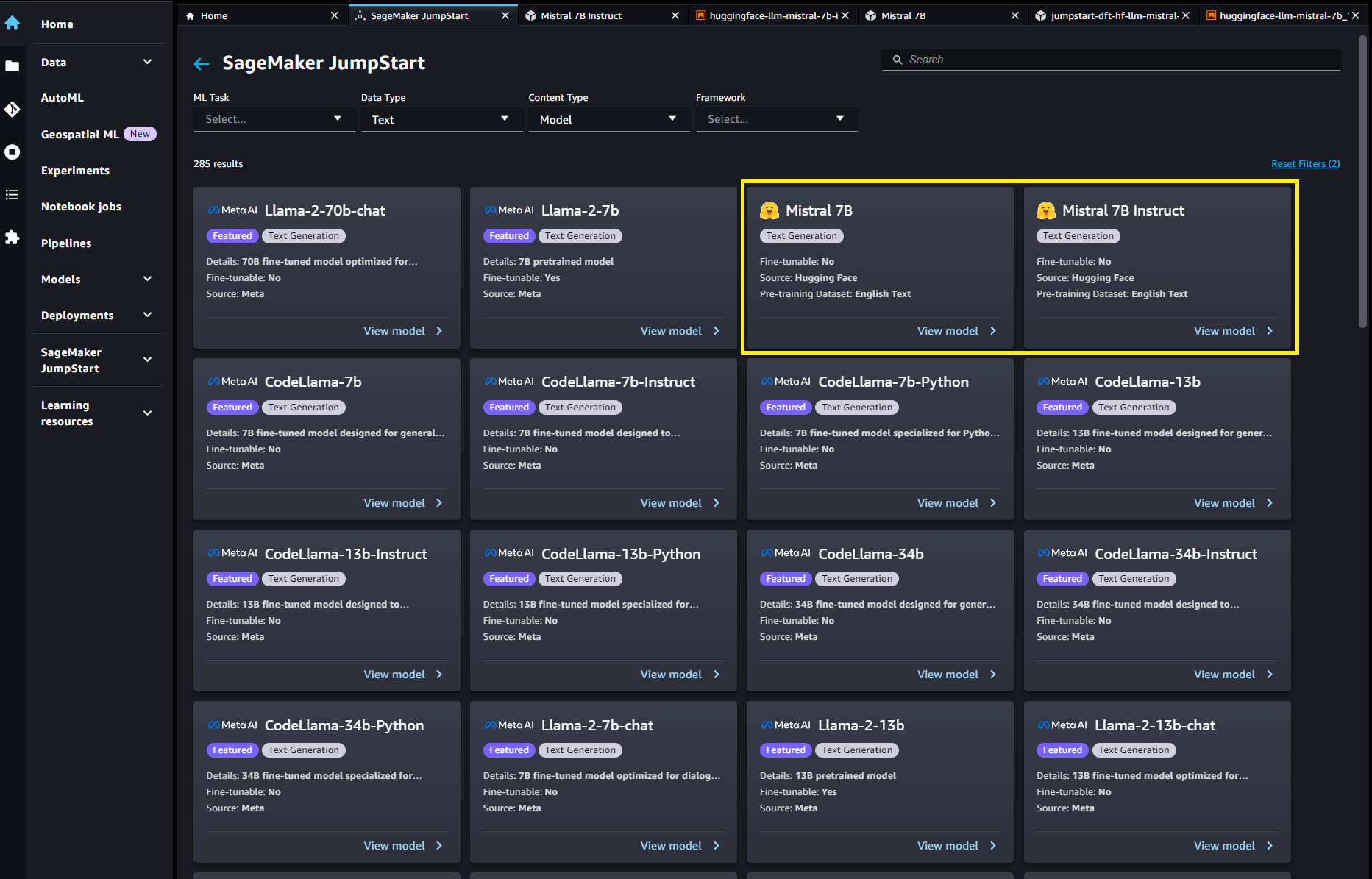
You can choose the model card to view details about the model, such as the license, the data used to train, and how to use it. You will also find two buttons, Deploy and open notebookwhich will help you use the model (the following screenshot shows the Deploy option).
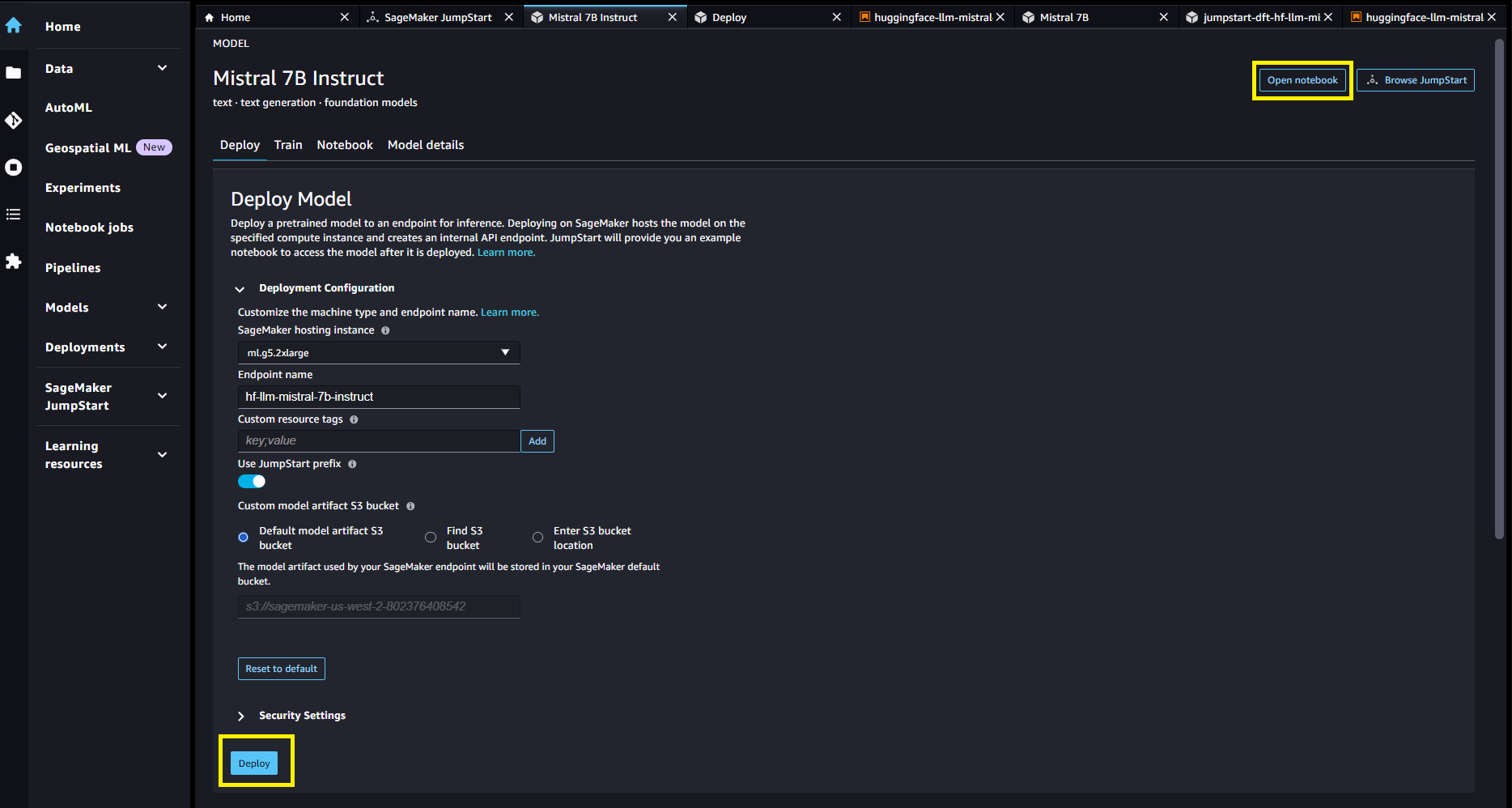
Deploy models
Deployment starts when you choose Deploy. Alternatively, you can implement via the example notebook that appears when you choose open notebook. The example notebook provides comprehensive guidance on how to implement the model for inference and resource cleansing.
To deploy using a laptop, we start by selecting the Mistral 7B model, specified by the model_id. You can deploy any of the selected models in SageMaker with the following code:
This deploys the model to SageMaker with default configurations, including the default instance type (ml.g5.2xlarge) and default VPC configurations. You can change these settings by specifying non-default values in JumpStartModel. Once deployed, you can run inference against the deployed endpoint via the SageMaker predictor:
Optimizing Deployment Configuration
Mistral models use the Text Generation Inference Models Service (TGI version 1.1). When deploying models with the TGI deep learning container (DLC), you can configure a variety of launcher arguments via environment variables when implementing your endpoint. To support the 8000 token context length of Mistral 7B models, SageMaker JumpStart has configured some of these parameters by default: we configure MAX_INPUT_LENGTH and MAX_TOTAL_TOKENS to 8191 and 8192, respectively. You can see the full list by inspecting its model object:
By default, SageMaker JumpStart does not block concurrent users via the environment variable. MAX_CONCURRENT_REQUESTS lower than the TGI default of 128. The reason is that some users may have typical workloads with small load context lengths and want high concurrency. Please note that the SageMaker TGI DLC supports multiple simultaneous users using continuous batching. When implementing your endpoint for your application, you might consider whether to set MAX_TOTAL_TOKENS either MAX_CONCURRENT_REQUESTS before deployment to provide the best performance for your workload:
Here, we show how the model’s performance may differ for your typical endpoint workload. In the following tables, you can see that small-sized queries (128 input words and 128 output tokens) perform quite well with a large number of concurrent users, achieving token throughput on the order of 1000 tokens per second. However, as the number of input words increases to 512 input words, the endpoint saturates its batching capacity (the number of concurrent requests it is allowed to process simultaneously), resulting in a plateau in performance. and significant latency degradations starting around 16 concurrent users. Finally, when multiple concurrent users query the endpoint with large input contexts (e.g. 6400 words) simultaneously, this performance plateau occurs relatively quickly, to the point where your SageMaker account will start to encounter timeouts. 60 second response time for your overloaded requests. .
| . | throughput (tokens/s) | ||||||||||
| concurrent users | 1 | 2 | 4 | 8 | sixteen | 32 | 64 | 128 | |||
| model | instance type | entry words | exit tokens | . | |||||||
| mistral-7b-instruct | ml.g5.2xlarge | 128 | 128 | 30 | 54 | 89 | 166 | 287 | 499 | 793 | 1030 |
| 512 | 128 | 29 | fifty | 80 | 140 | 210 | 315 | 383 | 458 | ||
| 6400 | 128 | 17 | 25 | 30 | 35 | — | — | — | — | ||
| . | p50 latency (ms/token) | ||||||||||
| concurrent users | 1 | 2 | 4 | 8 | sixteen | 32 | 64 | 128 | |||
| model | instance type | input words | exit tokens | . | |||||||
| mistral-7b-instruct | ml.g5.2xlarge | 128 | 128 | 32 | 33 | 3. 4 | 36 | 41 | 46 | 59 | 88 |
| 512 | 128 | 3. 4 | 36 | 39 | 43 | 54 | 71 | 112 | 213 | ||
| 6400 | 128 | 57 | 71 | 98 | 154 | — | — | — | — | ||
Inference and Example Indications
Mistral 7B
You can interact with a base Mistral 7B model like any standard text generation model, where the model processes an input sequence and generates the next predicted words in the sequence. The following is a simple example with multi-shot learning, where the model is given several examples and the final example response is generated with contextual knowledge of these previous examples:
Mistral Instruction 7B
The version adapted to the Mistral instructions accepts formatted instructions in which the conversation roles must begin with a user message and alternate between user and assistant. A simple user message may look like the following:
A multi-turn message would look like this:
This pattern is repeated during all the turns in the conversation.
In the following sections, we explore some examples using the Mistral 7B Instruct model.
Knowledge Recovery
The following is an example of knowledge retrieval:
Answer to broad context questions
To demonstrate how to use this model to support long input contexts, the following example incorporates a passage titled “Rats” by Robert Sullivan (reference), from the MCAS Grade 10 English Language Arts Reading Comprehension Test to Cue Instruction and asks the model a directed question about the text:
Mathematics and reasoning
Mistral models also report strengths in mathematical precision. Mistral can provide understanding such as the following mathematical logic:
Coding
The following is an example of an encoding message:
Clean
Once you have finished running the notebook, be sure to delete all the resources you created in the process so that your billing stops. Use the following code:
Conclusion
In this post, we show you how to get started with Mistral 7B in SageMaker Studio and deploy the model for inference. Since the base models are pre-trained, they can help reduce training and infrastructure costs and allow customization for your use case. Visit Amazon SageMaker JumpStart now to get started.
Resources
About the authors
 Dr. Kyle Ulrich is an applied scientist on the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, non-parametric Bayesian processes, and Gaussian processes. His PhD is from Duke University and he has published articles in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an applied scientist on the Amazon SageMaker JumpStart team. His research interests include scalable machine learning algorithms, computer vision, time series, non-parametric Bayesian processes, and Gaussian processes. His PhD is from Duke University and he has published articles in NeurIPS, Cell, and Neuron.
 Dr Ashish Khaitan He is a Senior Applied Scientist at Amazon SageMaker JumpStart and helps develop machine learning algorithms. He earned his doctorate from the University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published numerous papers at NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr Ashish Khaitan He is a Senior Applied Scientist at Amazon SageMaker JumpStart and helps develop machine learning algorithms. He earned his doctorate from the University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published numerous papers at NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Vivek Singh is a product manager for Amazon SageMaker JumpStart. It focuses on enabling customers to incorporate SageMaker JumpStart to simplify and accelerate their machine learning journey to build generative ai applications.
Vivek Singh is a product manager for Amazon SageMaker JumpStart. It focuses on enabling customers to incorporate SageMaker JumpStart to simplify and accelerate their machine learning journey to build generative ai applications.
 Roy Allela is a Senior Solutions Architect specializing in ai/ML at AWS based in Munich, Germany. Roy helps AWS customers (from small startups to large enterprises) efficiently train and deploy large language models on AWS. Roy is passionate about computational optimization problems and improving the performance of ai workloads.
Roy Allela is a Senior Solutions Architect specializing in ai/ML at AWS based in Munich, Germany. Roy helps AWS customers (from small startups to large enterprises) efficiently train and deploy large language models on AWS. Roy is passionate about computational optimization problems and improving the performance of ai workloads.






{kind=link}