 NEWSLETTER
NEWSLETTER
The intelligibility and naturalness of synthesized speech have improved due to recent developments in text-to-speech systems. Large-scale TTS systems have been created for multi-speaker settings, and some TTS systems have reached a quality equivalent to single-speaker recordings. Despite these advancements, modeling voice variability is still difficult since different ways of saying the same phrase can communicate additional information, such as emotion and tone. Traditional TTS techniques frequently rely on speaker information or speech prompts to simulate the variability in voice. Still, these techniques are not user-friendly because the speaker ID is pre-defined, and the appropriate speech prompt is difficult to discover or doesn’t exist.
A more promising approach for modeling voice variability is to utilize text prompts that specify voice features since natural language is a handy interface for users to convey their intent on voice production. This strategy makes it simple to create voices using text prompts. TTS systems based on text prompts are typically trained using a dataset of speech and the text prompt that corresponds to it. The text prompt describing the variability or style of the voice is used to condition how the model generates the voice.
Text prompt TTS systems continue to face two main difficulties:
• One-to-Many Challenge: Because voice quality varies from person to person, it is hard for written instructions to represent all speech aspects accurately. Different voice samples may ineluctably correlate to the same prompt. The one-to-many phenomena make TTS model training more challenging and can result in over-fitting or mode collapse. As far as they know, no procedures have been created expressly to address the one-to-many problem in TTS systems based on text prompts.
• Data-Scale Challenge: Since text prompts are uncommon on the internet, compiling a dataset of text prompts defining the voice isn’t easy.
As a result, vendors are hired to create prompts, which is both expensive and time-consuming. The prompt datasets are typically tiny or private, making it difficult to do further research on prompt-based TTS systems. In their work, they provide PromptTTS 2, which makes a variation network proposal to model the voice variability information of speech not captured by the prompts. It uses the big language model to produce high-quality prompts to overcome the challenges above. They suggest a variation network to anticipate the missing information about voice variability from the text prompt for the one-to-many challenge. The reference speech, thought to include all information on voice variability, is used to train the variation network.
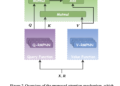
A text prompt encoder for text prompts, a reference speech encoder for reference speech, and a TTS module to synthesize speech based on the representations retrieved by the text prompt encoder and reference speech encoder make up the TTS model in PromptTTS 2. Based on the immediate representation from text prompt encoder 3, a variation network is trained to predict the reference representation from the reference voice encoder. They may modify the qualities of synthesized speech by using the diffusion model in the variation network to select diverse information about voice variability from Gaussian noise conditioned on text prompts, giving users more freedom when producing voices.
Researchers from Microsoft suggest a pipeline to automatically create text prompts for speech using a speech understanding model to recognize voice characteristics from speech and a big language model to construct text prompts depending on recognition results to address the data-scale difficulty. In particular, they use a speech understanding model to identify the attribute values for each speech sample inside a speech dataset to describe the voice from various features. The text prompt is then created by putting these phrases together, with each attribute’s description given in its sentence. In contrast to earlier studies, which relied on vendors to construct and combine phrases, PromptTTS 2 uses massive language models that have proven capable of performing a range of tasks at a level comparable to that of a person.
They give LLM instructions to write excellent prompts that include the qualities and connect the phrases into a thorough prompt. Thanks to this completely automated workflow, there is no longer any need for human intervention in prompt authoring. The following is a summary of this paper’s contributions:
• To solve the one-to-many problem in text prompt-based TTS systems, they build a diffusion model-based variation network to describe the voice variability not covered by the text prompt. The voice variability may be managed by selecting samples from various Gaussian noises conditioned on the text prompt during inference.
• They build and publish a text prompt dataset produced by a pipeline for text prompt creation and a big language model. The pipeline lessens dependency on providers by producing prompts of high quality.
• Using 44K hours of speech data, they test PromptTTS 2 on a sizable speech dataset. According to experimental findings, PromptTTS 2 surpasses earlier studies in producing voices that more closely match the text prompt while supporting limiting vocal variability by sampling from Gaussian noise.
Check out the Paper and Samples. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
 The end of project management by humans (Sponsored)
The end of project management by humans (Sponsored) 




{kind=link}