 NEWSLETTER
NEWSLETTER
In the contemporary era marked by the dissemination of information on the Internet, search engines have become indispensable tools for locating and collecting knowledge. These digital platforms serve as navigational aids in the vast sea of information, allowing people to access specific details efficiently and accurately. Users can initiate queries on various topics, from academic research to practical day-to-day queries. Search engines not only facilitate the discovery of information, but also play a critical role in organizing and prioritizing data based on relevance.
Modern search engines build on a complex foundation to fully utilize the valuable information found on search engine results pages (SERPs), including multimedia content, knowledge panels, related queries, direct answers, and snippets. highlights. This foundation consists of several parts, such as understanding user queries, obtaining data, sorting results into multiple stages, and answering queries.
Previously, these components were developed and tuned independently, often improving pre-trained language models such as BERT or T5 using task-specific data sets. A more flexible system is needed. It should be able to make a wide range of decisions and have adaptable interfaces. The importance of this type of system is growing over time.
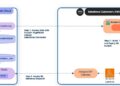
Accordingly, Microsoft researchers published a paper titled “Big Search Model: Redefining the Search Stack in the Age of LLM,” which presents a novel framework. By combining multiple components, this framework, also known as the large search model, envisions a transformation in the conventional search stack.
By simplifying and speeding up the complicated search process, this method improves search results. It uses a single way of modeling, customizing the large search model for different searches by giving it directions. The usual parts of search, like searching and organizing information to create the search engine results page (SERP), are still there. The research team calls this large search model a personalized large language model (LLM). It can handle different types of information tasks and you can tell it what to do using natural language prompts.
Additionally, the large search model can be adjusted to fit particular search situations, giving you flexibility. This customization occurs by fine-tuning the model with data specific to a given area, often available from commercial search engines. Importantly, this capability allows the model to use its knowledge for new tasks, even if it has not yet been directly trained. This process is known as zero-shot learning.
The research team provided real-world examples to support the effectiveness of the suggested model. Their model outperformed multiple dense robust retrievers and the conventional BM25 sparse retriever. The large search model, after being trained, performed better than the expected model and outperformed the baseline performance, demonstrating its competence.
The large search model constitutes a notable advance in search engines. Leveraging the adaptability and robust capabilities of large language models has the potential to elevate the quality of search results and simplify the complex search process.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join. our 32k+ ML SubReddit, Facebook community of more than 40,000 people, Discord channel, and Electronic newsletterwhere we share the latest news on ai research, interesting ai projects and more.
If you like our work, you’ll love our newsletter.
we are also in Telegram and WhatsApp.
Rachit Ranjan is a consulting intern at MarktechPost. He is currently pursuing his B.tech from the Indian Institute of technology (IIT), Patna. He is actively shaping his career in the field of artificial intelligence and data science and is passionate and dedicated to exploring these fields.
<!– ai CONTENT END 2 –>





{kind=link}