 NEWSLETTER
NEWSLETTER
El aprendizaje automático (ML) ayuda a las organizaciones a aumentar los ingresos, impulsar el crecimiento empresarial y reducir los costos mediante la optimización de las funciones comerciales centrales, como la previsión de la oferta y la demanda, la predicción de la pérdida de clientes, la calificación del riesgo crediticio, la fijación de precios, la predicción de envíos tardíos y muchas otras.
Los ciclos de desarrollo de ML convencionales tardan de semanas a muchos meses y requieren escasa comprensión de la ciencia de datos y habilidades de desarrollo de ML. Las ideas de los analistas de negocios para utilizar modelos de aprendizaje automático a menudo se acumulan durante mucho tiempo debido al ancho de banda y las actividades de preparación de datos del equipo de ingeniería y ciencia de datos.
En esta publicación, nos sumergimos en un caso de uso empresarial para una institución bancaria. Le mostraremos cómo un analista financiero o de negocios de un banco puede predecir fácilmente si el préstamo de un cliente estará totalmente pagado, cancelado o actualizado utilizando un modelo de aprendizaje automático que sea mejor para el problema comercial en cuestión. El analista puede obtener fácilmente los datos que necesita, usar lenguaje natural para limpiar y completar los datos faltantes y, finalmente, construir e implementar un modelo de aprendizaje automático que pueda predecir con precisión el estado del préstamo como resultado, todo sin necesidad de convertirse en una máquina. experto en aprendizaje para hacerlo. El analista también podrá crear rápidamente un panel de inteligencia empresarial (BI) utilizando los resultados del modelo ML a los pocos minutos de recibir las predicciones. Conozcamos los servicios que utilizaremos para que esto suceda.
amazon SageMaker Canvas es una interfaz visual basada en web para crear, probar e implementar flujos de trabajo de aprendizaje automático. Permite a los científicos de datos y a los ingenieros de aprendizaje automático interactuar con sus datos y modelos y visualizar y compartir su trabajo con otros con solo unos pocos clics.
SageMaker Canvas también se ha integrado con Data Wrangler, que ayuda a crear flujos de datos y a preparar y analizar sus datos. Integrada en Data Wrangler, está la opción Chat para preparación de datos, que le permite usar lenguaje natural para explorar, visualizar y transformar sus datos en una interfaz conversacional.
amazon Redshift es un servicio de almacenamiento de datos rápido, totalmente administrado y a escala de petabytes que hace que sea rentable analizar de manera eficiente todos sus datos utilizando sus herramientas de inteligencia empresarial existentes.
amazon QuickSight impulsa a las organizaciones basadas en datos con BI unificada a hiperescala. Con QuickSight, todos los usuarios pueden satisfacer diversas necesidades analíticas desde la misma fuente de verdad a través de paneles interactivos modernos, informes paginados, análisis integrados y consultas en lenguaje natural.
Descripción general de la solución
La arquitectura de la solución que sigue ilustra:
- Un analista de negocios que inicia sesión en SageMaker Canvas.
- El analista de negocios se conecta al almacén de datos de amazon Redshift y extrae los datos deseados en SageMaker Canvas para su uso.
- Le decimos a SageMaker Canvas que cree un modelo de ML de análisis predictivo.
- Una vez creado el modelo, obtenga resultados de predicción por lotes.
- Envíe los resultados a QuickSight para que los usuarios los analicen más a fondo.
Requisitos previos
Antes de comenzar, asegúrese de cumplir con los siguientes requisitos previos:
- Una cuenta y un rol de AWS con privilegios de AWS Identity and Access Management (IAM) para implementar los siguientes recursos:
- Conocimientos básicos de un editor de consultas SQL.
Configurar el clúster de amazon Redshift
Hemos creado una plantilla de CloudFormation para configurar el clúster de amazon Redshift.
- Implemente la plantilla de Cloudformation en su cuenta.

- Ingrese un nombre de pila, luego elija Próximo dos veces y mantener el resto de parámetros por defecto.
- En la página de revisión, desplácese hacia abajo hasta Capacidades sección y seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elegir Crear pila.
La pila funcionará durante 10 a 15 minutos. Una vez finalizado, puede ver las salidas de las pilas principales y anidadas como se muestra en las siguientes figuras:
Pila principal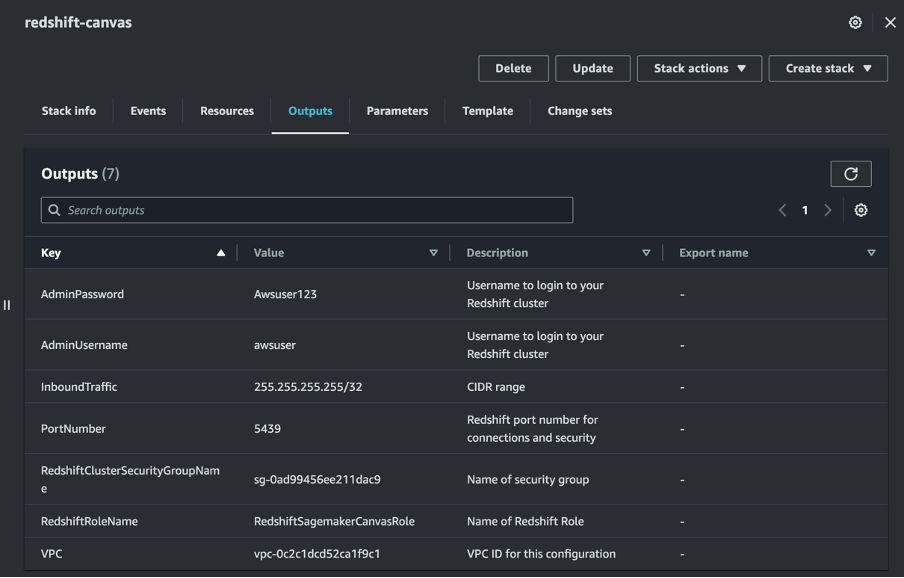
pila anidada 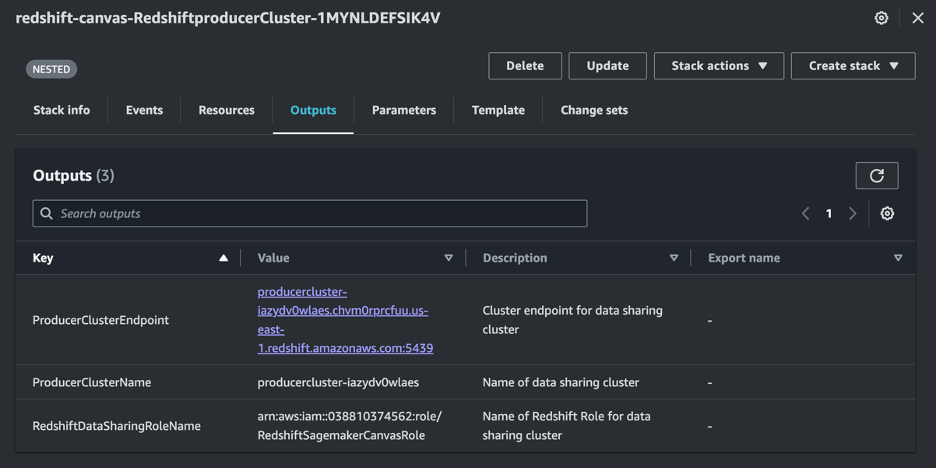
Datos de muestra
Utilizará un conjunto de datos disponible públicamente que AWS aloja y mantiene en nuestro propio depósito S3 como un taller para clientes bancarios y sus préstamos que incluye datos demográficos de los clientes y condiciones de préstamo.
Pasos de implementación
Cargar datos en el clúster de amazon Redshift
- Conéctese a su clúster de amazon Redshift mediante Query Editor v2. Para navegar al editor de consultas v2 de amazon Redshift, siga los pasos Abrir el editor de consultas v2.
- Cree una tabla en su clúster de amazon Redshift utilizando el siguiente comando SQL:
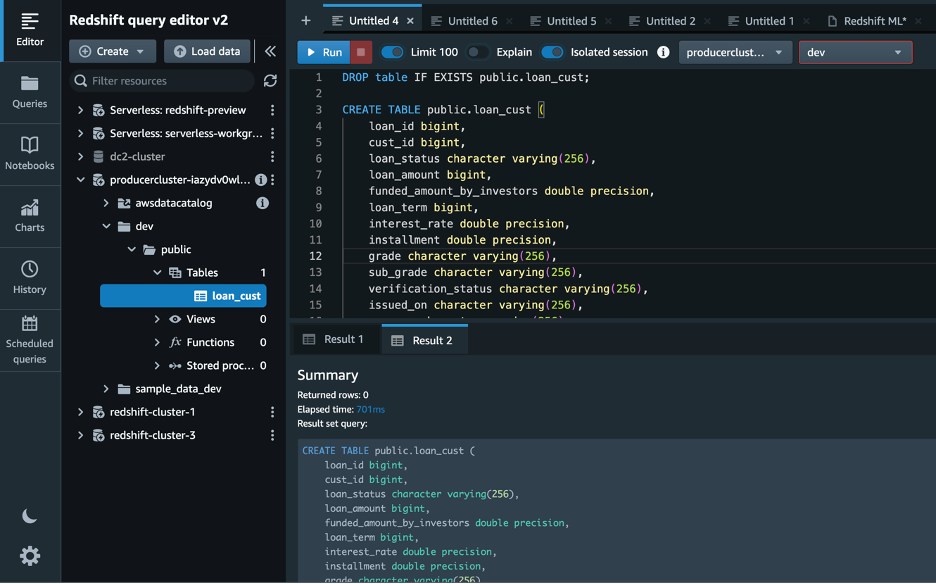
- Cargar datos en el
loan_custtabla usando la siguienteCOPYdominio: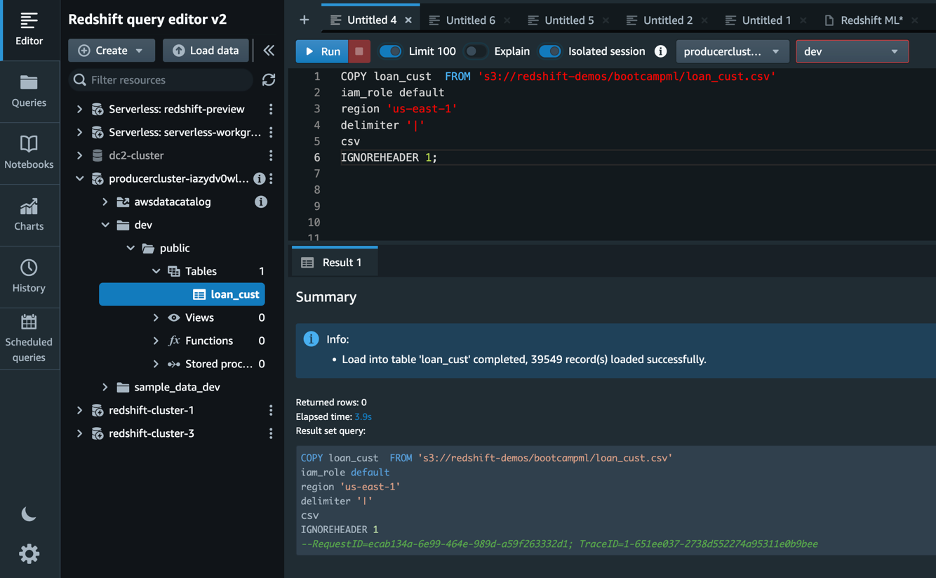
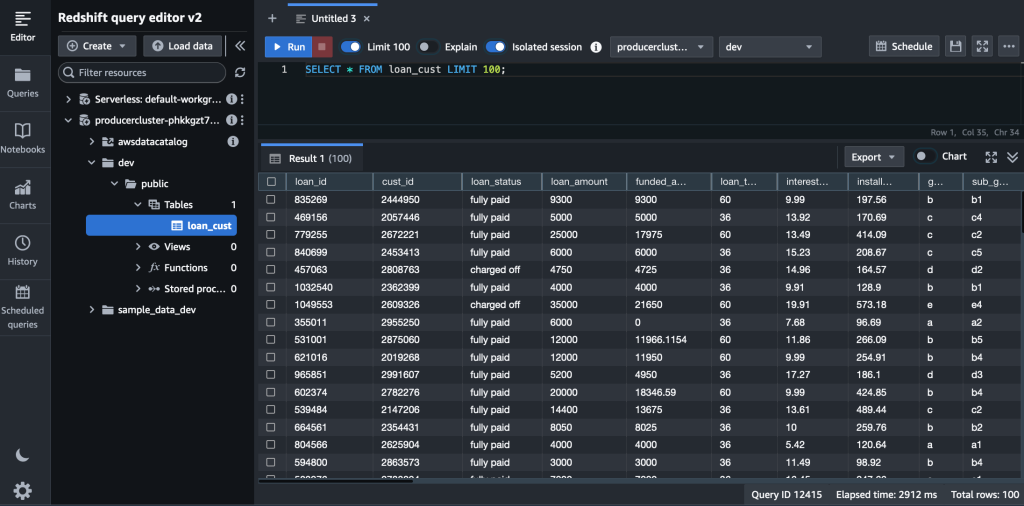
- Consulta la tabla para ver cómo se ven los datos:
Configurar chat para datos
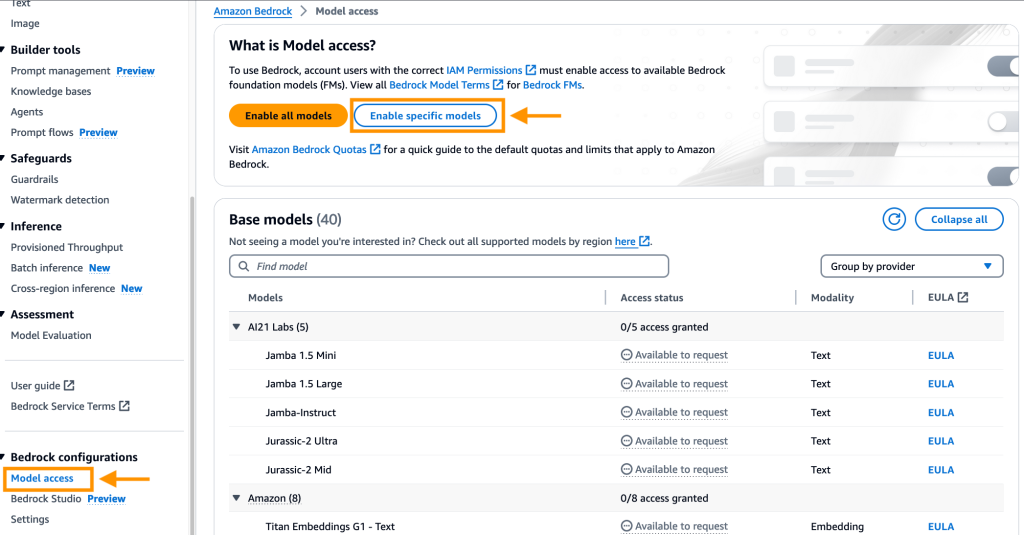
- Para utilizar la opción de chat para datos en Sagemaker Canvas, debe habilitarla en amazon Bedrock.
- Abra la Consola de administración de AWS, vaya a amazon Bedrock y elija Acceso al modelo en el panel de navegación.
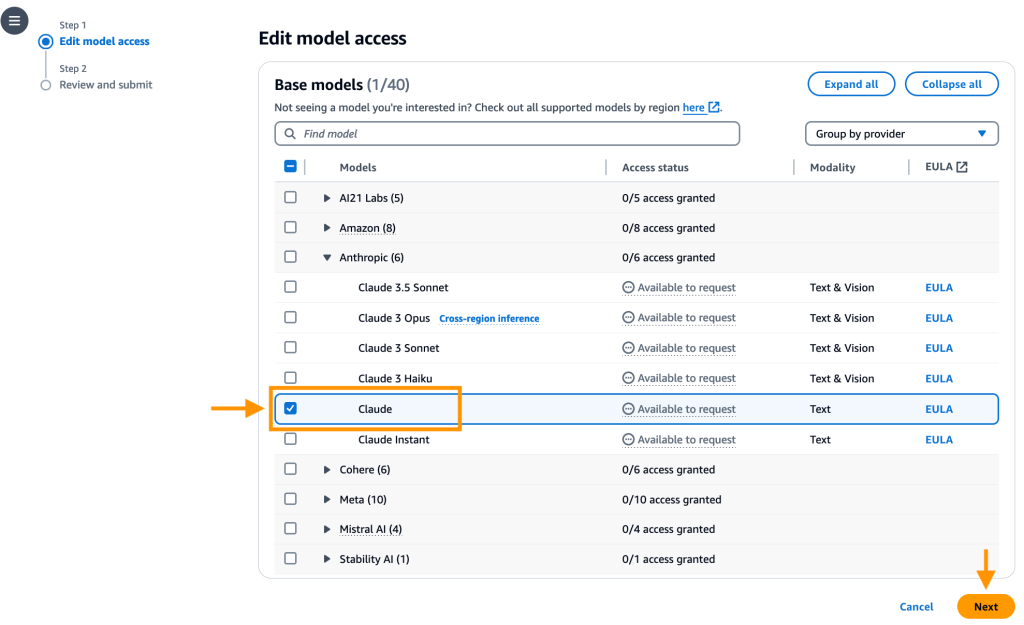
- Elegir Habilitar modelos específicosbajo antrópicoseleccionar claudio y seleccione Próximo.
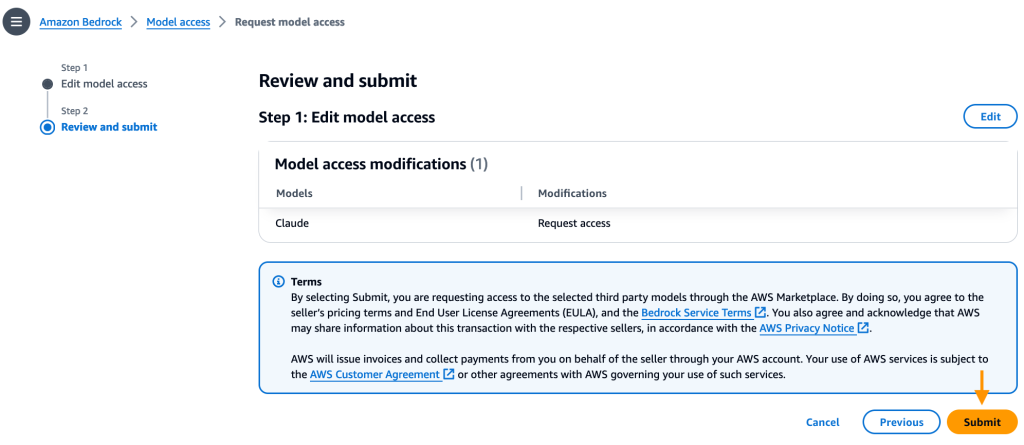
- Revise la selección y haga clic Entregar.
- Abra la Consola de administración de AWS, vaya a amazon Bedrock y elija Acceso al modelo en el panel de navegación.
- Navegue al servicio amazon SageMaker desde la consola de administración de AWS, seleccione Lienzo y haga clic en Abrir lienzo.
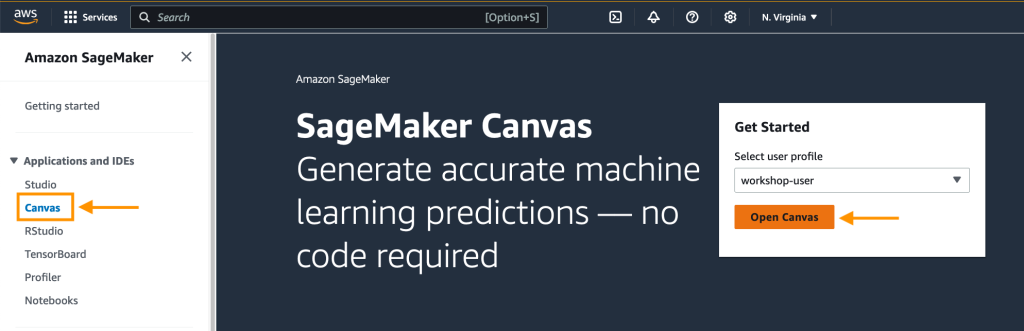
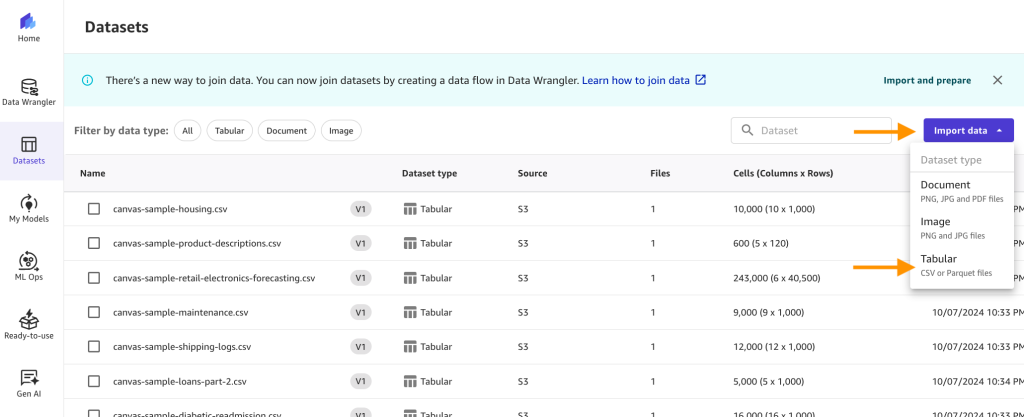
- Elegir Conjuntos de datos en el panel de navegación y luego elija la opción Importar datos menú desplegable y seleccione Tabular.
- Para Nombre del conjunto de datosingresar
redshift_loandatay elige Crear.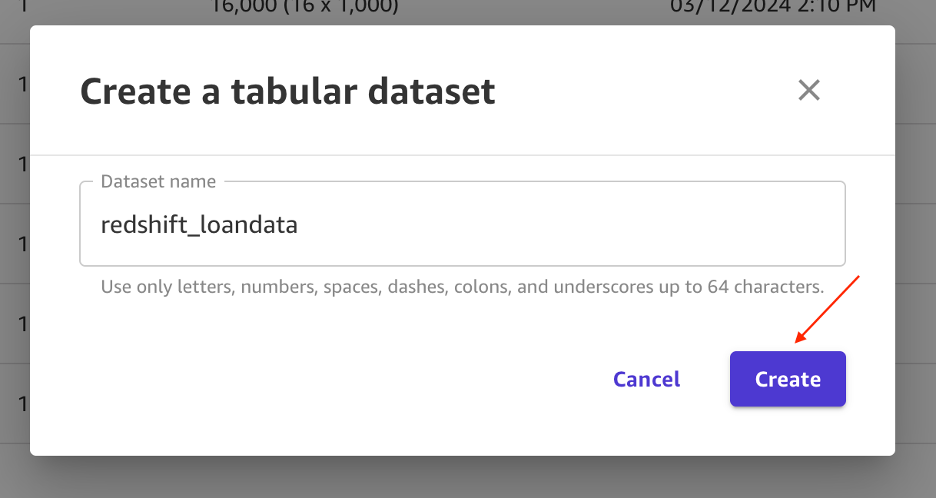
- En la página siguiente, elija Fuente de datos y seleccione corrimiento al rojo como fuente. Bajo corrimiento al rojoseleccionar + Agregar conexión.
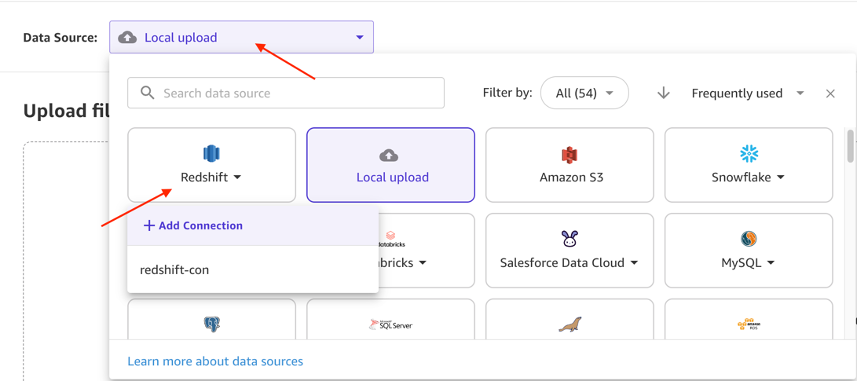
- Ingrese los siguientes detalles para establecer su conexión de amazon Redshift:
- Identificador de clúster: Copie el
ProducerClusterNamede las salidas de la pila anidada de CloudFormation. - Puede consultar la captura de pantalla anterior para Pila anidadadonde encontrará la salida del identificador del clúster.
- Nombre de la base de datos: Ingresar
dev. - Usuario de base de datos: Ingresar
awsuser. - Descargar ARN de rol de IAM: Copie el
RedshiftDataSharingRoleNamede las salidas de la pila anidada. - Nombre de conexión: Ingresar
MyRedshiftCluster. - Elegir Agregar conexión.
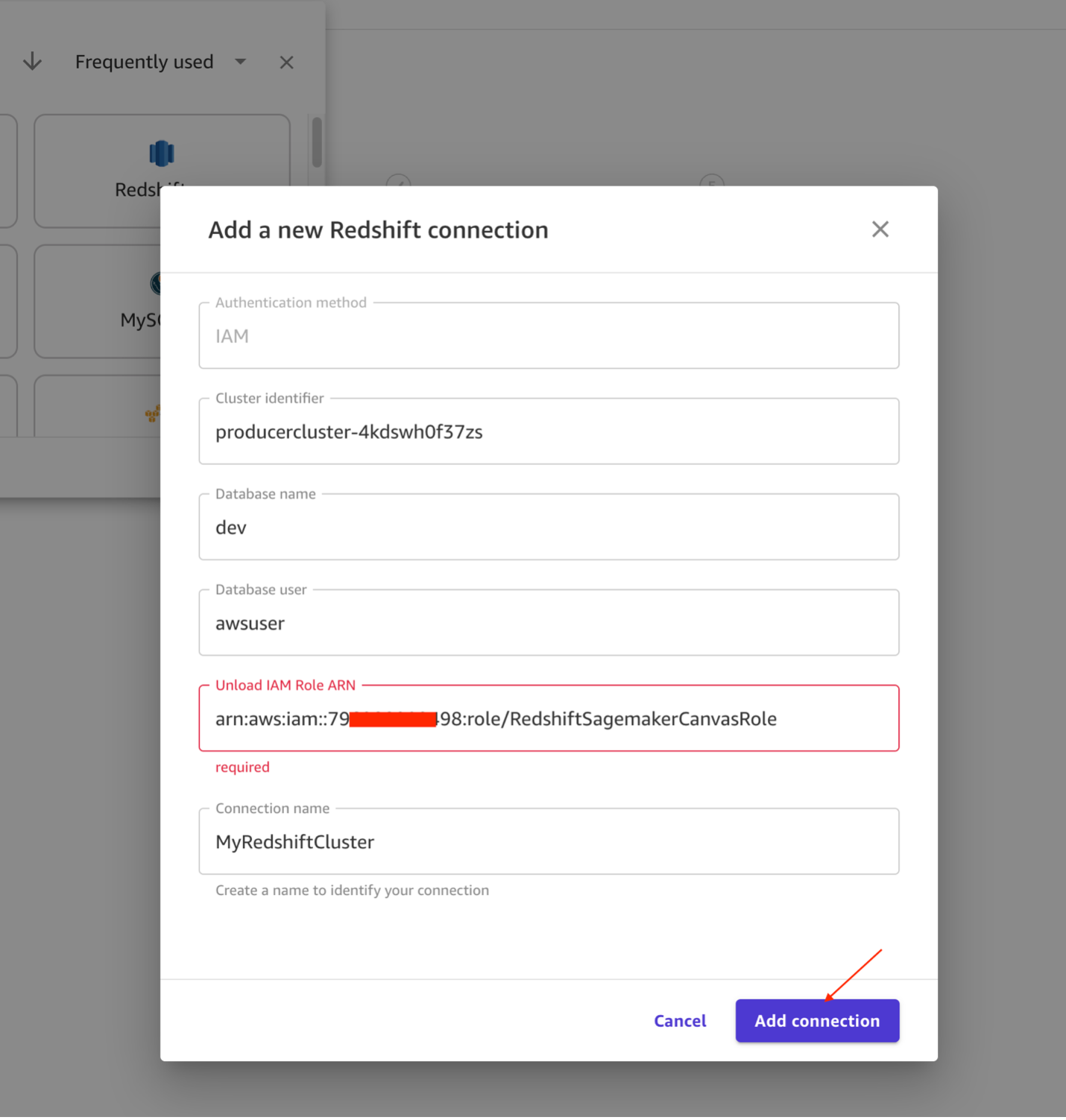
- Identificador de clúster: Copie el
- Una vez creada la conexión, expanda el
publicesquema, arrastre elloan_custtabla en el editor y elija Crear conjunto de datos.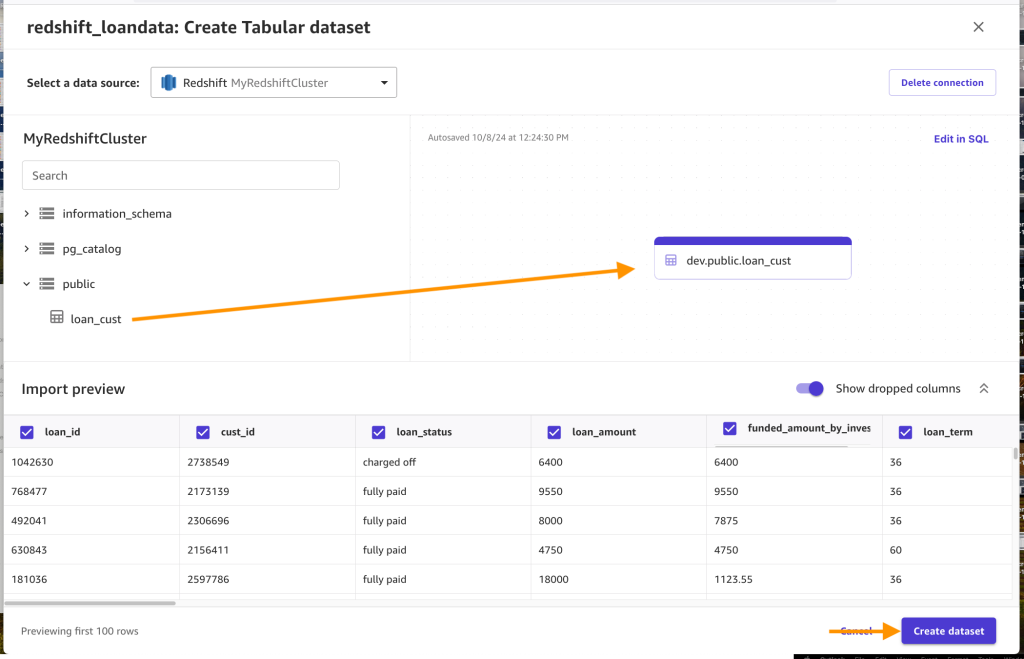
- Elige el
redshift_loandataconjunto de datos y elegir Crear un flujo de datos.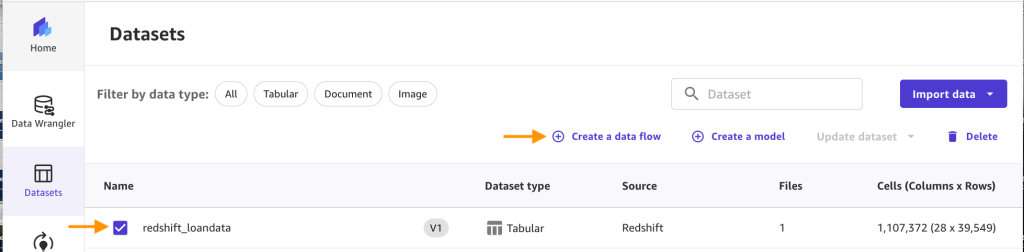
- Ingresar
redshift_flowpor el nombre y elegir Crear.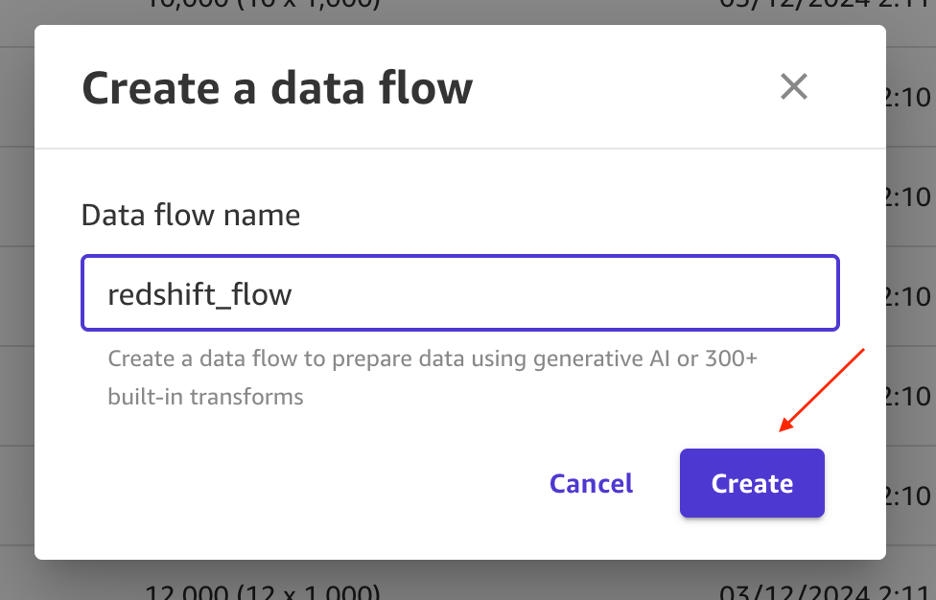
- Después de crear el flujo, elija Chat para preparación de datos.
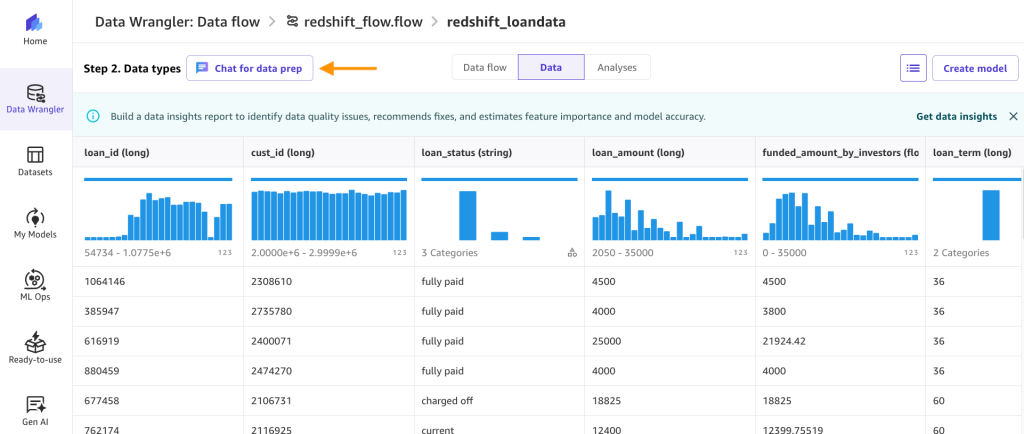
- En el cuadro de texto, ingrese
summarize my datay elige el ejecutar flecha.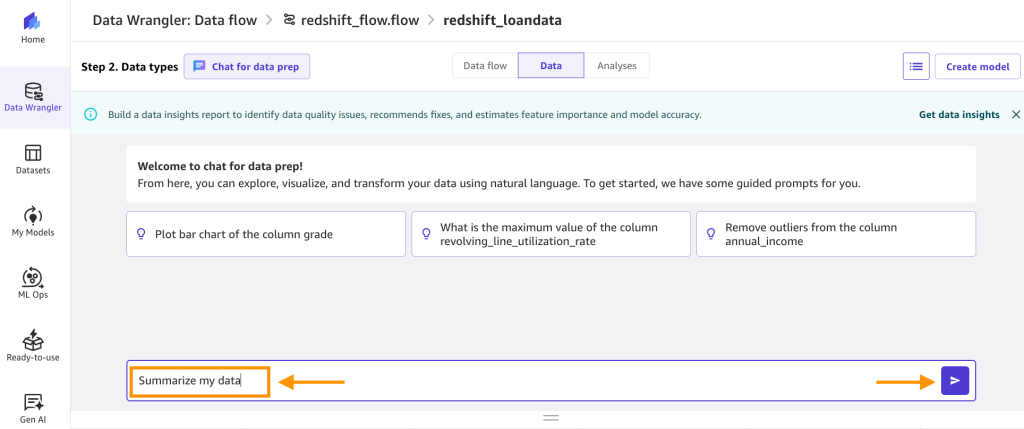
- La salida debería verse similar a la siguiente:

- Ahora puedes usar lenguaje natural para preparar el conjunto de datos. Ingresar
Drop ssn and filter for ages over 17y haga clic en el ejecutar flecha. Verá que pudo realizar ambos pasos. También puede ver el código PySpark que ejecutó. Para agregar estos pasos a medida que se transforma el conjunto de datos, elija Añadir a pasos.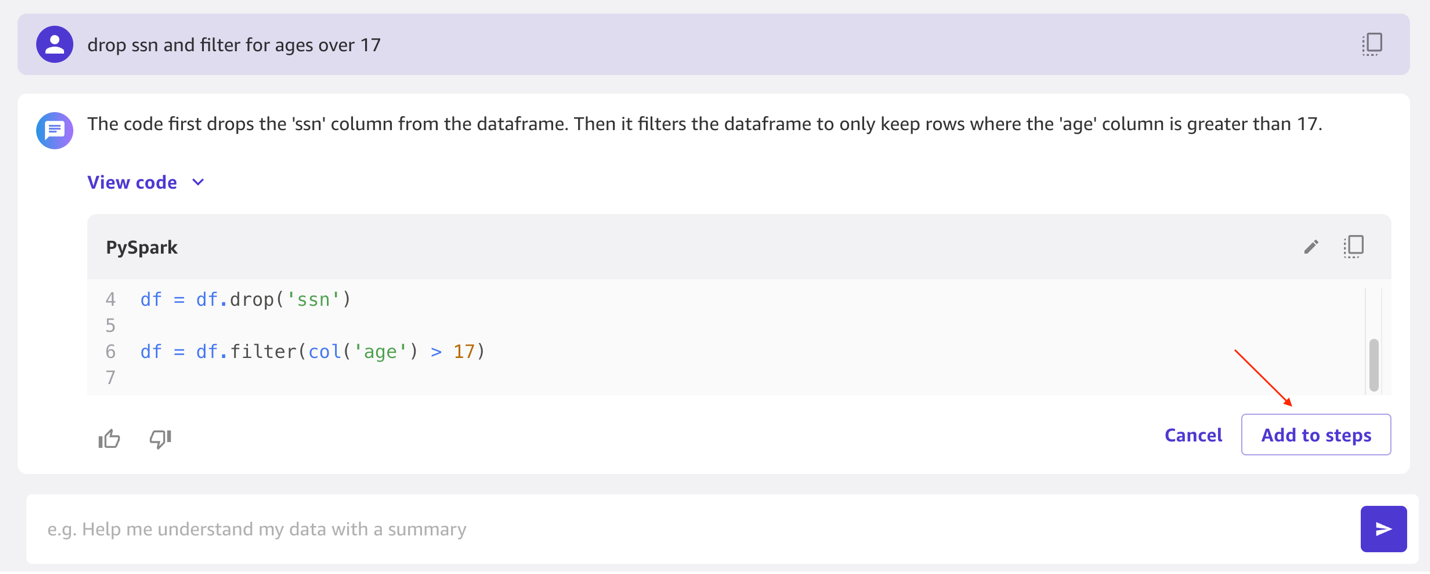
- Cambie el nombre del paso a
drop ssn and filter age > 17elegir Actualizary luego elija Crear modelo.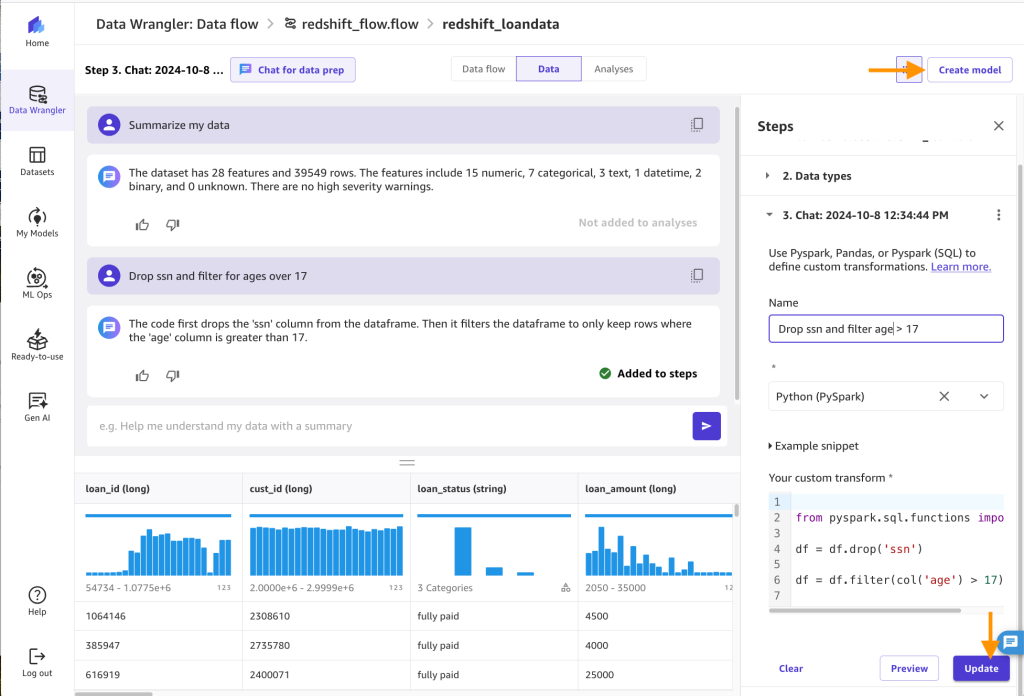
- Exportar datos y crear modelo: Ingresar
loan_data_forecast_datasetpara el Nombre del conjunto de fechaspara nombre del modelo, ingresarloan_data_forecastpara Tipo de problema, selectoPredictive analysispara la columna Destino, seleccioneloan_statusy haga clic Exportar y crear modelo..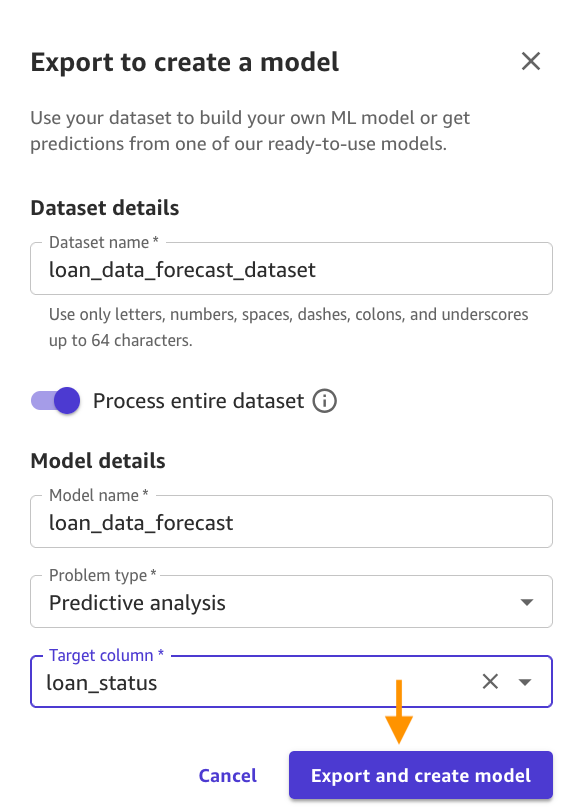
- Verifique que esté seleccionada la columna de destino correcta y el tipo de modelo y haga clic en Construcción rápida.
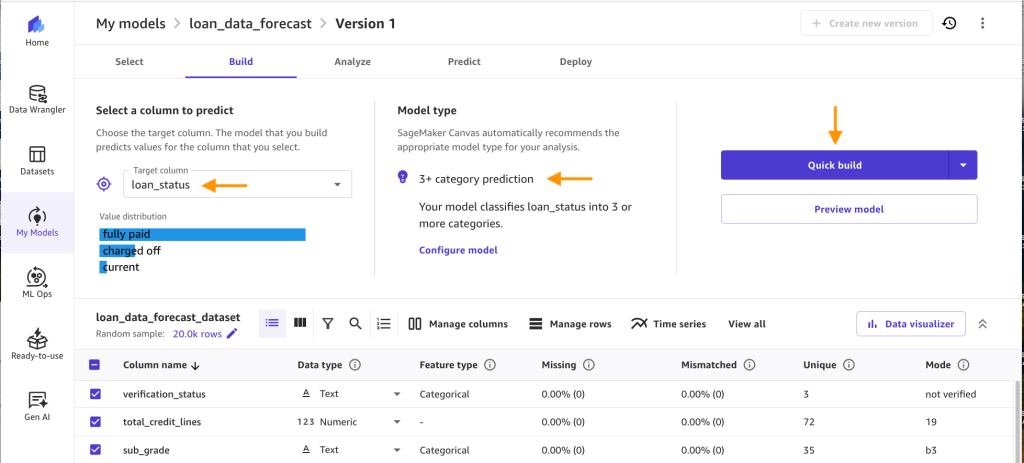
- Ahora se está creando el modelo. Por lo general, tarda entre 14 y 20 minutos, según el tamaño de su conjunto de datos.
- Una vez que el modelo haya completado el entrenamiento, se le dirigirá al Analizar pestaña. Allí puede ver la precisión promedio de la predicción y el impacto de la columna en el resultado de la predicción. Tenga en cuenta que sus números pueden diferir de los que ve en la siguiente figura, debido a la naturaleza estocástica del proceso de ML.
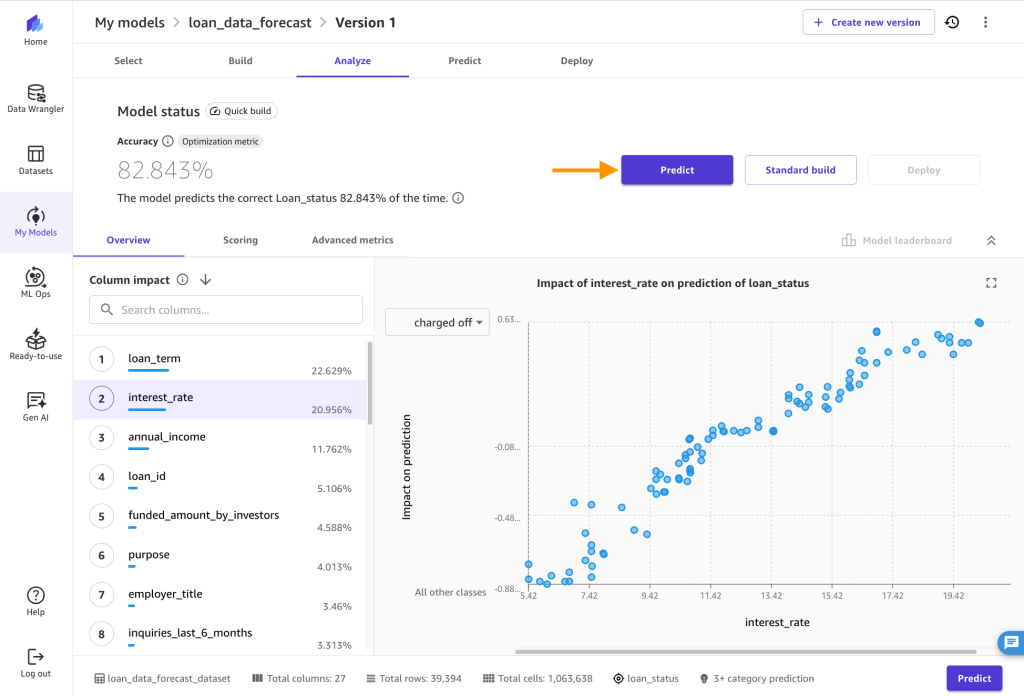
Utilice el modelo para hacer predicciones.
- Ahora usemos el modelo para hacer predicciones sobre el estado futuro de los préstamos. Elegir Predecir.

- Bajo Elija el tipo de predicciónseleccionar Predicción por lotesluego seleccione Manual.
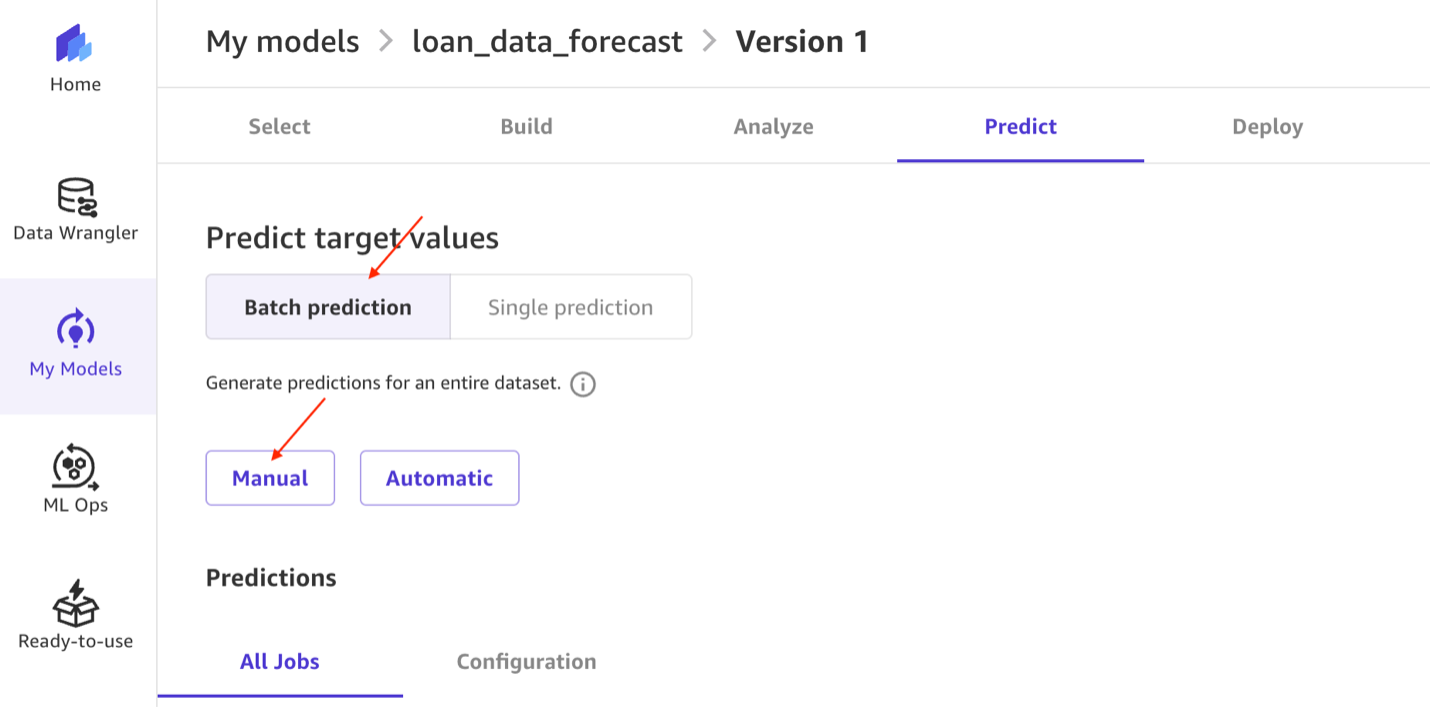
- Luego seleccione préstamo_datos_forecast_dataset de la lista de conjuntos de datos y haga clic en Generar predicciones.
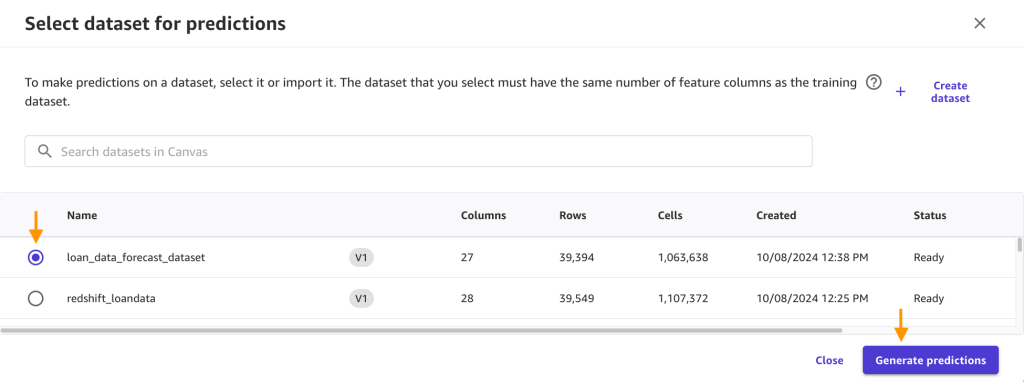
- Verá lo siguiente una vez que se complete la predicción por lotes. Haga clic en el menú de ruta de navegación junto al Listo estado y haga clic en Avance para ver los resultados.
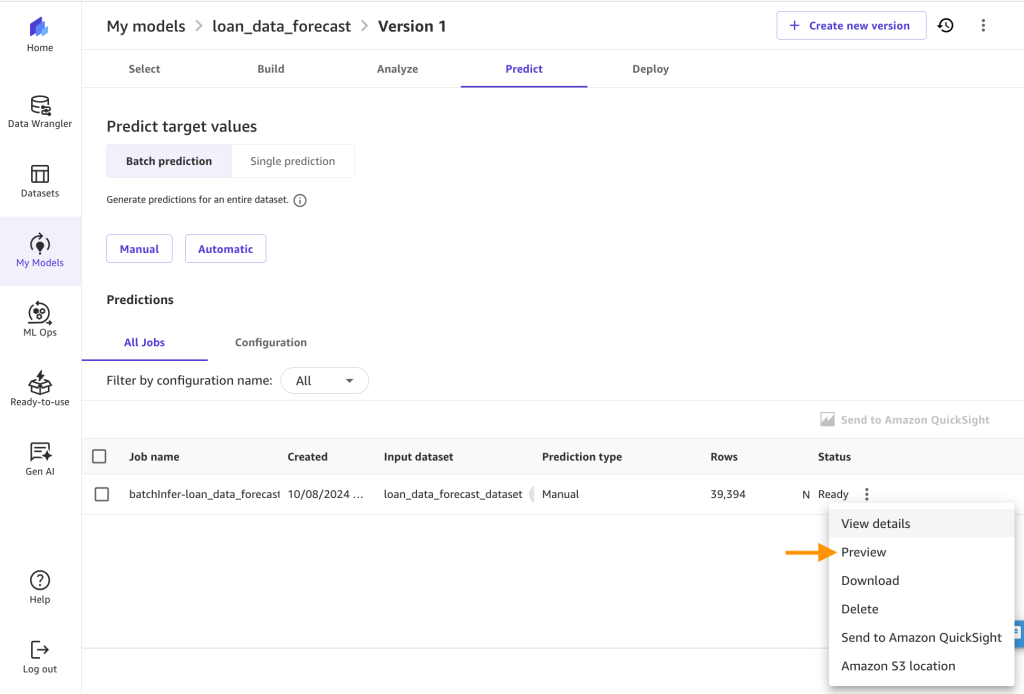
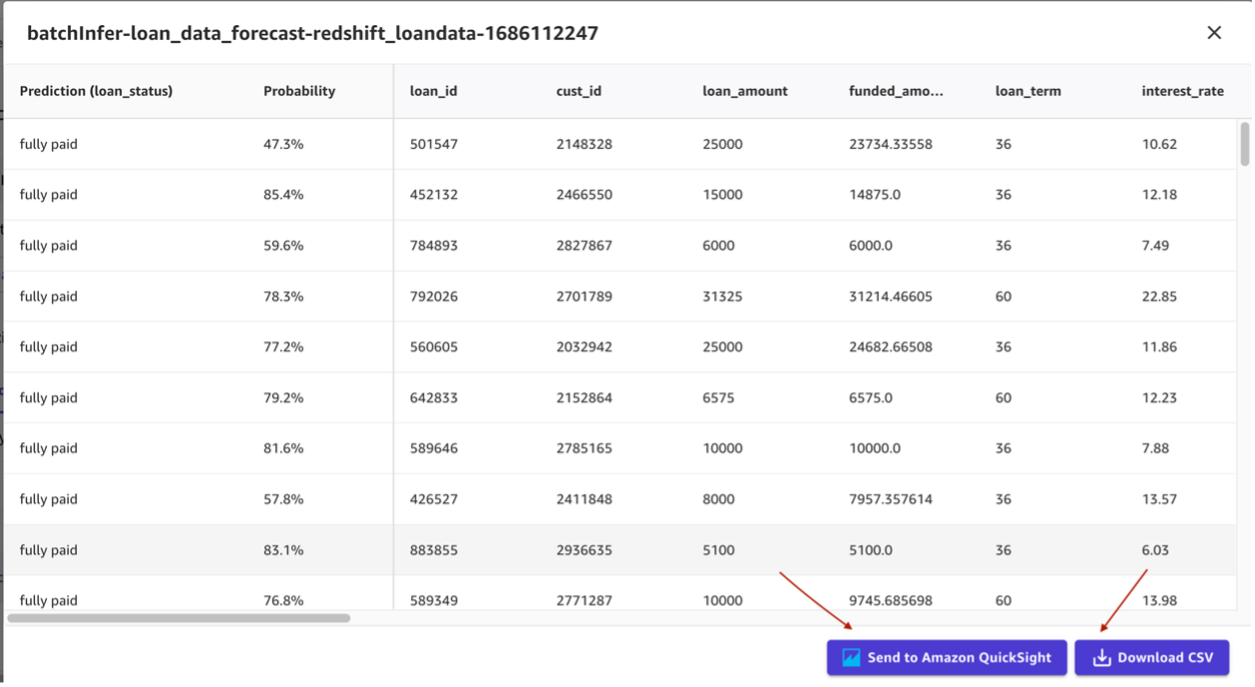
- Ahora puedes ver las predicciones y descargarlas como CSV.
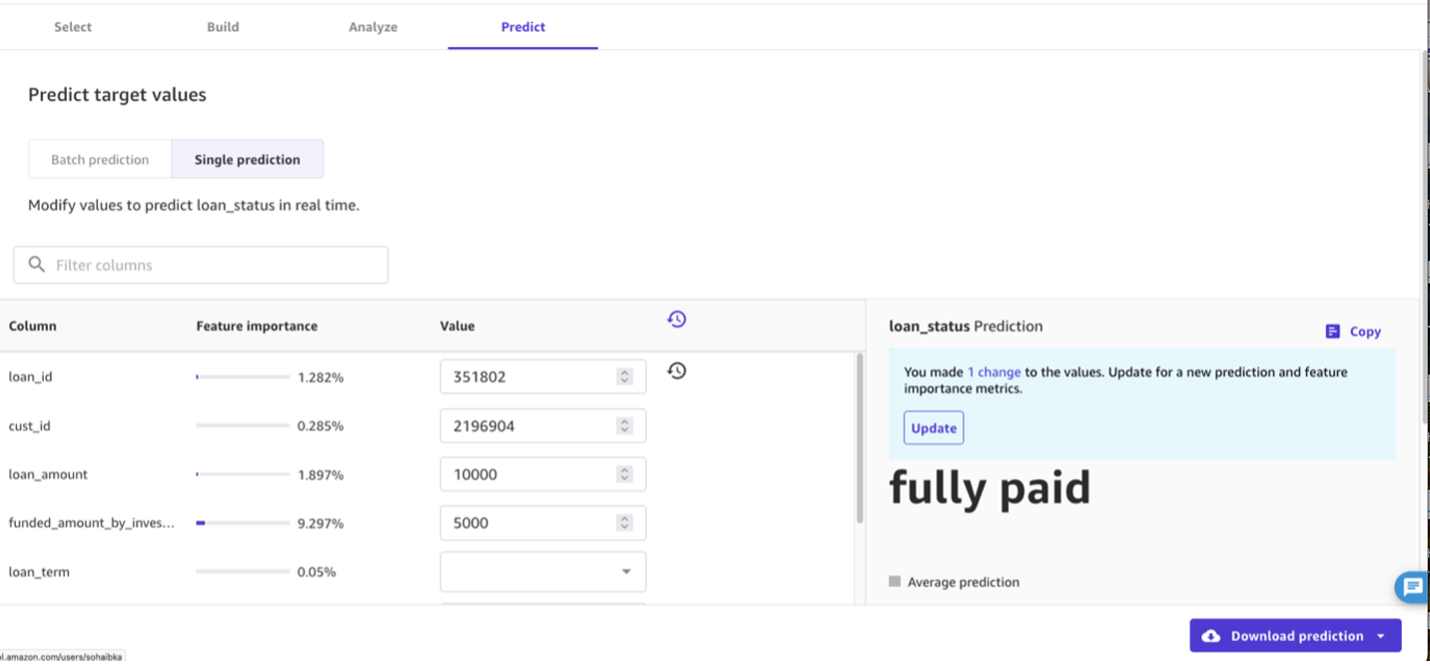
- También puede generar predicciones individuales para una fila de datos a la vez. Bajo Elija el tipo de predicciónseleccionar Predicción única y luego cambie los valores de cualquiera de los campos de entrada que desee y elija Actualizar.
Analiza las predicciones
Ahora le mostraremos cómo utilizar Quicksight para visualizar los datos de predicciones del lienzo de SageMaker para obtener más información a partir de sus datos. SageMaker Canvas tiene integración directa con QuickSight, que es un servicio de análisis empresarial basado en la nube que ayuda a los empleados de una organización a crear visualizaciones, realizar análisis ad hoc y obtener rápidamente información empresarial a partir de sus datos, en cualquier momento y en cualquier dispositivo.
- Con la página de vista previa arriba, elija Enviar a amazon QuickSight.
- Ingrese el nombre de usuario de QuickSight con el que desea compartir los resultados.
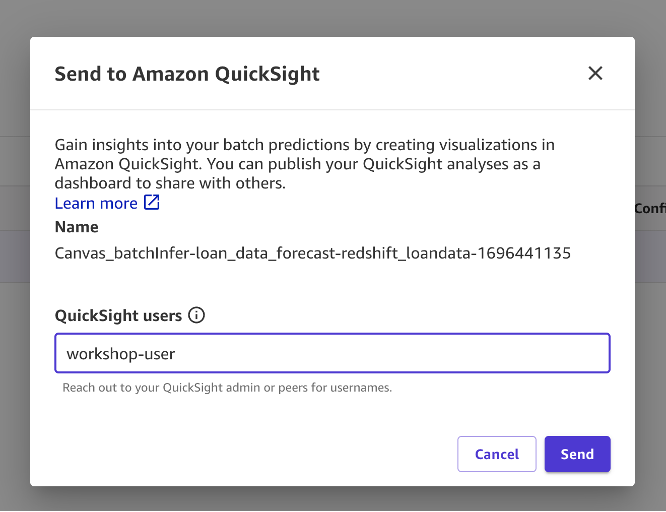
- Elegir Enviar y debería ver una confirmación que indique que los resultados se enviaron correctamente.

- Ahora puede crear un panel QuickSight para predicciones.
- Vaya a la consola QuickSight ingresando QuickSight en la barra de búsqueda de servicios de su consola y elija Vista rápida.
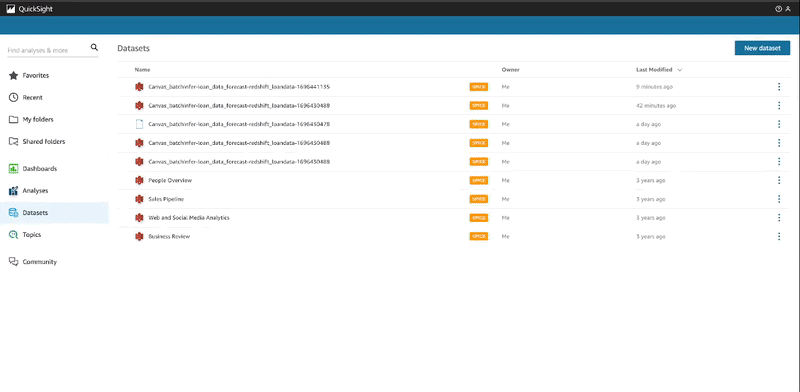
- Bajo Conjuntos de datosseleccione el conjunto de datos de SageMaker Canvas que acaba de crear.
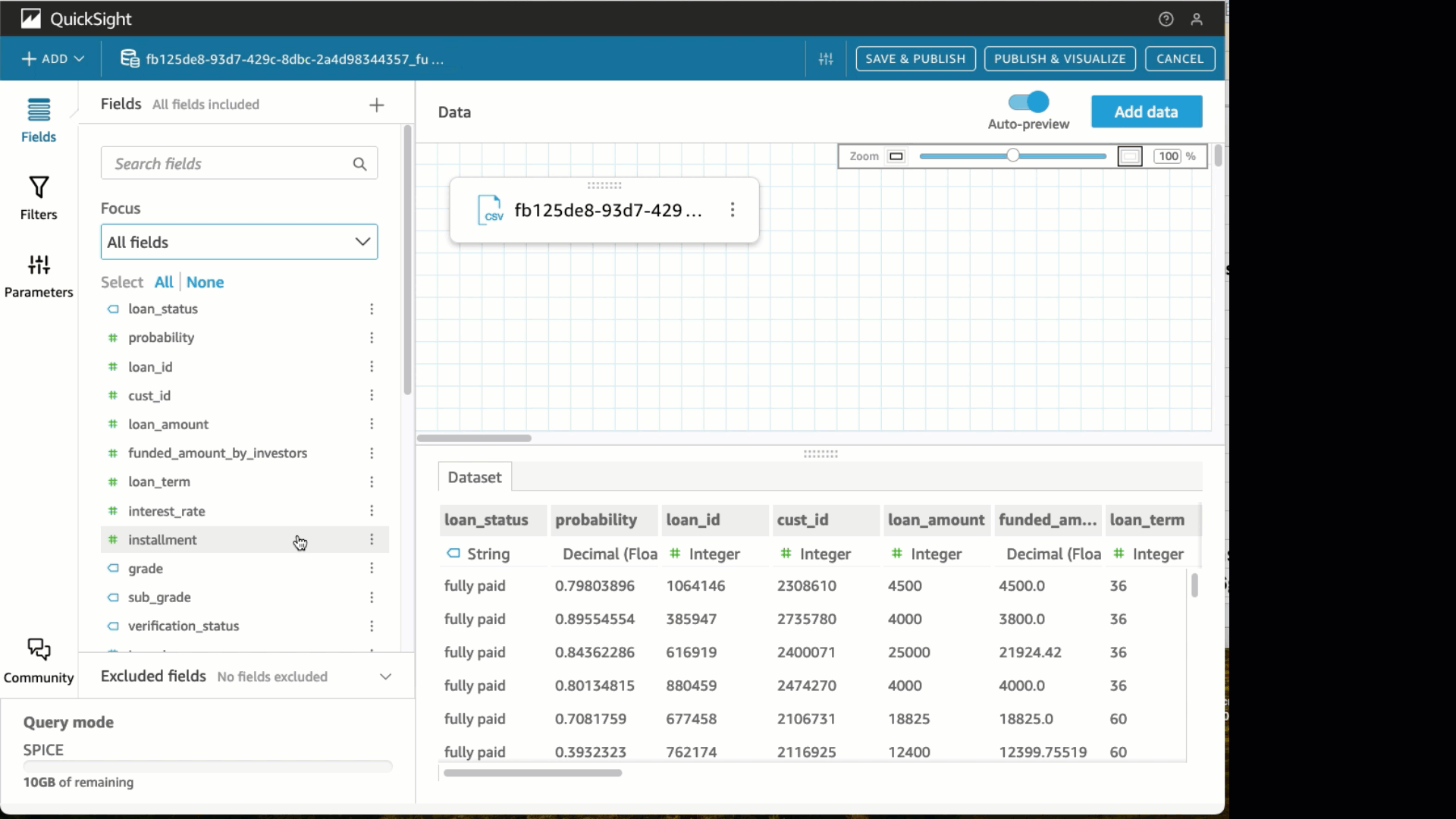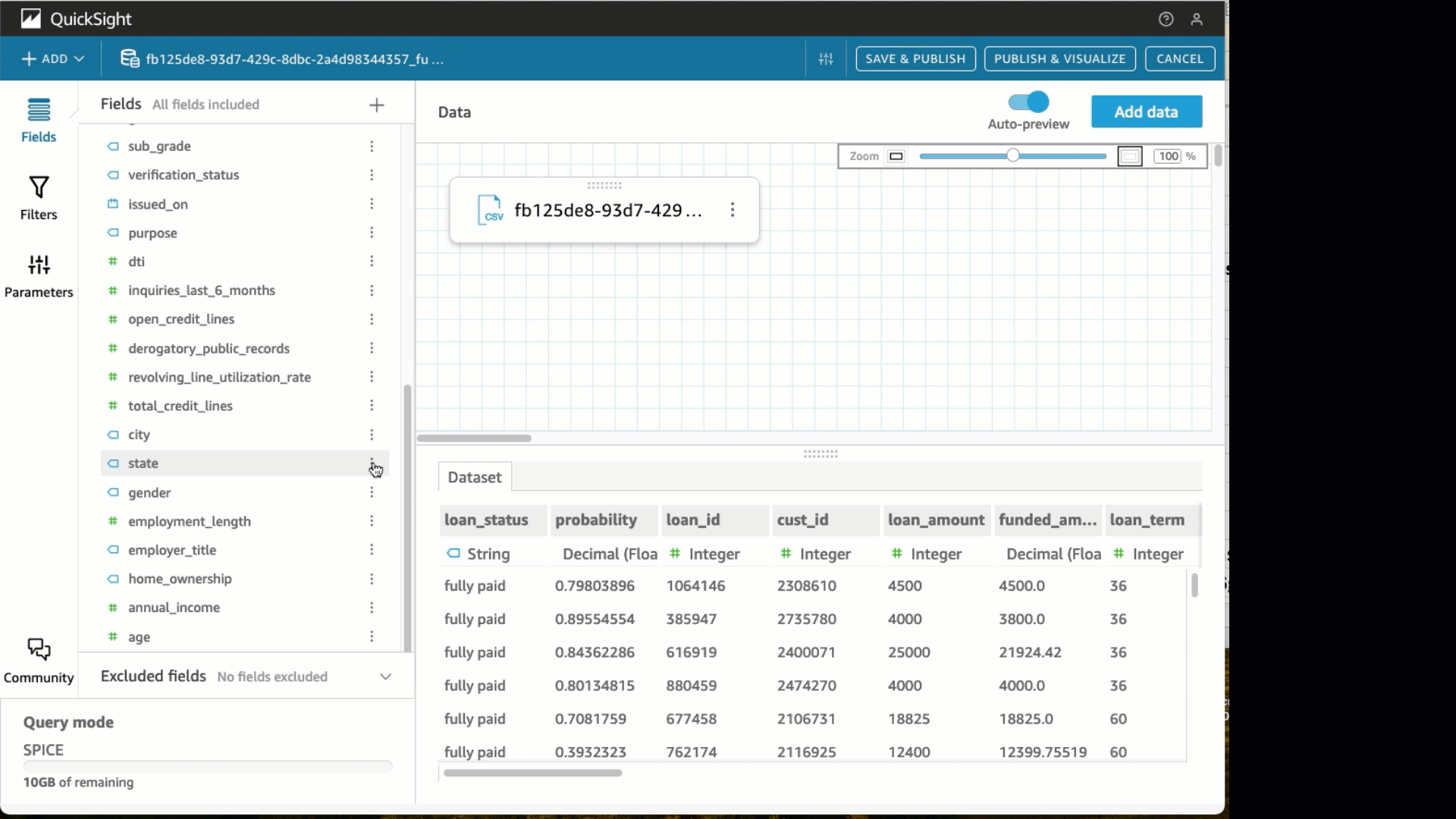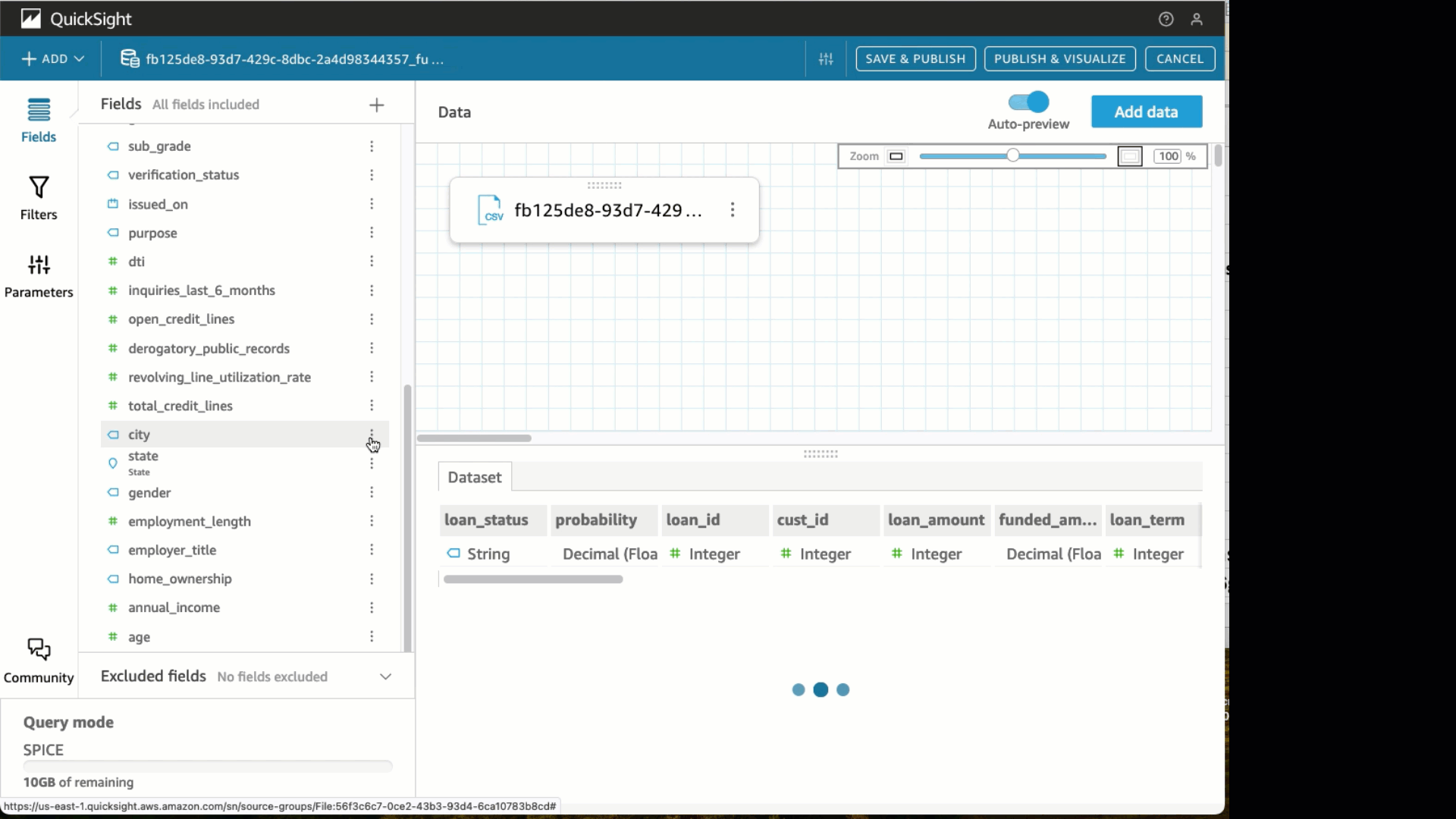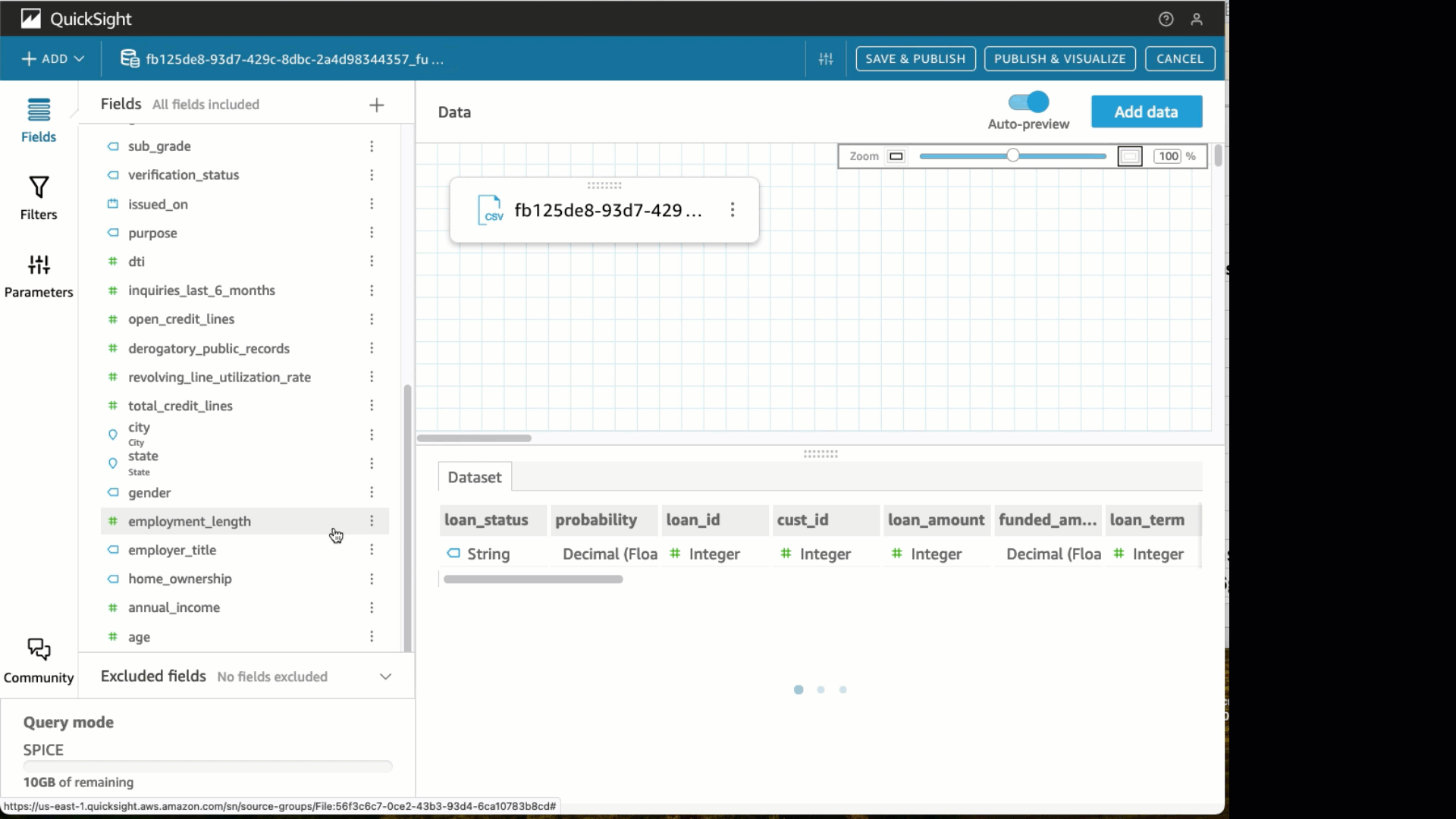
- Elegir Editar conjunto de datos.
- bajo el Estado cambie el tipo de datos a Estado.
- Elegir Crear con Hoja interactiva seleccionada.
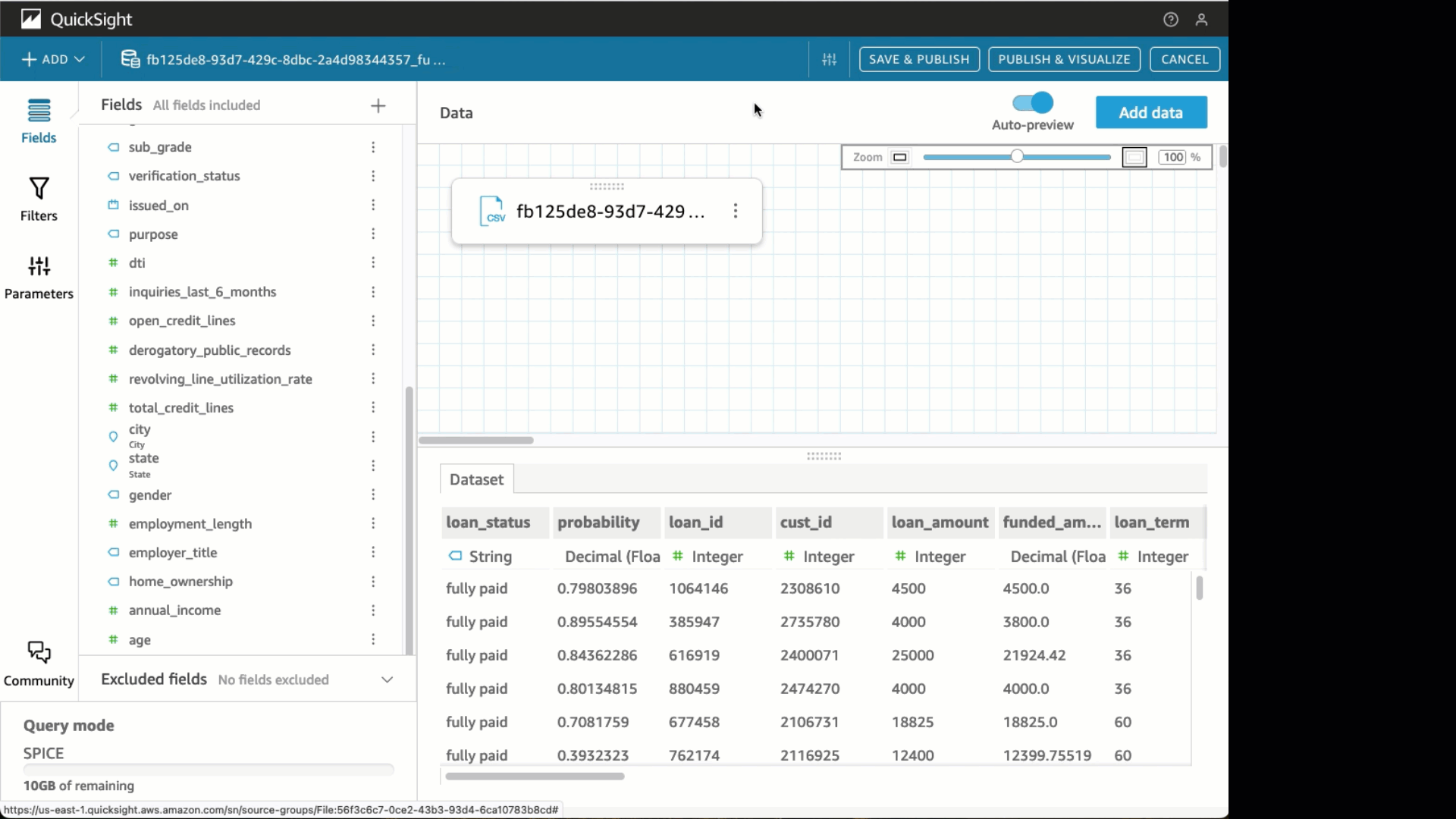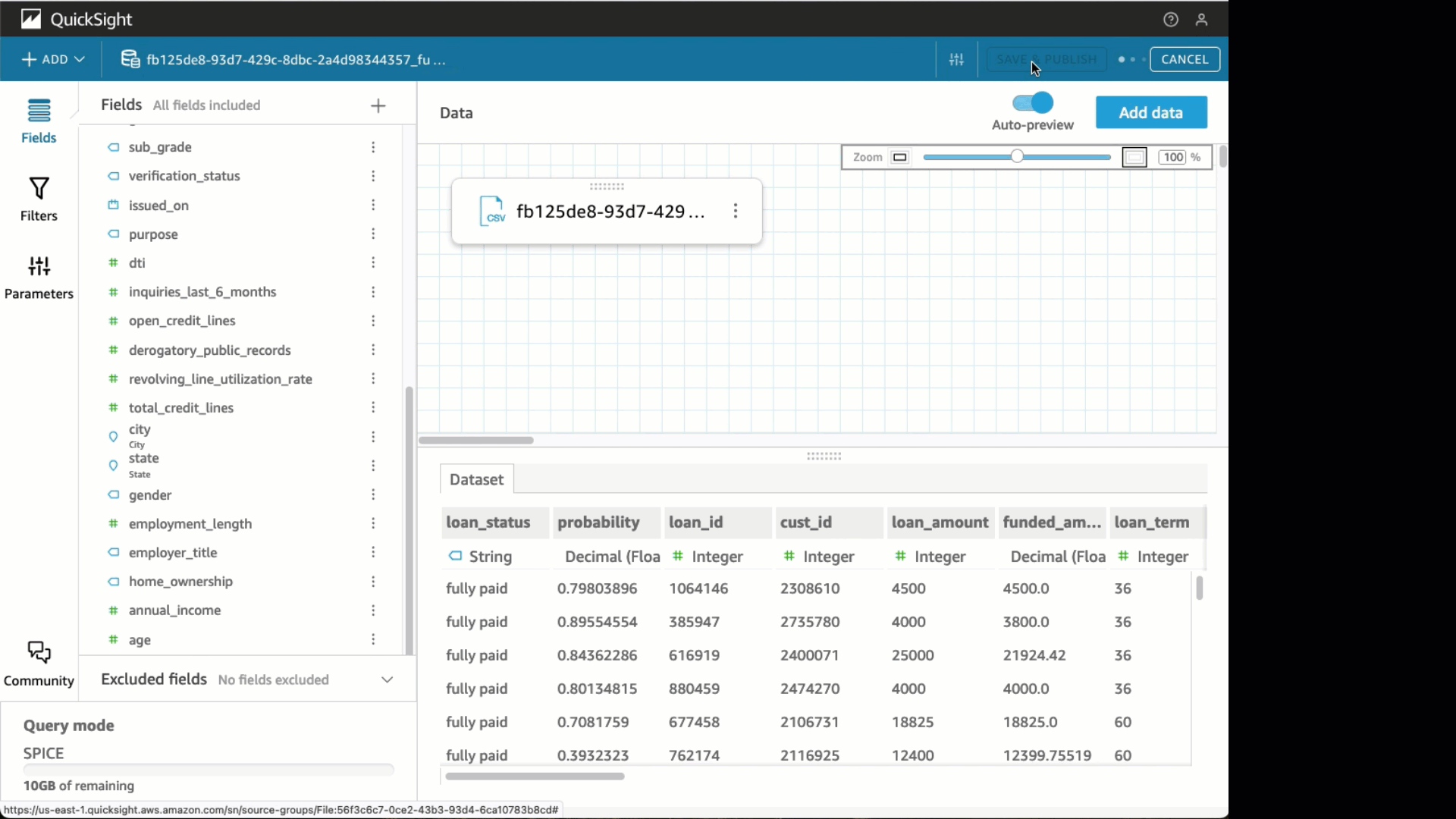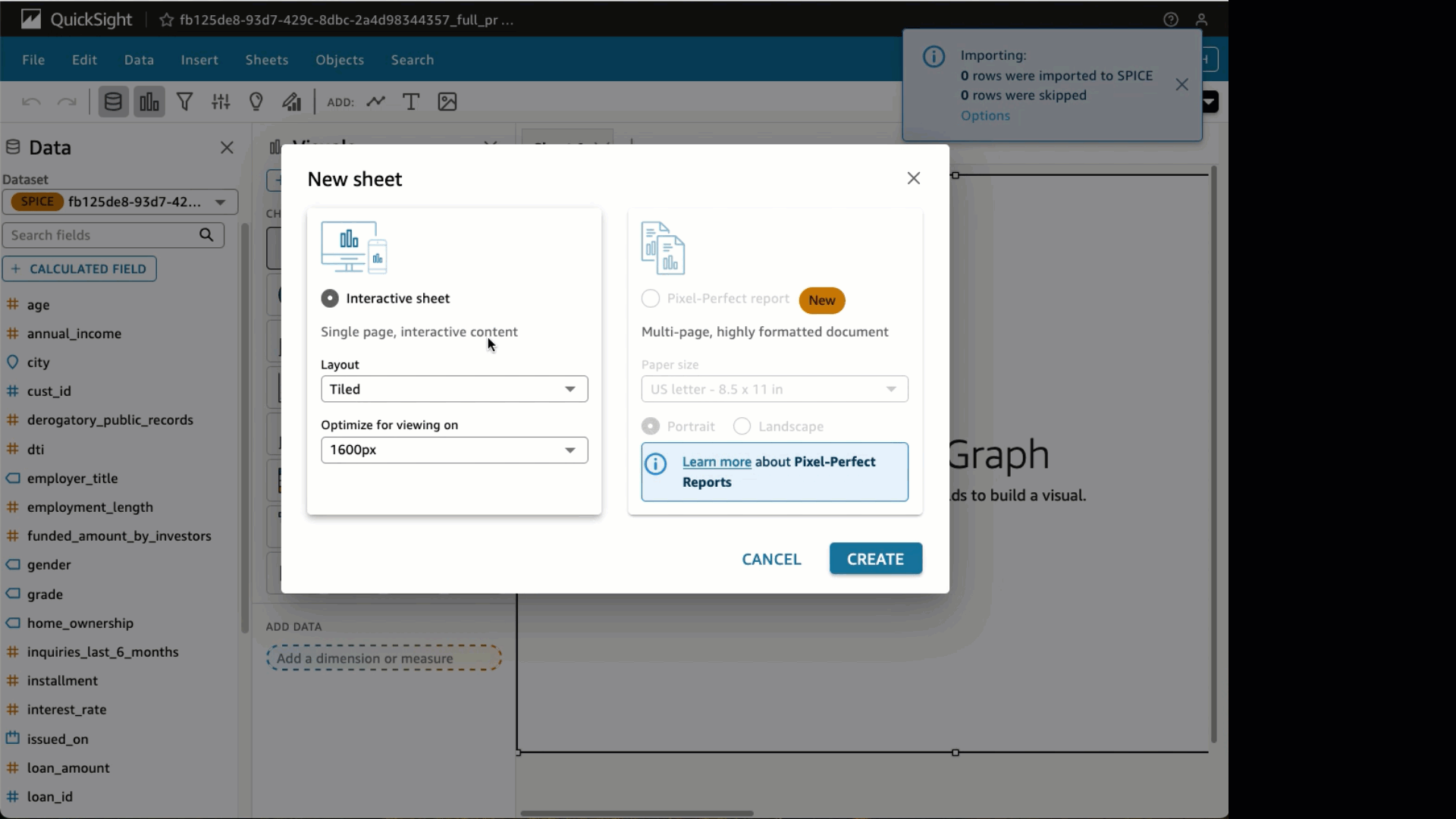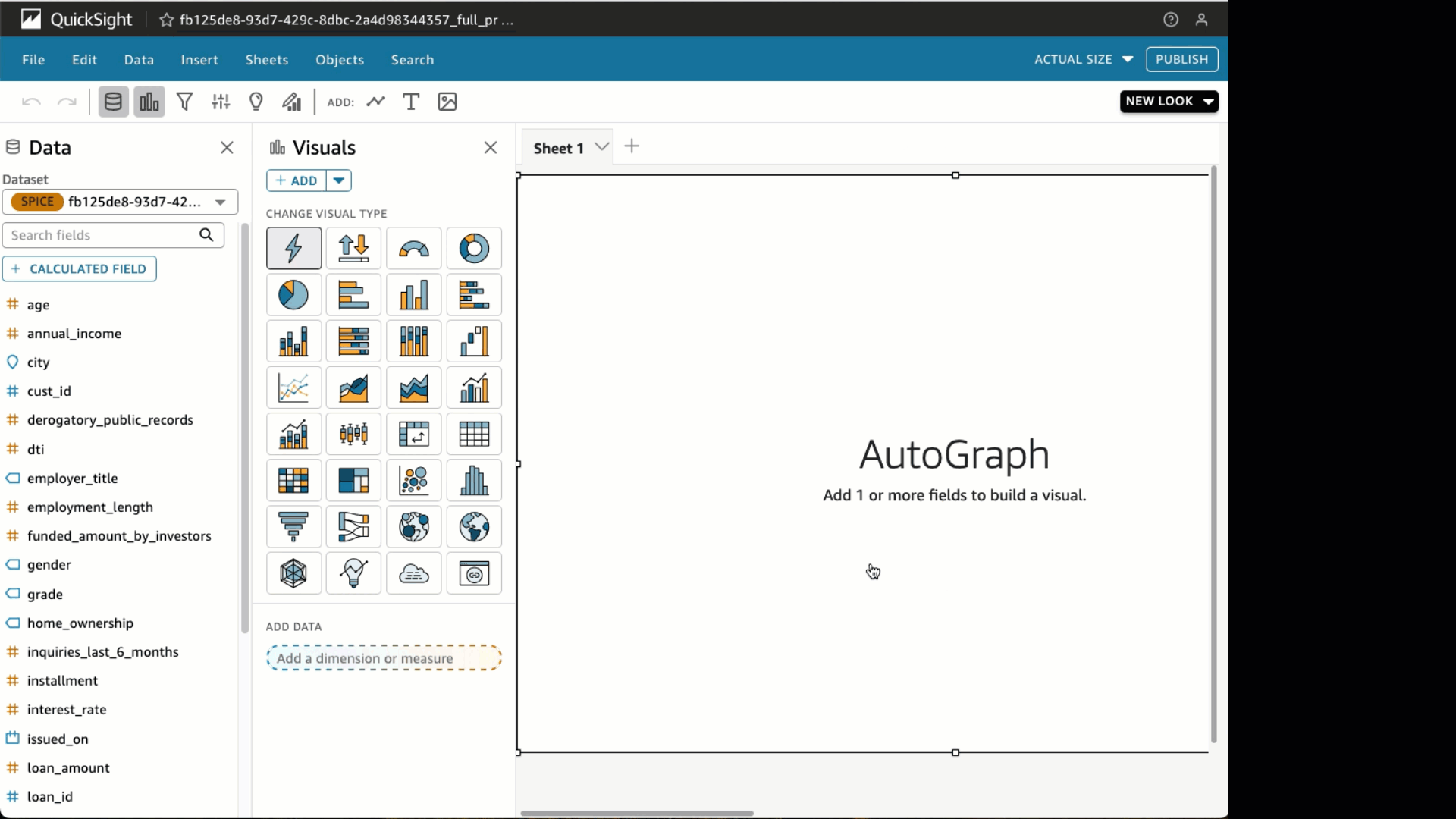
- En tipos visuales, elija el mapa lleno
- Seleccione el Estado y Probabilidad
- Bajo Pozos de campoelegir Probabilidad y cambiar el Agregar a Promedio y Mostrar como a Por ciento.
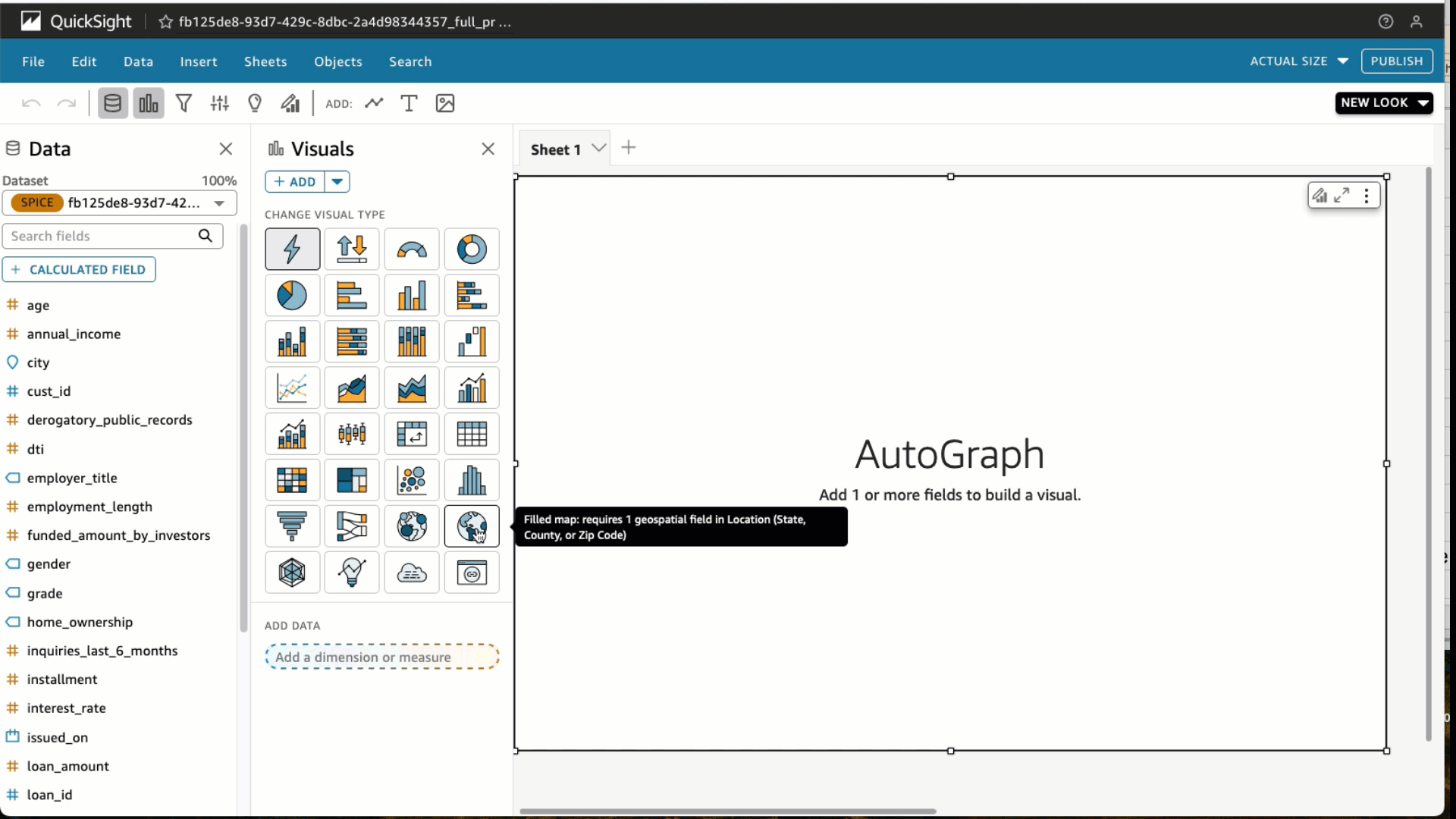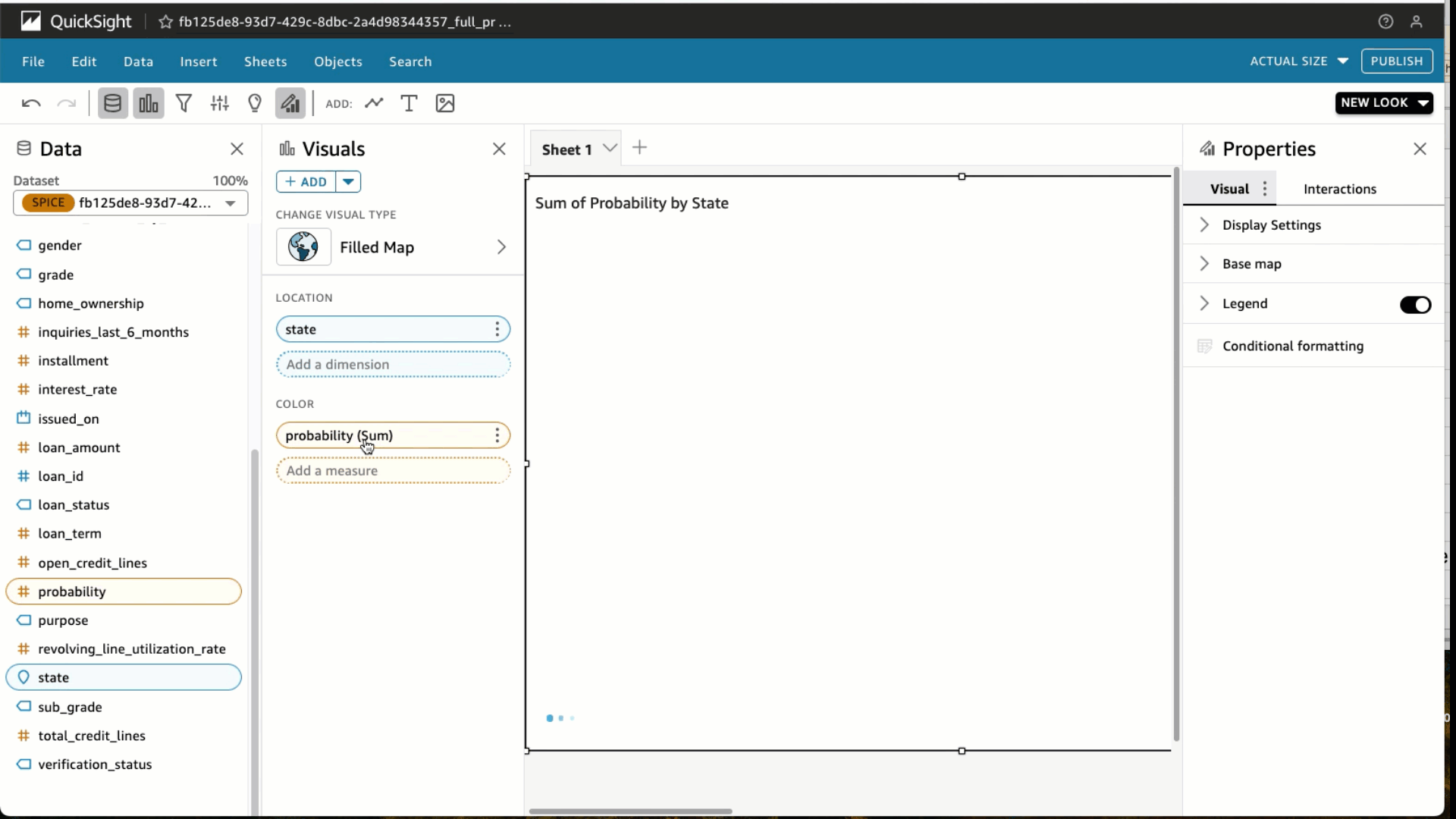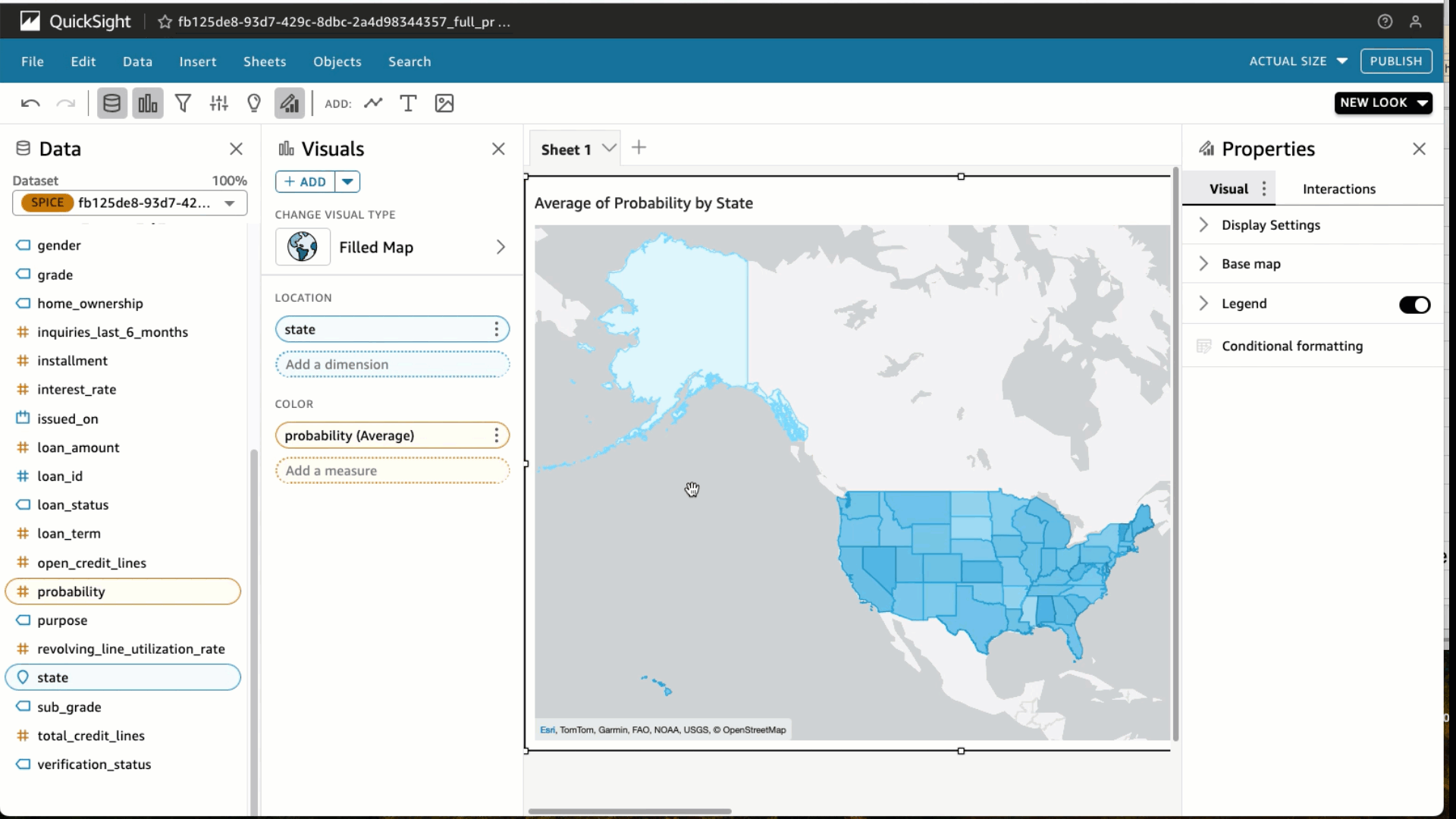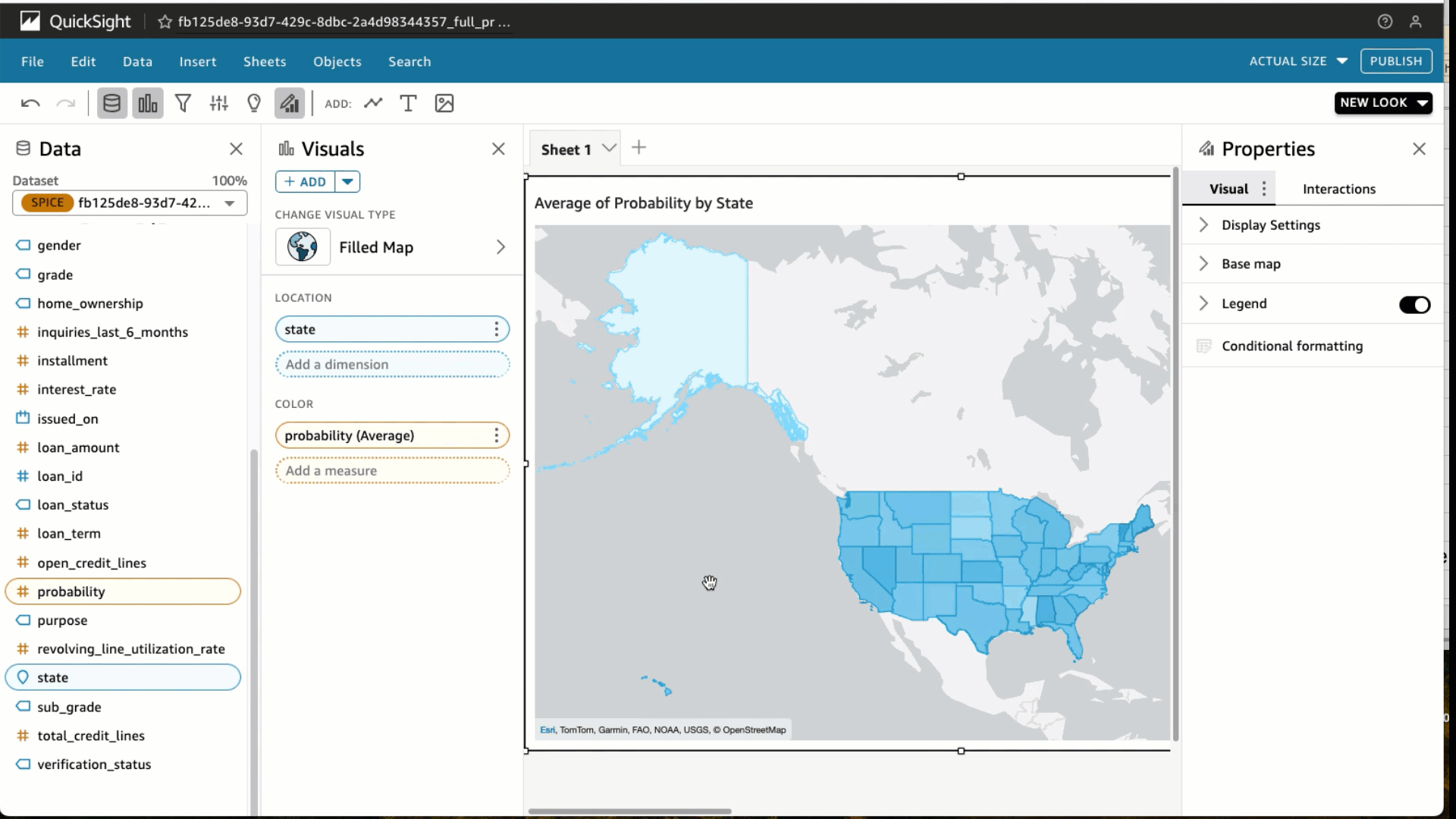
- Elegir Filtrar y agregar un filtro para estado_préstamo incluir totalmente pagado préstamos únicamente. Elegir Aplicar.
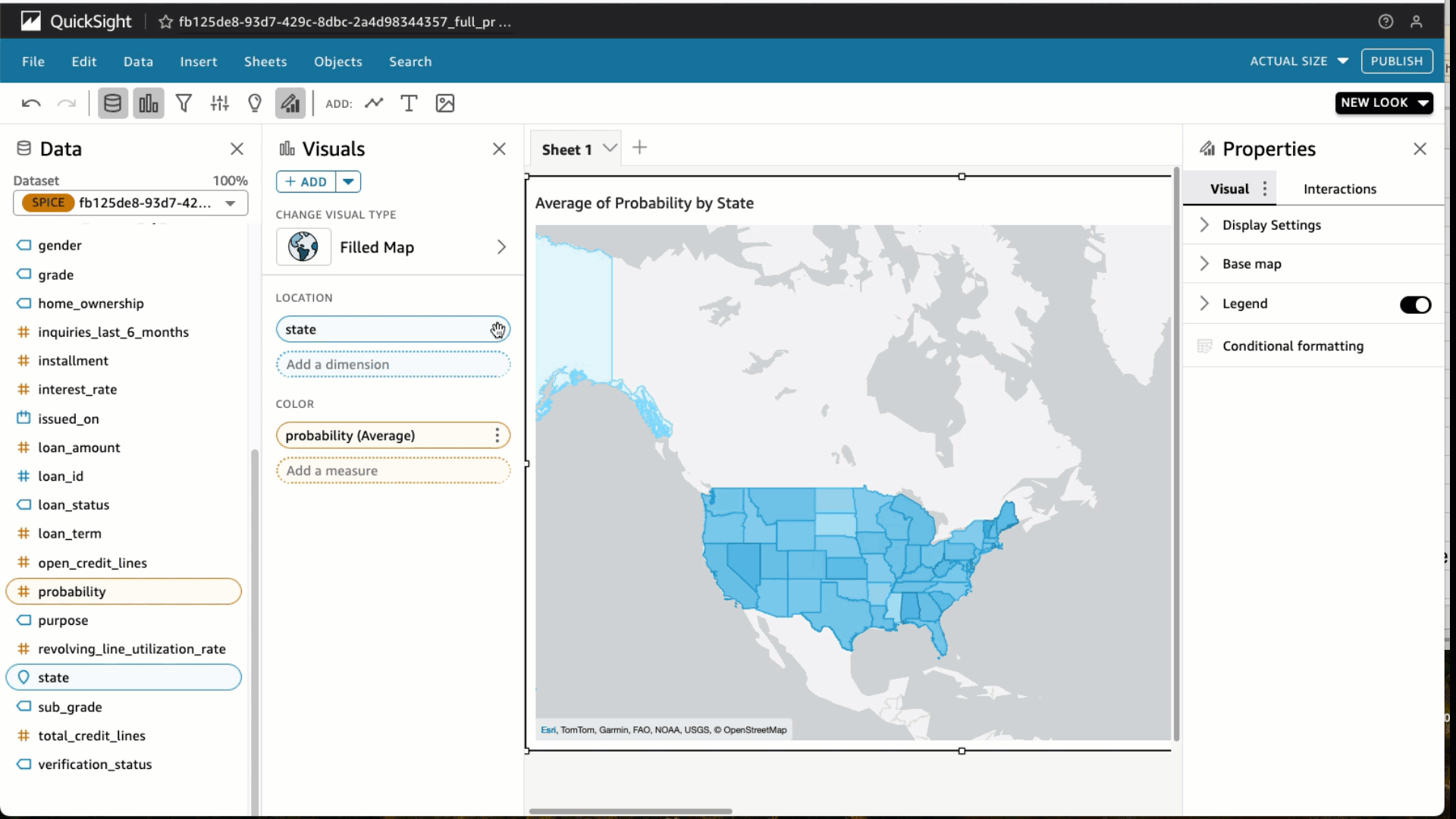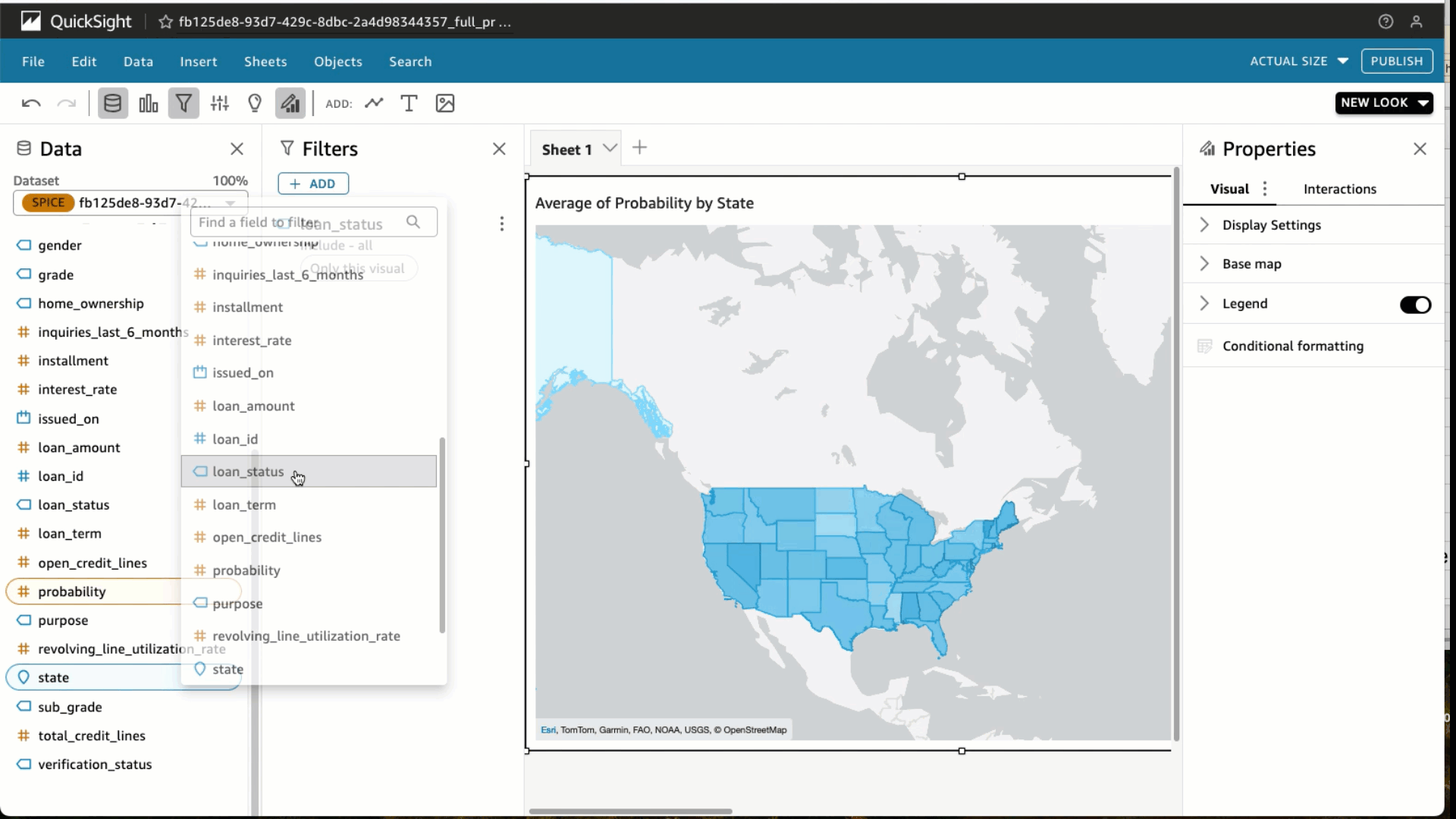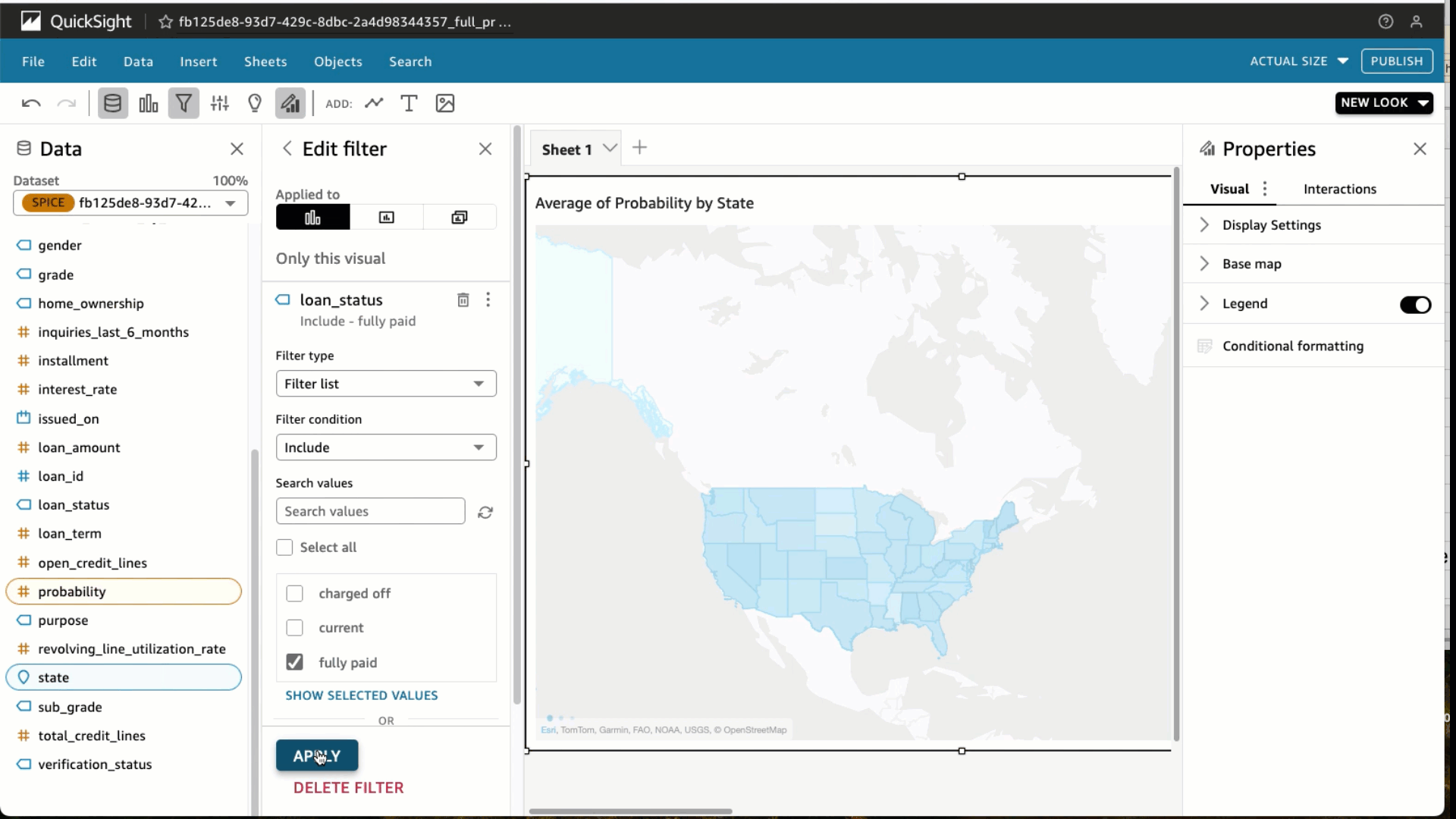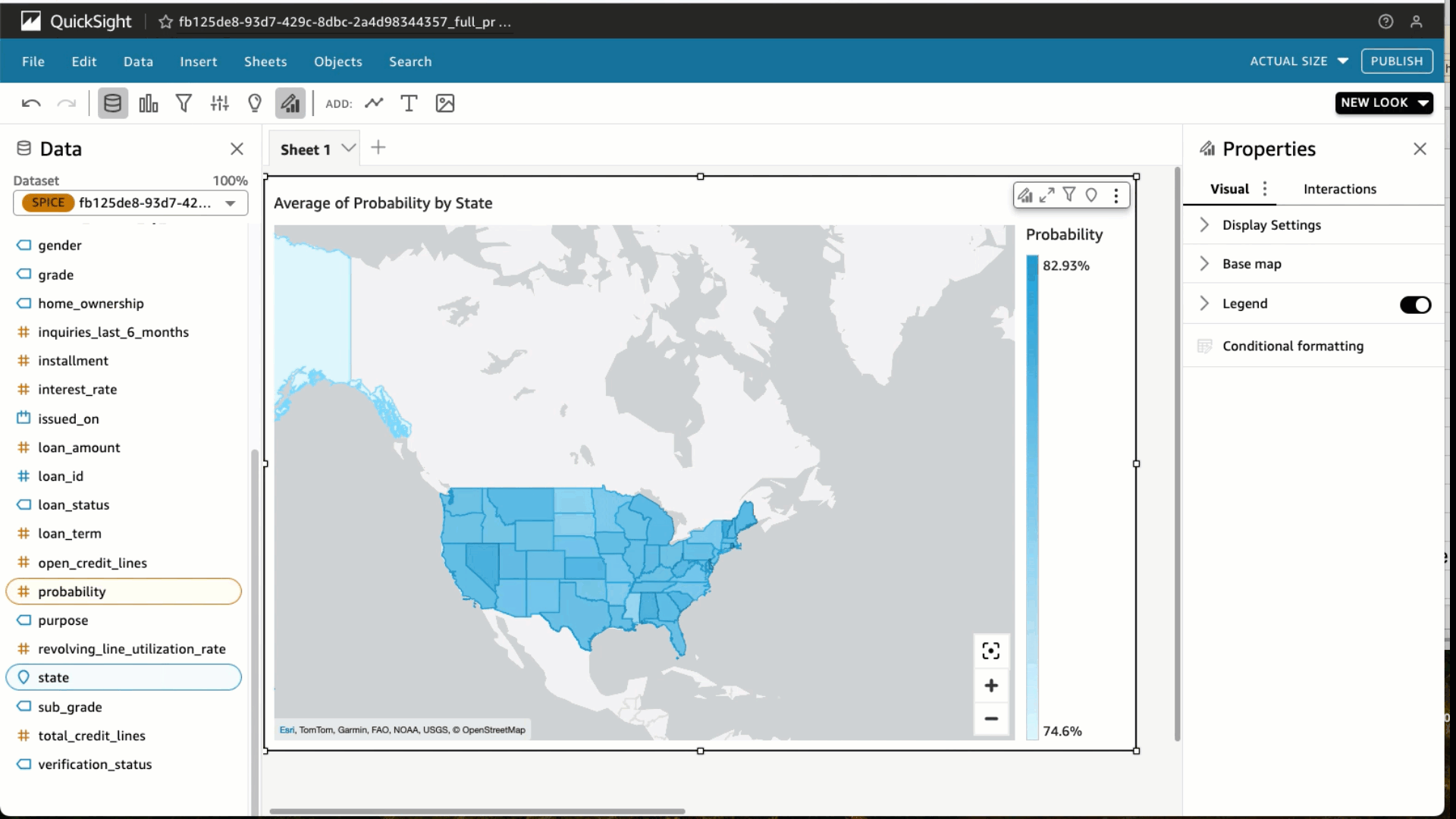
- En la parte superior derecha del banner azul, elige Compartir y Publicar panel.
- Usamos el nombre Probabilidad promedio de préstamo totalmente pagado por estado, pero siéntase libre de usar el suyo propio.
- Elegir Publicar panel y ya está. Ahora podrá compartir este panel con sus predicciones con otros analistas y consumidores de estos datos.
- Vaya a la consola QuickSight ingresando QuickSight en la barra de búsqueda de servicios de su consola y elija Vista rápida.
Limpiar
Utilice los siguientes pasos para evitar cualquier costo adicional en su cuenta:
- Cerrar sesión en SageMaker Canvas
- En la consola de AWS, elimine la pila de CloudFormation que lanzó anteriormente en la publicación.
Conclusión
Creemos que la integración de su almacén de datos en la nube (amazon Redshift) con SageMaker Canvas abre la puerta a producir soluciones de aprendizaje automático mucho más sólidas para su negocio de manera más rápida, sin necesidad de mover datos y sin experiencia en aprendizaje automático.
Ahora cuenta con analistas de negocios que producen valiosos conocimientos comerciales y, al mismo tiempo, permite que los científicos de datos y los ingenieros de aprendizaje automático ayuden a perfeccionar, ajustar y ampliar los modelos según sea necesario. La integración de SageMaker Canvas con amazon Redshift proporciona un entorno unificado para crear e implementar modelos de aprendizaje automático, lo que le permite centrarse en crear valor con sus datos en lugar de centrarse en los detalles técnicos de la creación de canalizaciones de datos o algoritmos de aprendizaje automático.
Lectura adicional:
- Taller de lienzo de SageMaker
- re:Invent 2022 – Lienzo de SageMaker
- Curso práctico para analistas de negocios: toma de decisiones prácticas utilizando aprendizaje automático sin código en AWS
Acerca de los autores
 Suresh Patnam Es especialista principal en ventas de IA/ML e IA generativa en AWS. Le apasiona ayudar a empresas de todos los tamaños a transformarse en organizaciones digitales de rápido movimiento centradas en datos, IA/ML e IA generativa.
Suresh Patnam Es especialista principal en ventas de IA/ML e IA generativa en AWS. Le apasiona ayudar a empresas de todos los tamaños a transformarse en organizaciones digitales de rápido movimiento centradas en datos, IA/ML e IA generativa.
 Sohaib Katariwala es un arquitecto senior de soluciones especializado en AWS centrado en amazon OpenSearch Service. Sus intereses están en todo lo relacionado con datos y análisis. Más específicamente, le encanta ayudar a los clientes a utilizar la IA en su estrategia de datos para resolver los desafíos actuales.
Sohaib Katariwala es un arquitecto senior de soluciones especializado en AWS centrado en amazon OpenSearch Service. Sus intereses están en todo lo relacionado con datos y análisis. Más específicamente, le encanta ayudar a los clientes a utilizar la IA en su estrategia de datos para resolver los desafíos actuales.
 michael hamilton es arquitecto de soluciones especialista en análisis e inteligencia artificial en AWS. Le gusta todo lo relacionado con los datos y ayudar a los clientes a encontrar soluciones para sus casos de uso complejos.
michael hamilton es arquitecto de soluciones especialista en análisis e inteligencia artificial en AWS. Le gusta todo lo relacionado con los datos y ayudar a los clientes a encontrar soluciones para sus casos de uso complejos.
 Nabil Ezzarhouni es arquitecto de soluciones de IA/ML e IA generativa en AWS. Vive en Austin, TX y le apasiona la nube, las tecnologías ai/ML y la gestión de productos. Cuando no está trabajando, pasa tiempo con su familia buscando el mejor taco de Texas. Porque… ¿por qué no?
Nabil Ezzarhouni es arquitecto de soluciones de IA/ML e IA generativa en AWS. Vive en Austin, TX y le apasiona la nube, las tecnologías ai/ML y la gestión de productos. Cuando no está trabajando, pasa tiempo con su familia buscando el mejor taco de Texas. Porque… ¿por qué no?






{kind=link}