 NEWSLETTER
NEWSLETTER
amazon Q Business es un asistente generativo impulsado por inteligencia artificial que puede responder preguntas, proporcionar resúmenes, generar contenido y extraer información directamente del contenido en documentos PDF digitales y escaneados en sus fuentes de datos empresariales sin necesidad de extraer el texto primero.
Los clientes de sectores como finanzas, seguros, atención médica, ciencias biológicas y más necesitan obtener información de varios tipos de documentos, como recibos, planes de atención médica o declaraciones de impuestos, que con frecuencia se encuentran en formato PDF escaneado. Estos tipos de documentos suelen tener un formato semiestructurado o no estructurado, que requiere procesamiento para extraer el texto antes de indexarlo con amazon Q Business.
El lanzamiento de la compatibilidad con documentos PDF escaneados con amazon Q Business puede ayudarlo a procesar sin inconvenientes una variedad de tipos de documentos multimodales a través de la consola de administración de AWS y las API, en todas las regiones de AWS compatibles con amazon Q Business. Puede ingerir documentos, incluidos los PDF escaneados, desde sus fuentes de datos mediante conectores compatibles, indexarlos y luego usar los documentos para responder preguntas, proporcionar resúmenes y generar contenido de forma segura y precisa desde sus sistemas empresariales. Esta función elimina el esfuerzo de desarrollo necesario para extraer texto de documentos PDF escaneados fuera de amazon Q Business y mejora el proceso de procesamiento de documentos para crear su asistente de inteligencia artificial (IA) generativa con amazon Q Business.
En esta publicación, mostramos cómo indexar de forma asincrónica y ejecutar consultas en tiempo real con documentos PDF escaneados utilizando amazon Q Business.
Descripción general de la solución
Puede utilizar amazon Q Business para documentos PDF escaneados desde la consola, los SDK de AWS o la interfaz de línea de comandos de AWS (AWS CLI).
amazon Q Business ofrece un conjunto versátil de conectores de datos que se pueden integrar con una amplia gama de fuentes de datos empresariales, lo que le permite desarrollar soluciones de IA generativa con una configuración mínima. Para obtener más información, visite amazon Q Business, que ahora está disponible para el público en general y ayuda a aumentar la productividad de la fuerza laboral con IA generativa.
Una vez que la aplicación de amazon Q Business esté lista para usar, puede cargar directamente los archivos PDF escaneados en un índice de amazon Q Business mediante la consola o las API. amazon Q Business ofrece múltiples conectores de fuentes de datos que pueden integrar y sincronizar datos de múltiples repositorios de datos en un solo índice. En esta publicación, demostramos dos escenarios para usar documentos: uno con la opción de carga directa de documentos y otro con el conector de amazon Simple Storage Service (amazon S3). Si necesita ingerir documentos de otras fuentes de datos, consulte Conectores compatibles para obtener detalles sobre cómo conectar fuentes de datos adicionales.
Indexar los documentos
En esta publicación, utilizamos tres documentos PDF escaneados como ejemplos: una factura, un resumen del plan de salud y un formulario de verificación de empleo, junto con algunos documentos de texto.
El primer paso es indexar estos documentos. Complete los siguientes pasos para indexar documentos mediante la función de carga directa de amazon Q Business. En este ejemplo, cargamos los archivos PDF escaneados.
- En la consola de amazon Q Business, seleccione Aplicaciones en el panel de navegación y abra su aplicación.
- Elegir Agregar fuente de datos.
- Elegir Subir archivos.
- Sube los archivos PDF escaneados.
Puede monitorear los archivos cargados en el Fuentes de datos pestaña. La Estado de carga cambios de Recibió a Procesando a Indexado o Actualizadomomento en el que el archivo se ha indexado correctamente en el almacén de datos de amazon Q Business. La siguiente captura de pantalla muestra los archivos PDF indexados correctamente.
Los siguientes pasos demuestran cómo integrar y sincronizar documentos mediante un conector de amazon S3 con amazon Q Business. En este ejemplo, indexamos los documentos de texto.
- En la consola de amazon Q Business, seleccione Aplicaciones en el panel de navegación y abra su aplicación.
- Elegir Agregar fuente de datos.
- Elegir amazon S3 Para el conector.
- Introduzca la información para Nombre, VPC y configuración del grupo de seguridad, rol de IAM, y Modo de sincronización.
- Para terminar de conectar su fuente de datos a amazon Q Business, elija Agregar fuente de datos.
- En el Detalles de la fuente de datos sección de la página de detalles de su conector, seleccione Sincronizar ahora para permitir que amazon Q Business comience a sincronizar (rastrear e ingerir) datos desde su fuente de datos.
Cuando se complete el trabajo de sincronización, su fuente de datos estará lista para usarse. La siguiente captura de pantalla muestra que los cinco documentos (PDF escaneados y digitales y archivos de texto) se indexaron correctamente.
<img loading="lazy" class="alignnone size-full wp-image-79057" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/07/1720022749_783_Mejore-la-productividad-al-procesar-archivos-PDF-escaneados-con-Amazon.png" alt="Conector de amazon S3″ width=”3234″ height=”1184″/>
La siguiente captura de pantalla muestra una vista completa de las dos fuentes de datos: los documentos cargados directamente y los documentos ingresados a través del conector de amazon S3.
<img loading="lazy" class="alignnone size-full wp-image-79058" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/07/1720022749_484_Mejore-la-productividad-al-procesar-archivos-PDF-escaneados-con-Amazon.png" alt="Fuentes de datos de amazon Q Business.” width=”3222″ height=”1252″/>
Ahora ejecutemos algunas consultas con amazon Q Business en nuestras fuentes de datos.
Consultas sobre documentos PDF densos, no estructurados y escaneados
Es posible que sus documentos sean densos, no estructurados y escaneados en formato PDF. amazon Q Business puede identificar y extraer de ellos el texto con mayor densidad de información. En este ejemplo, utilizamos el PDF de resumen del plan de salud de varias páginas que indexamos anteriormente. La siguiente captura de pantalla muestra una página de ejemplo.

Este es un ejemplo de un documento de resumen de un plan de salud.
En la interfaz web de amazon Q Business, preguntamos “¿Cuál es el máximo total de desembolso personal anual mencionado en el resumen del plan de salud?”
amazon Q Business busca el documento indexado, recupera la información relevante y genera una respuesta citando la fuente de la información. La siguiente captura de pantalla muestra el resultado de muestra.
<img loading="lazy" class="alignnone size-full wp-image-79060" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/07/1720022750_817_Mejore-la-productividad-al-procesar-archivos-PDF-escaneados-con-Amazon.png" alt="Salida de amazon Q Business” width=”1678″ height=”1114″/>
Consultas sobre documentos PDF estructurados, tabulares y escaneados
Los documentos también pueden contener elementos de datos estructurados en formato tabular. amazon Q Business puede identificar, extraer y linealizar automáticamente datos estructurados de archivos PDF escaneados para resolver con precisión cualquier consulta del usuario. En el siguiente ejemplo, utilizamos el PDF de factura que indexamos anteriormente. La siguiente captura de pantalla muestra un ejemplo.
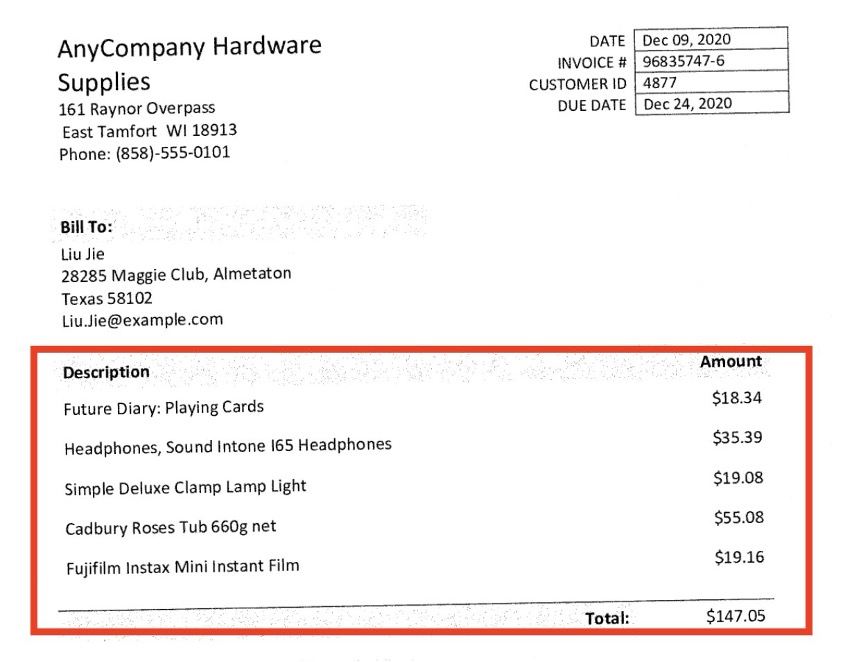
Este es un ejemplo de factura.
En la interfaz web de amazon Q Business, preguntamos “¿Cuánto se cobraron los auriculares en la factura?”
amazon Q Business busca el documento indexado y recupera la respuesta con referencia al documento de origen. La siguiente captura de pantalla muestra que amazon Q Business puede extraer información de la factura.
<img loading="lazy" class="alignnone size-full wp-image-79062" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/07/1720022751_889_Mejore-la-productividad-al-procesar-archivos-PDF-escaneados-con-Amazon.png" alt="Salida de amazon Q Business” width=”1718″ height=”656″/>
Consultas en formularios semiestructurados
Sus documentos también pueden contener elementos de datos semiestructurados en un formulario, como pares clave-valor. amazon Q Business puede satisfacer con precisión las consultas relacionadas con estos elementos de datos extrayendo campos o atributos específicos que sean significativos para las consultas. En este ejemplo, utilizamos el PDF de verificación de empleo. La siguiente captura de pantalla muestra un ejemplo.

Este es un ejemplo de un formulario de verificación de empleo.
En la interfaz de usuario web de amazon Q Business, preguntamos “¿Cuál es la fecha de empleo del solicitante en el formulario de verificación de empleo?” amazon Q Business busca el documento de verificación de empleo indexado y recupera la respuesta con referencia al documento fuente.
<img loading="lazy" class="alignnone size-full wp-image-79064" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/07/1720022751_789_Mejore-la-productividad-al-procesar-archivos-PDF-escaneados-con-Amazon.png" alt="Salida de amazon Q Business” width=”1716″ height=”688″/>
Indexar documentos mediante AWS CLI
En esta sección, le mostramos cómo usar la CLI de AWS para incorporar documentos estructurados y no estructurados almacenados en un depósito de S3 en un índice de amazon Q Business. Puede recuperar rápidamente información detallada sobre sus documentos, incluidos sus estados y los errores que se produjeron durante la indexación. Si es un usuario existente de amazon Q Business y ha indexado documentos en varios formatos, como archivos PDF escaneados y otros tipos compatibles, y ahora desea volver a indexar los documentos escaneados, complete los siguientes pasos:
- Verifique el estado de cada documento para filtrar los documentos fallidos según el estado
"DOCUMENT_FAILED_TO_INDEX"Puede filtrar los documentos en función de este mensaje de error:
"errorMessage": "Document cannot be indexed since it contains no text to index and search on. Document must contain some text."
Si es un usuario nuevo y no ha indexado ningún documento, puede omitir este paso.
El siguiente es un ejemplo del uso de la API ListDocuments para filtrar documentos con un estado específico y sus mensajes de error:
La siguiente captura de pantalla muestra la salida de AWS CLI con una lista de documentos fallidos con mensajes de error.

Ahora puede procesar los documentos por lotes. amazon Q Business permite agregar uno o más documentos a un índice de amazon Q Business.
- Utilice la API BatchPutDocument para ingerir en el índice varios documentos escaneados almacenados en un depósito S3:
La siguiente captura de pantalla muestra la salida de AWS CLI. Debería ver los documentos fallidos como una lista vacía.

- Por último, utilice nuevamente la API ListDocuments para revisar si todos los documentos se indexaron correctamente:
La siguiente captura de pantalla muestra que los documentos están indexados en la fuente de datos.
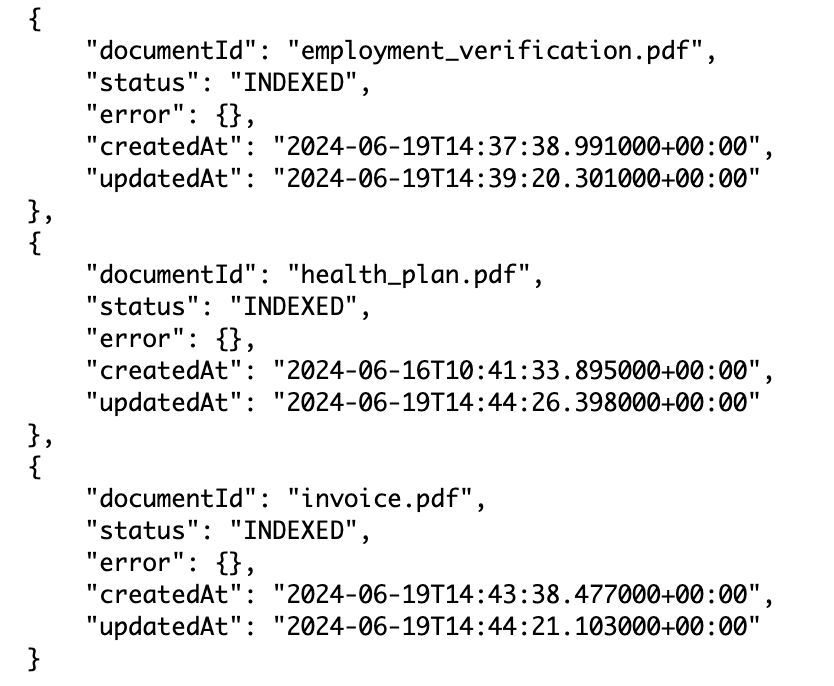
Limpiar
Si creó una nueva aplicación de amazon Q Business y no planea seguir usándola, cancele la suscripción y elimine los usuarios asignados de la aplicación y elimínela para que su cuenta de AWS no acumule costos. Además, si ya no necesita usar las fuentes de datos indexadas, consulte Administración de fuentes de datos de amazon Q Business para obtener instrucciones sobre cómo eliminar las fuentes de datos indexadas.
Conclusión
En esta publicación, demostramos la compatibilidad con los tipos de documentos PDF escaneados con amazon Q Business. Destacamos los pasos para sincronizar, indexar y consultar los tipos de documentos admitidos (que ahora incluyen documentos PDF escaneados) mediante IA generativa con amazon Q Business. También mostramos ejemplos de consultas sobre documentos escaneados multimodales estructurados, no estructurados o semiestructurados mediante la interfaz de usuario web de amazon Q Business y AWS CLI.
Para obtener más información sobre esta función, consulte Formatos de documentos admitidos en amazon Q Business. ¡Pruébelo hoy mismo en la consola de amazon Q Business! Para obtener más información, visite amazon Q Business y la Guía del usuario de amazon Q Business. Puede enviar comentarios a amazon-q” target=”_blank” rel=”noopener noreferrer” data-stringify-link=”https://repost.aws/tags/TALmcXzmfeRaKOzrBowJ9cJQ/amazon-q” data-sk=”tooltip_parent”>AWS re:Post para amazon Q o a través de sus contactos de soporte habituales de AWS.
Sobre los autores
 Sonali Sahu Lidera el equipo de Arquitectura de soluciones de especialistas en IA generativa en AWS. Es autora, líder de opinión y apasionada de la tecnología. Su principal área de interés es la IA y el aprendizaje automático, y suele hablar en conferencias y reuniones sobre IA y aprendizaje automático en todo el mundo. Tiene una amplia y profunda experiencia en tecnología y en la industria tecnológica, con experiencia en la industria de la salud, el sector financiero y los seguros.
Sonali Sahu Lidera el equipo de Arquitectura de soluciones de especialistas en IA generativa en AWS. Es autora, líder de opinión y apasionada de la tecnología. Su principal área de interés es la IA y el aprendizaje automático, y suele hablar en conferencias y reuniones sobre IA y aprendizaje automático en todo el mundo. Tiene una amplia y profunda experiencia en tecnología y en la industria tecnológica, con experiencia en la industria de la salud, el sector financiero y los seguros.
 Rane Chinmayee es arquitecta de soluciones especializada en inteligencia artificial generativa en AWS. Le apasionan las matemáticas aplicadas y el aprendizaje automático. Se centra en el diseño de soluciones de inteligencia artificial generativa y procesamiento inteligente de documentos para clientes de AWS. Fuera del trabajo, disfruta de bailar salsa y bachata.
Rane Chinmayee es arquitecta de soluciones especializada en inteligencia artificial generativa en AWS. Le apasionan las matemáticas aplicadas y el aprendizaje automático. Se centra en el diseño de soluciones de inteligencia artificial generativa y procesamiento inteligente de documentos para clientes de AWS. Fuera del trabajo, disfruta de bailar salsa y bachata.
 Himesh Kumar es un experimentado ingeniero de software sénior que actualmente trabaja en amazon Q Business en AWS. Le apasiona crear sistemas distribuidos en el espacio de la IA generativa y el aprendizaje automático. Su experiencia se extiende al desarrollo de sistemas escalables y eficientes, garantizando alta disponibilidad, rendimiento y confiabilidad. Más allá de las habilidades técnicas, se dedica al aprendizaje continuo y a mantenerse a la vanguardia de los avances tecnológicos en IA y aprendizaje automático.
Himesh Kumar es un experimentado ingeniero de software sénior que actualmente trabaja en amazon Q Business en AWS. Le apasiona crear sistemas distribuidos en el espacio de la IA generativa y el aprendizaje automático. Su experiencia se extiende al desarrollo de sistemas escalables y eficientes, garantizando alta disponibilidad, rendimiento y confiabilidad. Más allá de las habilidades técnicas, se dedica al aprendizaje continuo y a mantenerse a la vanguardia de los avances tecnológicos en IA y aprendizaje automático.
 Wei Qing es un desarrollador de software sénior del equipo de amazon Q Business en AWS y le apasiona crear aplicaciones modernas con tecnologías de AWS. Le encanta el aprendizaje impulsado por la comunidad y el intercambio de tecnología, especialmente para temas relacionados con el alojamiento y la inferencia de aprendizaje automático. Su enfoque principal en este momento es crear arquitecturas sin servidor y basadas en eventos para la ingesta de datos de RAG.
Wei Qing es un desarrollador de software sénior del equipo de amazon Q Business en AWS y le apasiona crear aplicaciones modernas con tecnologías de AWS. Le encanta el aprendizaje impulsado por la comunidad y el intercambio de tecnología, especialmente para temas relacionados con el alojamiento y la inferencia de aprendizaje automático. Su enfoque principal en este momento es crear arquitecturas sin servidor y basadas en eventos para la ingesta de datos de RAG.






{kind=link}