 NEWSLETTER
NEWSLETTER
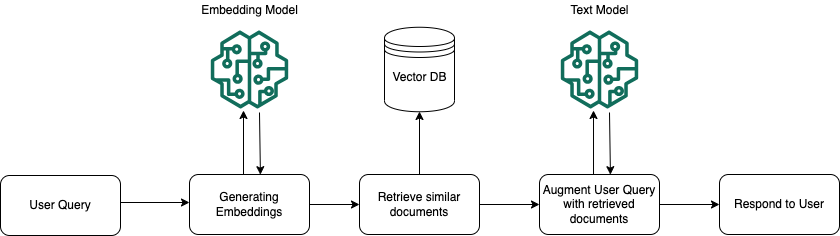
La generación aumentada de recuperación (RAG) es un paradigma popular que proporciona conocimiento adicional a los modelos de lenguaje grandes (LLM) a partir de una fuente externa de datos que no estaba presente en su corpus de entrenamiento.
RAG proporciona conocimiento adicional al LLM a través de su espacio de entrada y su arquitectura generalmente consta de los siguientes componentes:
- Indexación:Preparar un corpus de texto no estructurado, analizarlo y dividirlo en fragmentos, y luego incrustar cada fragmento y almacenarlo en una base de datos vectorial.
- Recuperación:Recupere el contexto relevante para responder una pregunta de la base de datos de vectores mediante la similitud de vectores. Utilice la ingeniería de indicaciones para proporcionar este contexto adicional al LLM junto con la pregunta original. El LLM luego utilizará la pregunta original y el contexto de la base de datos de vectores para generar una respuesta basada en datos que no formaban parte de su corpus de entrenamiento.
Desafíos en la precisión de RAG
Los modelos de incrustación entrenados previamente suelen entrenarse en grandes conjuntos de datos de uso general, como Wikipedia o datos de rastreo web. Si bien estos modelos capturan una amplia gama de relaciones semánticas y pueden generalizarse bien en diversas tareas, pueden tener dificultades para representar con precisión conceptos y matices específicos del dominio. Esta limitación puede generar un rendimiento subóptimo al usar estas incrustaciones entrenadas previamente para tareas o dominios especializados, como los dominios legales, médicos o técnicos. Además, las incrustaciones entrenadas previamente pueden no capturar de manera efectiva las relaciones contextuales y los matices que son específicos de una tarea o dominio en particular. Por ejemplo, en el dominio legal, el mismo término puede tener diferentes significados o implicaciones según el contexto, y estos matices pueden no estar adecuadamente representados en un modelo de incrustación de uso general.
Para abordar las limitaciones de las incrustaciones entrenadas previamente y mejorar la precisión de los sistemas RAG para dominios o tareas específicos, es esencial ajustar el modelo de incrustación en datos específicos del dominio. Al ajustar el modelo en datos que sean representativos del dominio o la tarea de destino, el modelo puede aprender a capturar la semántica, la jerga y las relaciones contextuales relevantes que son cruciales para ese dominio.
Las incrustaciones específicas de dominio pueden mejorar significativamente la calidad de las representaciones vectoriales, lo que permite una recuperación más precisa del contexto relevante de la base de datos de vectores. Esto, a su vez, mejora el rendimiento del sistema RAG en términos de generación de respuestas más precisas y relevantes.
Esta publicación demuestra cómo usar amazon SageMaker para ajustar un modelo de incrustación de Transformador de oraciones e implementarlo con un punto de conexión de amazon SageMaker. El código de esta publicación y más ejemplos están disponibles en Repositorio de GitHubPara obtener más información sobre cómo ajustar el Transformador de oraciones, consulte Descripción general del entrenamiento de Transformador de oraciones.
Ajuste fino de modelos de incrustación con SageMaker
SageMaker es un servicio de aprendizaje automático totalmente administrado que simplifica todo el flujo de trabajo de aprendizaje automático, desde la preparación de datos y el entrenamiento de modelos hasta la implementación y el monitoreo. Proporciona un entorno integrado y sin inconvenientes que elimina las complejidades de la administración de la infraestructura, lo que permite que los desarrolladores y los científicos de datos se concentren únicamente en crear e iterar sus modelos de aprendizaje automático.
Una de las principales ventajas de SageMaker es su compatibilidad nativa con los populares marcos de código abierto, como TensorFlow, PyTorch y los transformadores Hugging Face. Esta integración permite un entrenamiento y una implementación de modelos sin inconvenientes utilizando estos marcos, sus potentes capacidades y su amplio ecosistema de bibliotecas y herramientas.
SageMaker también ofrece una variedad de algoritmos integrados para casos de uso comunes, como visión artificial, procesamiento de lenguaje natural y datos tabulares, lo que facilita comenzar con modelos prediseñados para diversas tareas. SageMaker también admite el entrenamiento distribuido y el ajuste de hiperparámetros, lo que permite un entrenamiento de modelos eficiente y escalable.
Prerrequisitos
Para este tutorial, debes tener los siguientes requisitos previos:
Pasos para ajustar los modelos de incrustación en amazon SageMaker
En las siguientes secciones, utilizamos SageMaker JupyterLab para recorrer los pasos de preparación de datos, creación de un script de entrenamiento, entrenamiento del modelo e implementación como un punto final de SageMaker.
Afinaremos el modelo de incrustación Transformadores de oraciones, todos MiniLM-L6-v2que es un modelo de fuente abierta de Transformadores de oraciones ajustado a un conjunto de datos de pares de oraciones 1B. Asigna oraciones y párrafos a un espacio vectorial denso de 384 dimensiones y se puede utilizar para tareas como la agrupación o la búsqueda semántica. Para ajustarlo, utilizaremos las Preguntas frecuentes de amazon Bedrock, un conjunto de datos de pares de preguntas y respuestas, utilizando el Función MultipleNegativesRankingLoss.
En Pérdidaspuede encontrar las diferentes funciones de pérdida que se pueden usar para ajustar los modelos de incrustación en los datos de entrenamiento. La elección de la función de pérdida juega un papel fundamental al ajustar el modelo. Determina qué tan bien funcionará nuestro modelo de incrustación para la tarea posterior específica.
El MultipleNegativesRankingLoss Esta función se recomienda cuando solo tiene pares positivos en sus datos de entrenamiento, por ejemplo, solo pares de textos similares como pares de paráfrasis, pares de preguntas duplicadas, pares de consulta y respuesta, o pares de (source_language y target_language).
En nuestro caso, considerando que estamos utilizando las preguntas frecuentes de amazon Bedrock como datos de entrenamiento, que consisten en pares de preguntas y respuestas, MultipleNegativesRankingLoss Esta función podría ser una buena opción.
El siguiente fragmento de código demuestra cómo cargar un conjunto de datos de entrenamiento desde un archivo JSON, prepara los datos para el entrenamiento y luego ajusta el modelo previamente entrenado. Después del ajuste, se guarda el modelo actualizado.
El EPOCHS La variable determina la cantidad de veces que el modelo iterará sobre todo el conjunto de datos de entrenamiento durante el proceso de ajuste fino. Una mayor cantidad de épocas generalmente conduce a una mejor convergencia y un rendimiento potencialmente mejorado, pero también puede aumentar el riesgo de sobreajuste si no se regulariza adecuadamente.
En este ejemplo, tenemos un pequeño conjunto de entrenamiento que consta de solo 100 registros. Como resultado, estamos usando un valor alto para el EPOCHS parámetro. Normalmente, en situaciones del mundo real, se tendría un conjunto de entrenamiento mucho más grande. En tales casos, el EPOCHS El valor debe ser un número de uno o dos dígitos para evitar sobreajustar el modelo a los datos de entrenamiento.
Para implementar y servir el modelo de incrustación optimizado para la inferencia, creamos un inference.py Script de Python que sirve como punto de entrada. Este script implementa dos funciones esenciales: model_fn y predict_fncomo lo requiere SageMaker para implementar y utilizar modelos de aprendizaje automático.
El model_fn La función es responsable de cargar el modelo de incrustación ajustado y el tokenizador asociado. predict_fn La función toma oraciones de entrada, las convierte en tokens utilizando el tokenizador cargado y calcula sus incrustaciones de oraciones utilizando el modelo ajustado. Para obtener una única representación vectorial para cada oración, realiza una agrupación de medias sobre las incrustaciones de tokens seguida de la normalización de la incrustación resultante. Finalmente, predict_fn devuelve las incrustaciones normalizadas como una lista, que puede procesarse o almacenarse según sea necesario.
Después de crear el inference.py script, lo empaquetamos junto con el modelo de incrustación perfeccionado en un solo model.tar.gz archivo. Luego, este archivo comprimido se puede cargar en un depósito S3, lo que lo hace accesible para su implementación como punto final de SageMaker.
Finalmente, podemos implementar nuestro modelo optimizado en un punto final de SageMaker.
Una vez completada la implementación, puede encontrar el punto final de SageMaker implementado en la consola de administración de AWS para SageMaker eligiendo el icono Inferencia desde el panel de navegación y luego elegir Puntos finales.
Tiene varias opciones para invocar su punto de conexión. Por ejemplo, en JupyterLab de SageMaker, puede invocarlo con el siguiente fragmento de código:
Devuelve el vector que contiene la incrustación de la clave de entrada:
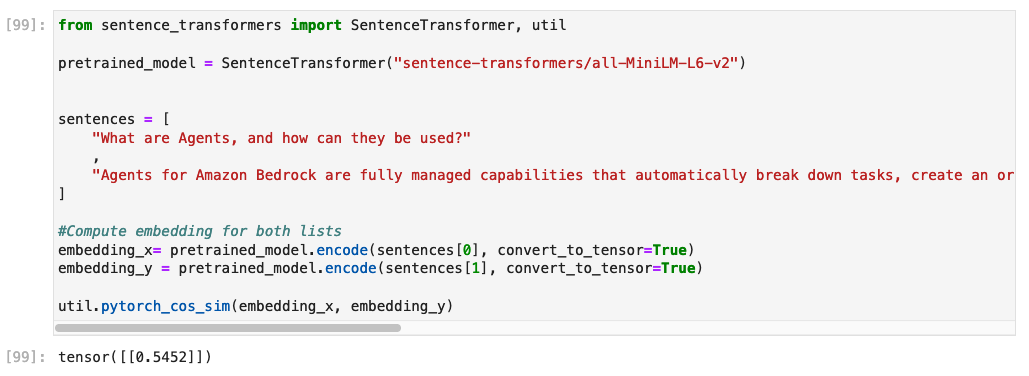
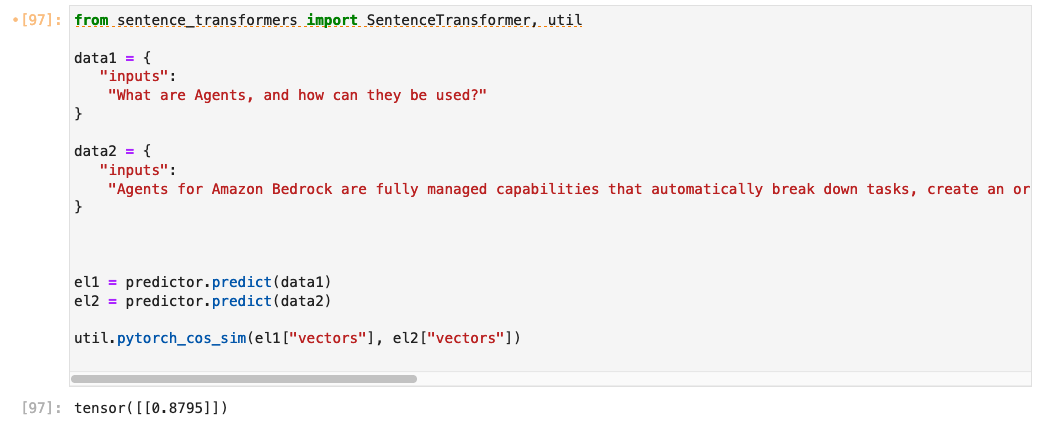
Para ilustrar el impacto del ajuste fino, podemos comparar los puntajes de similitud de coseno entre dos oraciones semánticamente relacionadas utilizando tanto el modelo original preentrenado como el modelo ajustado fino. Un puntaje de similitud de coseno más alto indica que las dos oraciones son más similares semánticamente, porque sus incrustaciones están más cerca en el espacio vectorial.
Consideremos el siguiente par de oraciones:
- Cuáles son agentes¿Y cómo se pueden utilizar?
- Los agentes para amazon Bedrock son capacidades completamente administradas que desglosan tareas automáticamente, crean un plan de orquestación, se conectan de forma segura a los datos de la empresa a través de API y generan respuestas precisas para tareas complejas como la automatización de la gestión de inventario o el procesamiento de reclamos de seguros.
Estas oraciones están relacionadas con el concepto de agentes en el contexto de amazon Bedrock, aunque con diferentes niveles de detalle. Al generar incrustaciones para estas oraciones utilizando ambos modelos y calculando su similitud de coseno, podemos evaluar qué tan bien cada modelo captura la relación semántica entre ellos.
El modelo original preentrenado devuelve una puntuación de similitud de solo 0,54.
El modelo ajustado devuelve una puntuación de similitud de 0,87.
Podemos observar cómo el modelo afinado fue capaz de identificar una similitud semántica mucho mayor entre los conceptos de uncaballeros y Agentes de amazon Bedrock en comparación con el modelo entrenado previamente. Esta mejora se atribuye al proceso de ajuste, que expuso el modelo al lenguaje y los conceptos específicos del dominio presentes en los datos de preguntas frecuentes de amazon Bedrock, lo que le permitió capturar mejor la relación entre estos términos.
Limpiar
Para evitar cargos futuros en su cuenta, elimine los recursos que creó en este tutorial. El punto de conexión de SageMaker y la instancia de JupyterLab de SageMaker generarán cargos mientras las instancias estén activas, por lo que, cuando haya terminado, elimine el punto de conexión y los recursos que creó mientras ejecutaba el tutorial.
Conclusión
En esta publicación del blog, hemos explorado la importancia de ajustar los modelos de incrustación para mejorar la precisión de los sistemas RAG en dominios o tareas específicos. Analizamos las limitaciones de las incrustaciones previamente entrenadas, que se entrenan en conjuntos de datos de propósito general y podrían no capturar los matices y la semántica específica del dominio que se requieren para dominios o tareas especializados.
Destacamos la necesidad de incorporaciones específicas de dominio, que se pueden obtener mediante el ajuste fino del modelo de incorporación en datos representativos del dominio o tarea de destino. Este proceso permite que el modelo capture la semántica, la jerga y las relaciones contextuales relevantes que son cruciales para representaciones vectoriales precisas y, en consecuencia, un mejor rendimiento de recuperación en sistemas RAG.
Luego demostramos cómo ajustar los modelos de incorporación en amazon SageMaker utilizando la popular biblioteca Sentence Transformers.
Al ajustar las integraciones en datos específicos del dominio con SageMaker, puede aprovechar todo el potencial de los sistemas RAG, lo que permite obtener respuestas más precisas y relevantes adaptadas a su dominio o tarea específicos. Este enfoque puede ser particularmente valioso en dominios como el legal, el médico o el técnico, donde capturar matices específicos del dominio es crucial para generar resultados confiables y de alta calidad.
Este y más ejemplos están disponibles en Repositorio de GitHubPruébelo hoy usando la configuración para usuarios individuales (configuración rápida) en amazon SageMaker y cuéntenos lo que piensa en los comentarios.
Sobre los autores
 Ennio Emanuele Pastore es arquitecto sénior del equipo de AWS GenAI Labs. Es un entusiasta de todo lo relacionado con las nuevas tecnologías que tienen un impacto positivo en las empresas y en la vida en general. Ayuda a las organizaciones a lograr resultados comerciales específicos mediante el uso de datos e IA y acelerando su proceso de adopción de la nube de AWS.
Ennio Emanuele Pastore es arquitecto sénior del equipo de AWS GenAI Labs. Es un entusiasta de todo lo relacionado con las nuevas tecnologías que tienen un impacto positivo en las empresas y en la vida en general. Ayuda a las organizaciones a lograr resultados comerciales específicos mediante el uso de datos e IA y acelerando su proceso de adopción de la nube de AWS.






{kind=link}