
Hoy, nos complace anunciar la disponibilidad general de la inferencia por lotes para amazon Bedrock. Esta nueva función permite a las organizaciones procesar grandes volúmenes de datos al interactuar con modelos de base (FM), lo que aborda una necesidad crítica en varias industrias, incluidas las operaciones de centros de llamadas.
El resumen de las transcripciones de los centros de llamadas se ha convertido en una tarea esencial para las empresas que buscan extraer información valiosa de las interacciones con los clientes. A medida que aumenta el volumen de datos de llamadas, los métodos de análisis tradicionales tienen dificultades para seguir el ritmo, lo que genera una demanda de una solución escalable.
La inferencia por lotes se presenta como un enfoque convincente para abordar este desafío. Al procesar volúmenes sustanciales de transcripciones de texto en lotes, con frecuencia utilizando técnicas de procesamiento en paralelo, este método ofrece ventajas en comparación con los enfoques de procesamiento en tiempo real o a pedido. Es particularmente adecuado para operaciones de centros de llamadas a gran escala donde los resultados instantáneos no siempre son un requisito.
En las siguientes secciones, proporcionamos una guía detallada, paso a paso, sobre cómo implementar estas nuevas capacidades, que abarca todo, desde la preparación de datos hasta el envío de trabajos y el análisis de resultados. También exploramos las mejores prácticas para optimizar los flujos de trabajo de inferencia por lotes en amazon Bedrock, lo que lo ayudará a maximizar el valor de sus datos en diferentes casos de uso e industrias.
Descripción general de la solución
La función de inferencia por lotes de amazon Bedrock ofrece una solución escalable para procesar grandes volúmenes de datos en varios dominios. Esta función totalmente administrada permite a las organizaciones enviar trabajos por lotes a través de un CreateModelInvocationJob API o en la consola de amazon Bedrock, lo que simplifica las tareas de procesamiento de datos a gran escala.
En esta publicación, demostramos las capacidades de la inferencia por lotes utilizando el resumen de transcripciones de un centro de llamadas como ejemplo. Este caso de uso sirve para ilustrar el potencial más amplio de la función para gestionar diversas tareas de procesamiento de datos. El flujo de trabajo general para la inferencia por lotes consta de tres fases principales:
- Preparación de datos – Prepare los conjuntos de datos según lo requiera el modelo elegido para un procesamiento óptimo. Para obtener más información sobre los requisitos de formato de lotes, consulte Formatear y cargar los datos de inferencia.
- Envío de trabajos por lotes – Inicie y administre trabajos de inferencia por lotes a través de la consola o API de amazon Bedrock.
- Recopilación y análisis de resultados – Recupere resultados procesados e intégrelos en flujos de trabajo o sistemas de análisis existentes.
Al recorrer esta implementación específica, nuestro objetivo es mostrar cómo se puede adaptar la inferencia por lotes para satisfacer diversas necesidades de procesamiento de datos, independientemente de la fuente o la naturaleza de los datos.
Prerrequisitos
Para utilizar la función de inferencia por lotes, asegúrese de cumplir con los siguientes requisitos:
Preparar los datos
Antes de iniciar un trabajo de inferencia por lotes para el resumen de transcripciones del centro de llamadas, es fundamental formatear y cargar los datos correctamente. Los datos de entrada deben estar en formato JSONL, y cada línea debe representar una única transcripción para el resumen.
Cada línea de su archivo JSONL debe seguir esta estructura:
Aquí, recordId es una cadena alfanumérica de 11 caracteres que funciona como un identificador único para cada entrada. Si omite este campo, el trabajo de inferencia por lotes lo agregará automáticamente en la salida.
El formato de la modelInput El objeto JSON debe coincidir con el campo del cuerpo del modelo que utiliza en el InvokeModel solicitud. Por ejemplo, si está utilizando Anthropic Claude 3 en amazon Bedrock, debe utilizar el MessageAPI Y su modelo de entrada podría parecerse al siguiente código:
Al preparar sus datos, tenga en cuenta las cuotas de inferencia por lotes que se enumeran en la siguiente tabla.
| Nombre del límite | Valor | ¿Ajustable mediante cuotas de servicio? |
| Número máximo de trabajos por lotes por cuenta por ID de modelo utilizando un modelo base | 3 | Sí |
| Número máximo de trabajos por lotes por cuenta por ID de modelo utilizando un modelo personalizado | 3 | Sí |
| Número máximo de registros por archivo | 50.000 | Sí |
| Número máximo de registros por trabajo | 50.000 | Sí |
| Número mínimo de registros por trabajo | 1.000 | No |
| Tamaño máximo por archivo | 200 MB | Sí |
| Tamaño máximo para todos los archivos del trabajo | 1 GB | Sí |
Asegúrese de que los datos de entrada cumplan con estos límites de tamaño y requisitos de formato para un procesamiento óptimo. Si su conjunto de datos excede estos límites, considere dividirlo en varios trabajos por lotes.
Iniciar el trabajo de inferencia por lotes
Una vez que haya preparado los datos de inferencia por lotes y los haya almacenado en amazon S3, existen dos métodos principales para iniciar un trabajo de inferencia por lotes: usar la consola o la API de amazon Bedrock.
Ejecute el trabajo de inferencia por lotes en la consola de amazon Bedrock
Exploremos primero el proceso paso a paso para iniciar un trabajo de inferencia por lotes a través de la consola de amazon Bedrock.
- En la consola de amazon Bedrock, seleccione Inferencia en el panel de navegación.
- Elegir Inferencia por lotes y elige Crear trabajo.
- Para Nombre del puestoingrese un nombre para el trabajo de capacitación y luego elija un FM de la lista. En este ejemplo, elegimos Anthropic Claude-3 Haiku como FM para nuestro trabajo de resumen de transcripciones del centro de llamadas.
- Bajo Datos de entradaespecifique la ubicación S3 para los datos de inferencia de lote preparados.

- Bajo Datos de salidaingrese la ruta S3 para el depósito que almacena las salidas de inferencia por lotes.
- Sus datos se cifran de forma predeterminada con una clave administrada por AWS. Si desea utilizar una clave diferente, seleccione Personalizar la configuración de cifrado.
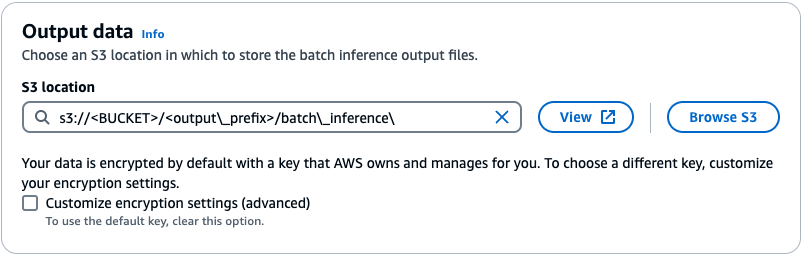
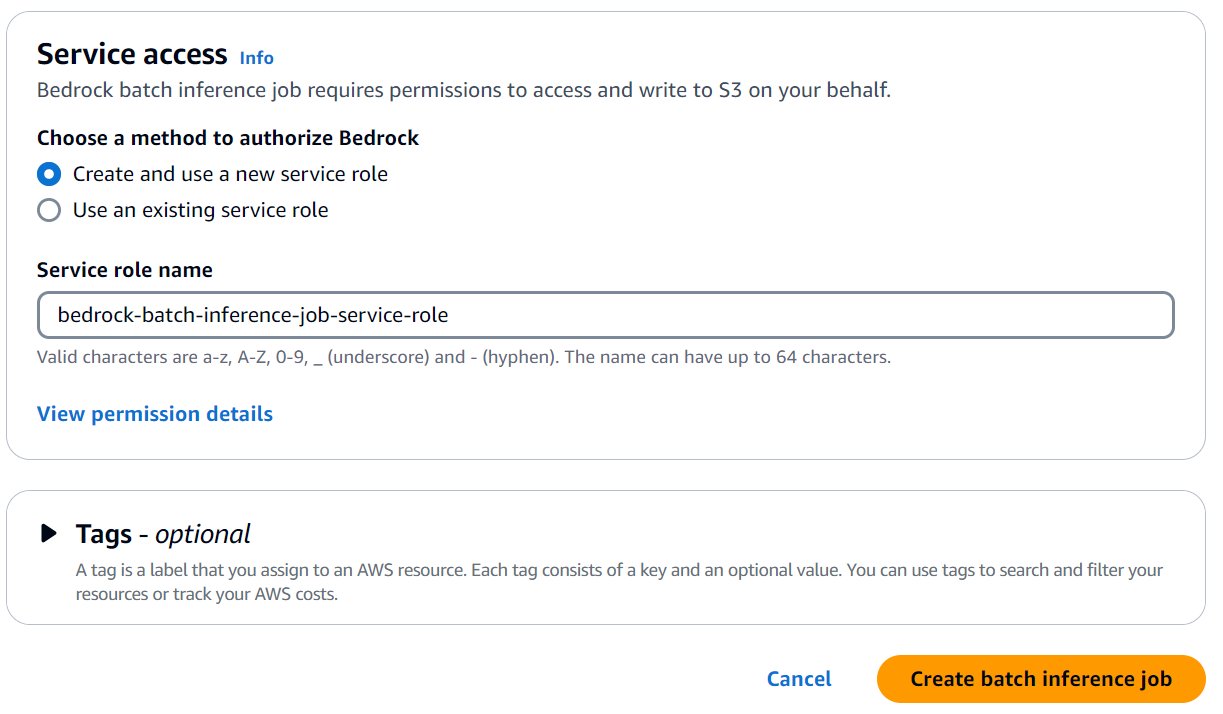
- Bajo Acceso al servicioseleccione un método para autorizar amazon Bedrock. Puede seleccionar Utilizar un rol de servicio existente Si tiene un rol de acceso con políticas IAM específicas o selecciona Crear y utilizar un nuevo rol de servicio.
- Opcionalmente, amplíe el Etiquetas Sección para agregar etiquetas para seguimiento.
- Después de haber agregado todas las configuraciones necesarias para su trabajo de inferencia por lotes, seleccione Crear un trabajo de inferencia por lotes.
Puede comprobar el estado de su trabajo de inferencia por lotes eligiendo el nombre del trabajo correspondiente en la consola de amazon Bedrock. Cuando se complete el trabajo, podrá ver más información sobre el trabajo, incluido el nombre del modelo, la duración del trabajo, el estado y las ubicaciones de los datos de entrada y salida.
Ejecutar el trabajo de inferencia por lotes utilizando la API
Como alternativa, puede iniciar un trabajo de inferencia por lotes mediante programación utilizando el SDK de AWS. Siga estos pasos:
- Cree un cliente de amazon Bedrock:
- Configurar los datos de entrada y salida:
- Iniciar el trabajo de inferencia por lotes:
- Recuperar y monitorear el estado del trabajo:
Reemplazar los marcadores de posición {bucket_name}, {input_prefix}, {output_prefix}, {account_id}, {role_name}, your-job-namey model-of-your-choice con sus valores reales.
Al utilizar el SDK de AWS, puede iniciar y administrar mediante programación trabajos de inferencia por lotes, lo que permite una integración perfecta con sus flujos de trabajo y canales de automatización existentes.
Recopilar y analizar la salida
Cuando se completa el trabajo de inferencia por lotes, amazon Bedrock crea una carpeta dedicada en el depósito S3 especificado, utilizando el ID del trabajo como nombre de carpeta. Esta carpeta contiene un resumen del trabajo de inferencia por lotes, junto con los datos de inferencia procesados en formato JSONL.
Puede acceder a la salida procesada a través de dos métodos convenientes: en la consola de amazon S3 o mediante programación utilizando el SDK de AWS.
Acceda a la salida en la consola de amazon S3
Para utilizar la consola de amazon S3, complete los siguientes pasos:
- En la consola de amazon S3, seleccione Cubos en el panel de navegación.
- Navegue hasta el depósito que especificó como destino de salida para su trabajo de inferencia por lotes.
- Dentro del depósito, localice la carpeta con el ID del trabajo de inferencia por lotes.
Dentro de esta carpeta, encontrará los archivos de datos procesados, que puede explorar o descargar según sea necesario.
Acceda a los datos de salida mediante el SDK de AWS
Como alternativa, puede acceder a los datos procesados mediante programación mediante el SDK de AWS. En el siguiente ejemplo de código, mostramos el resultado del modelo Anthropic Claude 3. Si utilizó un modelo diferente, actualice los valores de los parámetros según el modelo que utilizó.
Los archivos de salida contienen no solo el texto procesado, sino también datos de observabilidad y los parámetros utilizados para la inferencia. El siguiente es un ejemplo en Python:
En este ejemplo, en el que se utiliza el modelo Anthropic Claude 3, después de leer el archivo de salida de amazon S3, procesamos cada línea de los datos JSON. Podemos acceder al texto procesado mediante data('modelOutput')('content')(0)('text')los datos de observabilidad como tokens de entrada/salida, modelo y motivo de detención, y los parámetros de inferencia como tokens máximos, temperatura, top-p y top-k.
En la ubicación de salida especificada para su trabajo de inferencia por lotes, encontrará un manifest.json.out Archivo que proporciona un resumen de los registros procesados. Este archivo incluye información como la cantidad total de registros procesados, la cantidad de registros procesados correctamente, la cantidad de registros con errores y la cantidad total de tokens de entrada y salida.
Luego puede procesar estos datos según sea necesario, como integrarlos en sus flujos de trabajo existentes o realizar análisis más detallados.
Recuerde reemplazar your-bucket-name, your-output-prefixy your-output-file.jsonl.out con sus valores reales.
Al utilizar el SDK de AWS, puede acceder y trabajar mediante programación con los datos procesados, la información de observabilidad, los parámetros de inferencia y la información resumida de sus trabajos de inferencia por lotes, lo que permite una integración perfecta con sus flujos de trabajo y canalizaciones de datos existentes.
Conclusión
La inferencia por lotes para amazon Bedrock ofrece una solución para procesar múltiples entradas de datos en una única llamada API, como se ilustra en nuestro ejemplo de resumen de transcripción de centro de llamadas. Este servicio completamente administrado está diseñado para manejar conjuntos de datos de distintos tamaños, lo que ofrece beneficios para diversas industrias y casos de uso.
Lo invitamos a implementar la inferencia por lotes en sus proyectos y experimentar cómo puede optimizar sus interacciones con FM a escala.
Acerca de los autores
 Yanyan Zhang Yanyan es científica de datos de inteligencia artificial generativa sénior en amazon Web Services, donde ha trabajado en tecnologías de inteligencia artificial y aprendizaje automático de vanguardia como especialista en inteligencia artificial generativa, ayudando a los clientes a utilizar la inteligencia artificial generativa para lograr los resultados deseados. Yanyan se graduó en la Universidad Texas A&M con un doctorado en Ingeniería eléctrica. Fuera del trabajo, le encanta viajar, hacer ejercicio y explorar cosas nuevas.
Yanyan Zhang Yanyan es científica de datos de inteligencia artificial generativa sénior en amazon Web Services, donde ha trabajado en tecnologías de inteligencia artificial y aprendizaje automático de vanguardia como especialista en inteligencia artificial generativa, ayudando a los clientes a utilizar la inteligencia artificial generativa para lograr los resultados deseados. Yanyan se graduó en la Universidad Texas A&M con un doctorado en Ingeniería eléctrica. Fuera del trabajo, le encanta viajar, hacer ejercicio y explorar cosas nuevas.
 Ishan Singh es un científico de datos de IA generativa en amazon Web Services, donde ayuda a los clientes a crear soluciones y productos de IA generativa innovadores y responsables. Con una sólida formación en IA y ML, Ishan se especializa en crear soluciones de IA generativa que generen valor comercial. Fuera del trabajo, le gusta jugar al voleibol, explorar senderos locales para bicicletas y pasar tiempo con su esposa y su perro, Beau.
Ishan Singh es un científico de datos de IA generativa en amazon Web Services, donde ayuda a los clientes a crear soluciones y productos de IA generativa innovadores y responsables. Con una sólida formación en IA y ML, Ishan se especializa en crear soluciones de IA generativa que generen valor comercial. Fuera del trabajo, le gusta jugar al voleibol, explorar senderos locales para bicicletas y pasar tiempo con su esposa y su perro, Beau.
 Rahul Virbhadra Mishra es ingeniero de software sénior en amazon Bedrock. Le apasiona deleitar a los clientes mediante la creación de soluciones prácticas para AWS y amazon. Fuera del trabajo, disfruta de los deportes y valora el tiempo de calidad con su familia.
Rahul Virbhadra Mishra es ingeniero de software sénior en amazon Bedrock. Le apasiona deleitar a los clientes mediante la creación de soluciones prácticas para AWS y amazon. Fuera del trabajo, disfruta de los deportes y valora el tiempo de calidad con su familia.
 Mohd Altaf es un SDE en AWS ai Services con sede en Seattle, Estados Unidos. Trabaja en el área de tecnología de IA/ML de AWS y ha ayudado a desarrollar varias soluciones en diferentes equipos de amazon. En su tiempo libre, le gusta jugar al ajedrez, al billar y a juegos de interior.
Mohd Altaf es un SDE en AWS ai Services con sede en Seattle, Estados Unidos. Trabaja en el área de tecnología de IA/ML de AWS y ha ayudado a desarrollar varias soluciones en diferentes equipos de amazon. En su tiempo libre, le gusta jugar al ajedrez, al billar y a juegos de interior.






{kind=link}