 NEWSLETTER
NEWSLETTER
La inteligencia artificial (IA) y el aprendizaje automático (ML) han experimentado una adopción generalizada en organizaciones empresariales y gubernamentales. El procesamiento de datos no estructurados se ha vuelto más fácil con los avances en el procesamiento del lenguaje natural (NLP) y los servicios de IA/ML fáciles de usar como Amazon Textract, Amazon Transcribe y Amazon Comprehend. Las organizaciones han comenzado a utilizar servicios de IA/ML como Amazon Comprehend para crear modelos de clasificación con sus datos no estructurados para obtener información detallada que no tenían antes. Aunque puede utilizar modelos previamente entrenados con un esfuerzo mínimo, sin una selección de datos y un ajuste de modelos adecuados, no podrá obtener todos los beneficios de los modelos ai/ML.
En esta publicación, explicamos cómo crear y optimizar un modelo de clasificación personalizado utilizando Amazon Comprehend. Demostramos esto utilizando una clasificación personalizada de Amazon Comprehend para crear un modelo de clasificación personalizado de múltiples etiquetas y proporcionamos pautas sobre cómo preparar el conjunto de datos de entrenamiento y ajustar el modelo para cumplir con métricas de rendimiento como exactitud, precisión, recuperación y puntuación F1. Utilizamos los artefactos de salida del entrenamiento del modelo de Amazon Comprehend como una matriz de confusión para ajustar el rendimiento del modelo y guiarlo en la mejora de sus datos de entrenamiento.
Descripción general de la solución
Esta solución presenta un enfoque para crear un modelo de clasificación personalizado optimizado mediante Amazon Comprehend. Pasamos por varios pasos, incluida la preparación de datos, la creación de modelos, el análisis de métricas de rendimiento del modelo y la optimización de la inferencia basada en nuestro análisis. Usamos una computadora portátil de Amazon SageMaker y la Consola de administración de AWS para completar algunos de estos pasos.
También analizamos las mejores prácticas y técnicas de optimización durante la preparación de datos, la creación y el ajuste de modelos.
Requisitos previos
Si no tiene una instancia de cuaderno de SageMaker, puede crear una. Para obtener instrucciones, consulte Crear una instancia de Notebook de Amazon SageMaker.
preparar los datos
Para este análisis, utilizamos el conjunto de datos de Clasificación de comentarios tóxicos de Kaggle. Este conjunto de datos contiene 6 etiquetas con 158.571 puntos de datos. Sin embargo, cada etiqueta solo tiene menos del 10% del total de datos como ejemplos positivos, y dos de las etiquetas tienen menos del 1%.
Convertimos el conjunto de datos de Kaggle existente al formato CSV de dos columnas de Amazon Comprehend con las etiquetas divididas mediante un delimitador de barra vertical (|). Amazon Comprehend espera al menos una etiqueta para cada punto de datos. En este conjunto de datos, encontramos varios puntos de datos que no se incluyen en ninguna de las etiquetas proporcionadas. Creamos una nueva etiqueta llamada limpia y asignamos cualquiera de los puntos de datos que no son tóxicos para que sean positivos con esta etiqueta. Finalmente, dividimos los conjuntos de datos seleccionados en conjuntos de datos de entrenamiento y de prueba utilizando una proporción de 80/20 dividida por etiqueta.
Usaremos el cuaderno de preparación de datos. Los siguientes pasos utilizan el conjunto de datos de Kaggle y preparan los datos para nuestro modelo.
- En la consola de SageMaker, elija Instancias de cuadernos en el panel de navegación.
- Seleccione la instancia del cuaderno que ha configurado y elija Abrir Jupyter.
- Sobre el Nuevo menú, elija Terminal.
- Ejecute los siguientes comandos en la terminal para descargar los artefactos necesarios para esta publicación:
- Cierra la ventana de la terminal.
Deberías ver tres cuadernos y tren.csv archivos.
- Elige el cuaderno Preparación de datos.ipynb.
- Ejecute todos los pasos en el cuaderno.
Estos pasos preparan el conjunto de datos sin procesar de Kaggle para que sirva como conjuntos de datos de prueba y entrenamiento seleccionados. Los conjuntos de datos seleccionados se almacenarán en el portátil y en Amazon Simple Storage Service (Amazon S3).
Considere las siguientes pautas de preparación de datos cuando trabaje con conjuntos de datos de etiquetas múltiples a gran escala:
- Los conjuntos de datos deben tener un mínimo de 10 muestras por etiqueta.
- Amazon Comprehend acepta un máximo de 100 etiquetas. Este es un límite suave que se puede aumentar.
- Asegúrese de que el archivo del conjunto de datos tenga el formato correcto con el delimitador adecuado. Los delimitadores incorrectos pueden introducir etiquetas en blanco.
- Todos los puntos de datos deben tener etiquetas.
- Los conjuntos de datos de entrenamiento y prueba deben tener una distribución equilibrada de datos por etiqueta. No utilice distribución aleatoria porque podría introducir sesgos en los conjuntos de datos de entrenamiento y prueba.
Construya un modelo de clasificación personalizado
Usamos los conjuntos de datos de prueba y entrenamiento seleccionados que creamos durante el paso de preparación de datos para construir nuestro modelo. Los siguientes pasos crean un modelo de clasificación personalizado de múltiples etiquetas de Amazon Comprehend:
- En la consola de Amazon Comprehend, elija Clasificación personalizada en el panel de navegación.
- Elegir Crear nuevo modelo.
- Para Nombre del modeloingrese el modelo de clasificación tóxica.
- Para Nombre de la versióningrese 1.
- Para Anotación y formato de datos.elegir Usando el modo de múltiples etiquetas.
- Para Conjunto de datos de entrenamientoingrese la ubicación del conjunto de datos de capacitación seleccionado en Amazon S3.
- Elegir Conjunto de datos de prueba proporcionado por el cliente e ingrese la ubicación de los datos de prueba seleccionados en Amazon S3.
- Para Datos resultantesingrese la ubicación de Amazon S3.
- Para Rol de IAMseleccionar Crear un rol de IAM, especifique el sufijo del nombre como “comprender-blog”.
- Elegir Crear para iniciar el entrenamiento del modelo de clasificación personalizado y la creación del modelo.
La siguiente captura de pantalla muestra los detalles del modelo de clasificación personalizado en la consola de Amazon Comprehend.
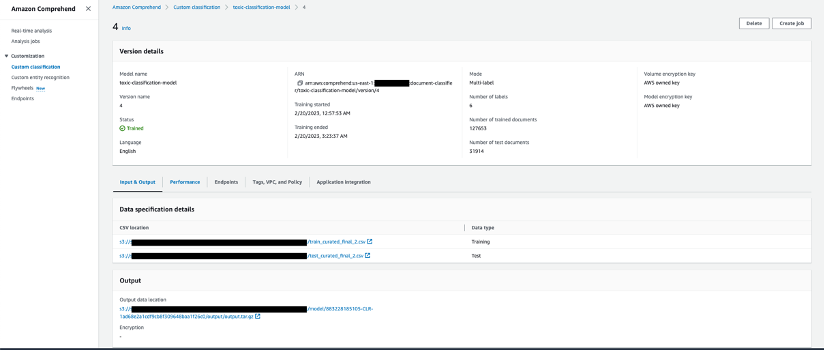
Ajuste para el rendimiento del modelo
La siguiente captura de pantalla muestra las métricas de rendimiento del modelo. Incluye métricas clave como precisión, recuperación, puntuación F1, exactitud y más.
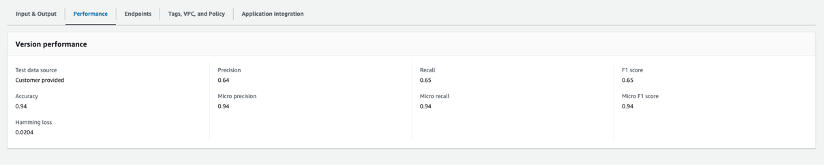
Una vez entrenado y creado el modelo, generará el archivo output.tar.gz, que contiene las etiquetas del conjunto de datos, así como la matriz de confusión para cada una de las etiquetas. Para ajustar aún más el rendimiento de predicción del modelo, debe comprender su modelo con las probabilidades de predicción para cada clase. Para hacer esto, necesita crear un trabajo de análisis para identificar las puntuaciones que Amazon Comprehend asignó a cada uno de los puntos de datos.
Complete los siguientes pasos para crear un trabajo de análisis:
- En la consola de Amazon Comprehend, elija Empleos de Análisis en el panel de navegación.
- Elegir crear trabajo.
- Para Nombreingresar
toxic_train_data_analysis_job. - Para Tipo de análisiselegir Clasificación personalizada.
- Para Modelos de clasificación y volantes.especificar
toxic-classification-model. - Para Versiónespecifique 1.
- Para Ubicación de datos de entrada S3ingrese la ubicación del archivo de datos de entrenamiento seleccionado.
- Para Formato de entradaelegir Un documento por línea.
- Para Ubicación de los datos de salida S3ingrese la ubicación.
- Para Permisos de accesoseleccionar Usar una función de IAM existente y elija el rol creado anteriormente.
- Elegir crear trabajo para iniciar el trabajo de análisis.
- Selecciona el Empleos de Análisis para ver los detalles del trabajo. Tome nota de la identificación del trabajo en Detalles del trabajo. Usaremos la identificación del trabajo en nuestro siguiente paso.
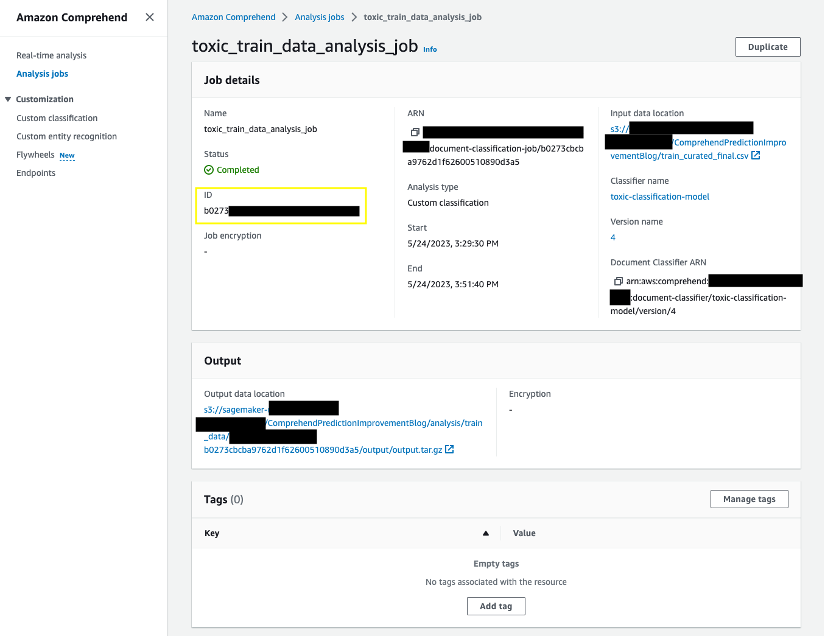
Repita los pasos para iniciar el trabajo de análisis de los datos de prueba seleccionados. Utilizamos los resultados de predicción de nuestros trabajos de análisis para conocer las probabilidades de predicción de nuestro modelo. Tome nota de los identificadores de trabajo de los trabajos de capacitación y análisis de pruebas.
Usamos el Análisis-de-umbral-de-modelo.ipynb cuaderno para probar las salidas en todos los umbrales posibles y calificar la salida en función de la probabilidad de predicción utilizando scikit-learn. precision_recall_curve función. Además, podemos calcular la puntuación F1 en cada umbral.
Necesitaremos la identificación del trabajo del análisis de Amazon Comprehend como entrada para Análisis de umbral de modelo computadora portátil. Puede obtener los identificadores de trabajo desde la consola de Amazon Comprehend. Ejecute todos los pasos en Análisis de umbral de modelo Cuaderno para observar los umbrales de todas las clases.
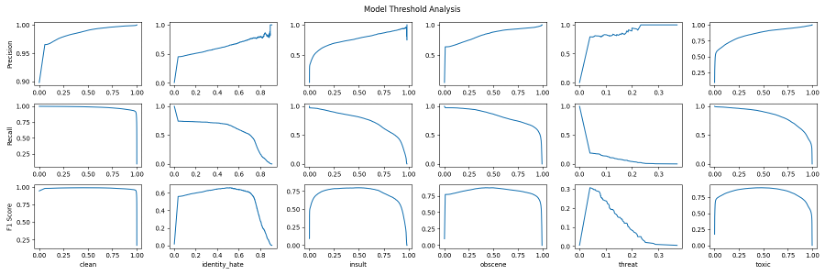
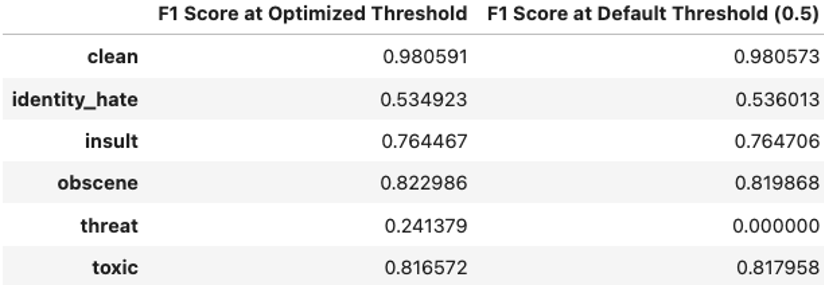
Observe cómo la precisión aumenta a medida que aumenta el umbral, mientras que ocurre lo contrario con la recuperación. Para encontrar el equilibrio entre los dos, utilizamos la puntuación F1 donde tiene picos visibles en su curva. Los picos en la puntuación F1 corresponden a un umbral particular que puede mejorar el rendimiento del modelo. Observe cómo la mayoría de las etiquetas caen alrededor de la marca de 0,5 para el umbral, excepto la etiqueta de amenaza, que tiene un umbral de alrededor de 0,04.

Luego podemos usar este umbral para etiquetas específicas que tienen un rendimiento inferior con solo el umbral predeterminado de 0,5. Al utilizar los umbrales optimizados, los resultados del modelo sobre los datos de prueba mejoran para la amenaza de la etiqueta de 0,00 a 0,24. Estamos utilizando la puntuación F1 máxima en el umbral como punto de referencia para determinar lo positivo frente a lo negativo para esa etiqueta en lugar de un punto de referencia común (un valor estándar como > 0,7) para todas las etiquetas.
Manejo de clases subrepresentadas
Otro enfoque que es eficaz para un conjunto de datos desequilibrado es sobremuestreo. Al sobremuestrear la clase subrepresentada, el modelo ve la clase subrepresentada con mayor frecuencia y enfatiza la importancia de esas muestras. Usamos el Sobremuestreo-subrepresentado.ipynb cuaderno para optimizar los conjuntos de datos.
Para este conjunto de datos, probamos cómo cambia el rendimiento del modelo en el conjunto de datos de evaluación a medida que proporcionamos más muestras. Utilizamos la técnica de sobremuestreo para aumentar la aparición de clases subrepresentadas y mejorar el rendimiento.
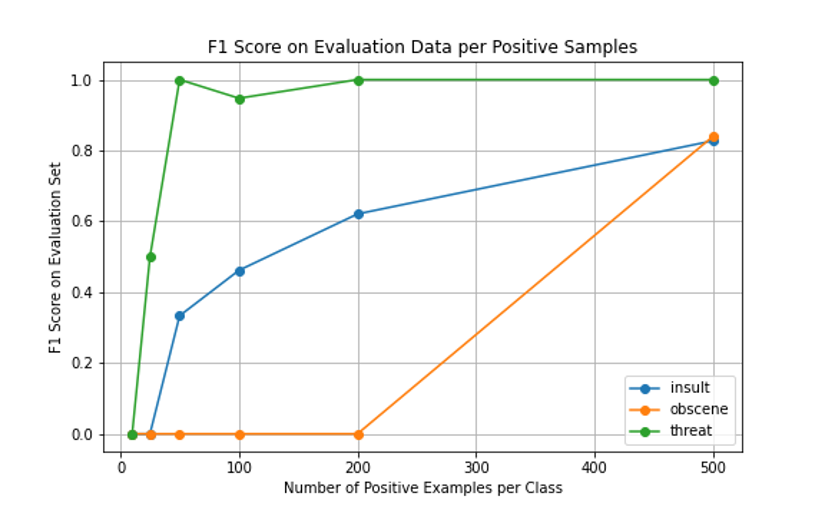
En este caso particular, probamos con 10, 25, 50, 100, 200 y 500 ejemplos positivos. Tenga en cuenta que, aunque repetimos puntos de datos, estamos mejorando inherentemente el rendimiento del modelo al enfatizar la importancia de la clase subrepresentada.
Costo
Con Amazon Comprehend, paga sobre la marcha según la cantidad de caracteres de texto procesados. Consulte Precios de Amazon Comprehend para conocer los costos reales.
Limpiar
Cuando haya terminado de experimentar con esta solución, limpie sus recursos para eliminar todos los recursos implementados en este ejemplo. Esto le ayuda a evitar costos continuos en su cuenta.
Conclusión
En esta publicación, proporcionamos mejores prácticas y orientación sobre la preparación de datos, el ajuste de modelos utilizando probabilidades de predicción y técnicas para manejar clases de datos subrepresentadas. Puede utilizar estas mejores prácticas y técnicas para mejorar las métricas de rendimiento de su modelo de clasificación personalizado de Amazon Comprehend.
Para obtener más información sobre Amazon Comprehend, visite los recursos para desarrolladores de Amazon Comprehend para encontrar recursos de vídeo y publicaciones de blog, y consulte las preguntas frecuentes de AWS Comprehend.
Sobre los autores
![]() Sathya Balakrishnan es un arquitecto sénior de atención al cliente en el equipo de servicios profesionales de AWS y se especializa en datos y soluciones de aprendizaje automático. Trabaja con clientes financieros federales de EE. UU. Le apasiona crear soluciones pragmáticas para resolver los problemas comerciales de los clientes. En su tiempo libre, le gusta ver películas y hacer senderismo con su familia.
Sathya Balakrishnan es un arquitecto sénior de atención al cliente en el equipo de servicios profesionales de AWS y se especializa en datos y soluciones de aprendizaje automático. Trabaja con clientes financieros federales de EE. UU. Le apasiona crear soluciones pragmáticas para resolver los problemas comerciales de los clientes. En su tiempo libre, le gusta ver películas y hacer senderismo con su familia.
 Príncipe Mallari Es científico de datos de PNL en el equipo de servicios profesionales de AWS y se especializa en aplicaciones de PNL para clientes del sector público. Le apasiona utilizar el aprendizaje automático como herramienta para permitir que los clientes sean más productivos. En su tiempo libre, le gusta jugar videojuegos y desarrollar uno con sus amigos.
Príncipe Mallari Es científico de datos de PNL en el equipo de servicios profesionales de AWS y se especializa en aplicaciones de PNL para clientes del sector público. Le apasiona utilizar el aprendizaje automático como herramienta para permitir que los clientes sean más productivos. En su tiempo libre, le gusta jugar videojuegos y desarrollar uno con sus amigos.






{kind=link}