 NEWSLETTER
NEWSLETTER
Esta publicación está coescrita con Pradeep Prabhakaran de Cohere.
Retrieval Augmented Generation (RAG) es una técnica poderosa que puede ayudar a las empresas a desarrollar aplicaciones de inteligencia artificial (IA) generativa que integran datos en tiempo real y permiten conversaciones enriquecidas e interactivas utilizando datos propietarios.
RAG permite que estas aplicaciones de IA accedan a fuentes externas y confiables de conocimiento específico del dominio, lo que enriquece el contexto del modelo de lenguaje a medida que responde a las consultas de los usuarios. Sin embargo, la confiabilidad y precisión de las respuestas depende de encontrar los materiales de origen correctos. Por lo tanto, perfeccionar el proceso de búsqueda en RAG es crucial para aumentar la confiabilidad de las respuestas generadas.
Los sistemas RAG son herramientas importantes para crear sistemas de búsqueda y recuperación, pero a menudo no cumplen con las expectativas debido a que los pasos de recuperación no son óptimos. Esto se puede mejorar mediante un paso de reclasificación para mejorar la calidad de la búsqueda.
RAG es un enfoque que combina técnicas de recuperación de información con procesamiento del lenguaje natural (PLN) para mejorar el rendimiento de las tareas de generación de texto o modelado del lenguaje. Este método implica recuperar información relevante de un gran corpus de datos de texto y utilizarla para aumentar el proceso de generación. La idea clave es incorporar conocimiento externo o contexto al modelo para mejorar la precisión, diversidad y relevancia de las respuestas generadas.
Flujo de trabajo de la orquestación de RAG
La orquestación de RAG generalmente consta de dos pasos:
- Recuperación – RAG obtiene documentos relevantes de una fuente de datos externa mediante las consultas de búsqueda generadas. Cuando se presentan las consultas de búsqueda, la aplicación basada en RAG busca documentos o pasajes relevantes en la fuente de datos.
- Generación con los pies en la tierra – Utilizando los documentos o pasajes recuperados, el modelo de generación crea respuestas fundamentadas con citas en línea utilizando los documentos obtenidos.
El siguiente diagrama muestra el flujo de trabajo de RAG.
Recuperación de documentos en la orquestación RAG
Una técnica para recuperar documentos en una orquestación RAG es la recuperación densa, que es un enfoque de recuperación de información que tiene como objetivo comprender el significado semántico y la intención detrás de las consultas del usuario. La recuperación densa encuentra los documentos más cercanos a una consulta del usuario en la incrustación, como se muestra en la siguiente captura de pantalla.
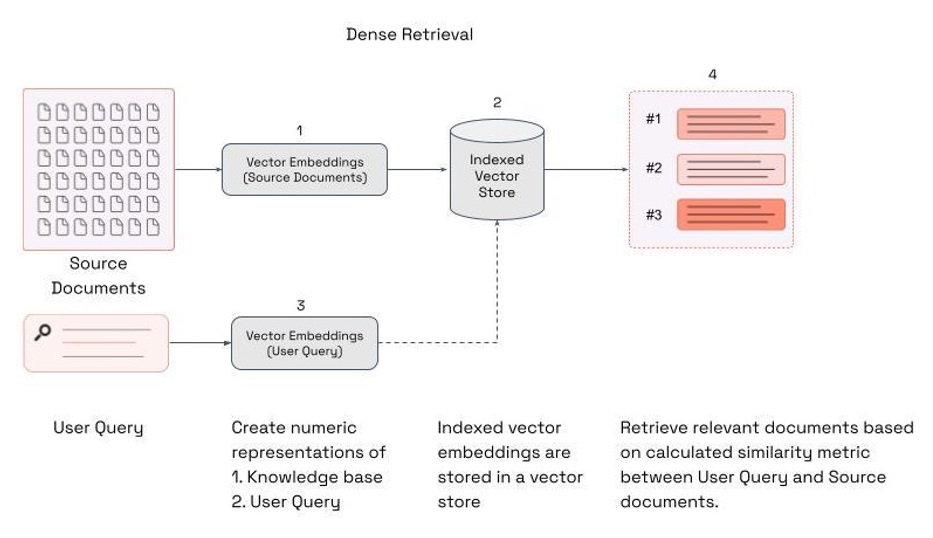
El objetivo de la recuperación densa es mapear tanto las consultas del usuario como los documentos (o pasajes) en un espacio vectorial denso. En este espacio, la similitud entre los vectores de consulta y documento se puede calcular utilizando métricas de distancia estándar como la similitud del coseno o la distancia euclidiana. Los documentos que coinciden más con el significado semántico de la consulta del usuario según las métricas de distancia calculadas se presentan nuevamente al usuario.
La calidad de las respuestas finales a las consultas de búsqueda se ve influenciada significativamente por la relevancia de los documentos recuperados. Si bien los modelos de recuperación densos son muy eficientes y pueden escalarse a grandes conjuntos de datos, tienen dificultades con datos y preguntas más complejos debido a la simplicidad del método. Los vectores de documentos contienen el significado del texto en una representación comprimida, generalmente vectores de 786 a 1536 dimensiones. Esto a menudo da como resultado la pérdida de información porque la información se comprime en un solo vector. Cuando se recuperan documentos durante una búsqueda vectorial, la información más relevante no siempre se presenta en la parte superior de la recuperación.
Mejore la precisión de las búsquedas con Cohere Rerank
Para abordar los desafíos con precisión, los ingenieros de búsqueda han utilizado la recuperación en dos etapas como un medio para aumentar la calidad de la búsqueda. En estos sistemas de dos etapas, un modelo de primera etapa (un modelo de incrustación o recuperador) recupera un conjunto de documentos candidatos de un conjunto de datos más grande. Luego, se utiliza un modelo de segunda etapa (el reranker) para rerankear los documentos recuperados por el modelo de primera etapa.
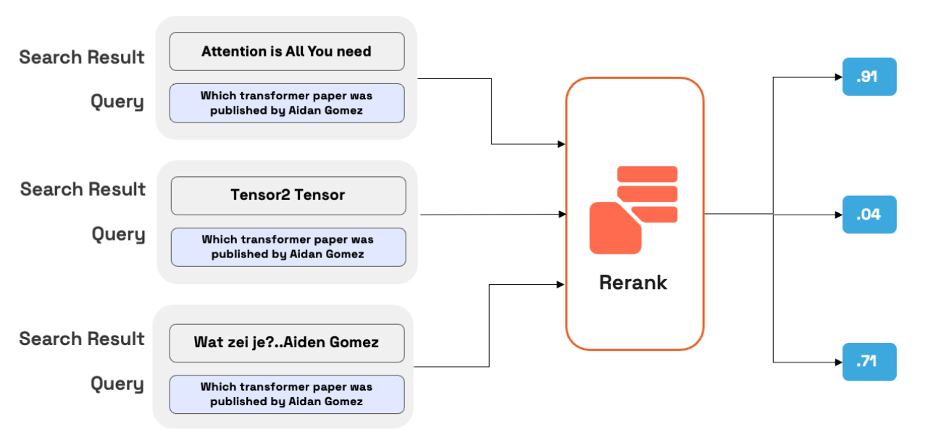
Un modelo de reordenamiento, como Cohere Rerank, es un tipo de modelo que genera una puntuación de similitud cuando se le proporciona un par de consulta y documento. Esta puntuación se puede utilizar para reordenar los documentos que son más relevantes para la consulta de búsqueda. Entre las metodologías de reordenamiento, el modelo Cohere Rerank se destaca por su capacidad de mejorar significativamente la precisión de la búsqueda. El modelo se diferencia de los modelos de incrustación tradicionales al emplear un aprendizaje profundo para evaluar la alineación entre cada documento y la consulta directamente. Cohere Rerank genera una puntuación de relevancia al procesar la consulta y el documento en conjunto, lo que da como resultado un proceso de selección de documentos más matizado.
En el siguiente ejemplo, se presentó a la aplicación una consulta: “¿Cuándo se publicó el artículo sobre transformadores escrito en coautoría por Aidan Gómez?”. El top-k con k = 6 devolvió los resultados que se muestran en la imagen, en la que el conjunto de resultados recuperados contenía el resultado más preciso, aunque estaba al final de la lista. Con k = 3, el documento más relevante no se incluiría en los resultados recuperados.
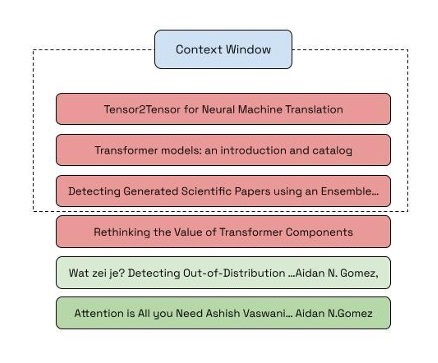
Cohere Rerank tiene como objetivo reevaluar y reordenar la relevancia de los documentos recuperados en función de criterios adicionales, como el contenido semántico, la intención del usuario y la relevancia contextual, para generar una puntuación de similitud. Esta puntuación se utiliza luego para reordenar los documentos según la relevancia de la consulta. La siguiente imagen muestra los resultados de reordenación con Rerank.
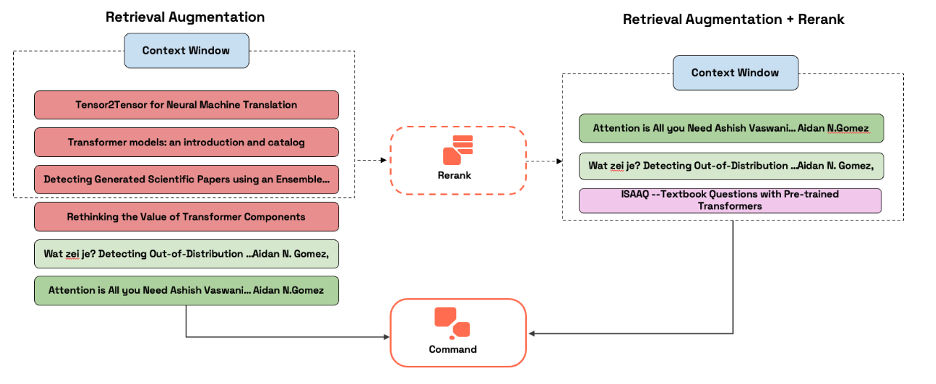
Al aplicar Cohere Rerank después de la recuperación de la primera etapa, la orquestación de RAG puede obtener los beneficios de ambos enfoques. Mientras que la recuperación de la primera etapa ayuda a capturar elementos relevantes en función de las coincidencias de proximidad dentro del espacio vectorial, la reclasificación ayuda a optimizar la búsqueda según los resultados al garantizar que los resultados contextualmente relevantes aparezcan en la parte superior. El siguiente diagrama demuestra esta eficiencia mejorada.
La última versión de Cohere Rerank, Rerank 3, está diseñada específicamente para mejorar la búsqueda empresarial y los sistemas RAG. Rerank 3 ofrece funciones de última generación para la búsqueda empresarial, entre las que se incluyen:
- Longitud de contexto de 4k para mejorar significativamente la calidad de búsqueda de documentos más largos
- Capacidad de buscar en datos multiaspectos y semiestructurados (como correos electrónicos, facturas, documentos JSON, códigos y tablas)
- Cobertura multilingüe de más de 100 idiomas.
- Latencia mejorada y menor costo total de propiedad (TCO)
El punto final recibe una consulta y una lista de documentos, y produce una matriz ordenada en la que se asigna una puntuación de relevancia a cada documento. Esto proporciona un potente impulso semántico a la calidad de búsqueda de cualquier sistema de búsqueda de palabras clave o vectores sin necesidad de realizar ninguna revisión o reemplazo.
Los desarrolladores y las empresas pueden acceder a Rerank en la API alojada de Cohere y en amazon SageMaker. Esta publicación ofrece una guía paso a paso sobre cómo utilizar Cohere Rerank en amazon SageMaker.
Descripción general de la solución
Esta solución sigue estos pasos de alto nivel:
- Suscríbete al paquete modelo
- Cree un punto final y realice inferencias en tiempo real
Prerrequisitos
Para este tutorial, debes tener los siguientes requisitos previos:
- El ai/cohere-aws/blob/3859e2390ad5bf58a29d84a2517824811cabc94e/notebooks/sagemaker/rerank_v3_notebooks/Deploy rerank english v3.0 model.ipynb” target=”_blank” rel=”noopener”>Cohere-aws computadora portátil.
Este es un cuaderno de referencia y no se puede ejecutar a menos que realice los cambios sugeridos en el cuaderno. Contiene elementos que se representan correctamente en la interfaz de Jupyter, por lo que debe abrirlo desde una instancia de cuaderno de amazon SageMaker o en amazon SageMaker Studio.
- Un rol de gestión de acceso e identidad (IAM) de AWS con Acceso completo a AmazonSageMaker Política adjunta. Para implementar este modelo de aprendizaje automático (ML) correctamente, elija una de las siguientes opciones:
- Si su cuenta de AWS no tiene una suscripción a Cohere Rerank 3 Model – Multilingual, su rol de IAM debe tener los siguientes tres permisos y usted debe tener la autoridad para realizar suscripciones a AWS Marketplace en la cuenta de AWS utilizada:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- Si su cuenta de AWS tiene una suscripción a Cohere Rerank 3 Model – Multilingual, puede omitir las instrucciones para suscribirse al paquete de modelos.
- Si su cuenta de AWS no tiene una suscripción a Cohere Rerank 3 Model – Multilingual, su rol de IAM debe tener los siguientes tres permisos y usted debe tener la autoridad para realizar suscripciones a AWS Marketplace en la cuenta de AWS utilizada:
Abstenerse de utilizar el acceso total en entornos de producción. La mejor práctica de seguridad es optar por el principio del mínimo privilegio.
Implementar Rerank 3 en amazon SageMaker
Para mejorar el rendimiento de RAG utilizando Cohere Rerank, utilice las instrucciones de las siguientes secciones.
Suscríbete al paquete modelo
Para suscribirse al paquete modelo, siga estos pasos:
- En AWS Marketplace, abra la página de lista de paquetes de modelos Cohere Rerank 3 Model – Multilingual
- Seleccione Continuar para suscribirse.
- En la página Suscribirse a este software, revise el Acuerdo de licencia de usuario final (EULA), los precios y los términos de soporte y elija Aceptar oferta.
- Seleccione Continuar con la configuración y, a continuación, elija una región. Verá un ARN de producto, como se muestra en la siguiente captura de pantalla. Este es el nombre de recurso de amazon (ARN) del paquete de modelos que debe especificar al crear un modelo implementable con Boto3. Copie el ARN correspondiente a su región e ingréselo en la siguiente celda.
Los fragmentos de código incluidos en esta publicación provienen de aws-cohere ai/cohere-aws/blob/3859e2390ad5bf58a29d84a2517824811cabc94e/notebooks/sagemaker/rerank_v3_notebooks/Deploy rerank english v3.0 model.ipynb” target=”_blank” rel=”noopener”>computadora portátilSi encuentra algún problema con este código, consulte el cuaderno para obtener la versión más actualizada.
!pip install --upgrade cohere-aws
# if you upgrade the package, you need to restart the kernel
from cohere_aws import Client
import boto3En el Configurar para AWS CloudFormation página que se muestra en la siguiente captura de pantalla, bajo Producto Arntome nota de la última parte del ARN del producto para usarla como valor en la variable cohere_package en el siguiente código.
cohere_package = " cohere-rerank-multilingual-v3--13dba038aab73b11b3f0b17fbdb48ea0"
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:865070037744:model-package/{cohere_package}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{cohere_package}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{cohere_package}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{cohere_package}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{cohere_package}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{cohere_package}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{cohere_package}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{cohere_package}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{cohere_package}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{cohere_package}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{cohere_package}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{cohere_package}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{cohere_package}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{cohere_package}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{cohere_package}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{cohere_package}",
}
region = boto3.Session().region_name
if region not in model_package_map.keys():
raise Exception(f"Current boto3 session region {region} is not supported.")
model_package_arn = model_package_map(region)Cree un punto final y realice inferencias en tiempo real
Si desea comprender cómo funciona la inferencia en tiempo real con amazon SageMaker, consulte la Guía para desarrolladores de amazon SageMaker.
Crear un punto final
Para crear un punto final, utilice el siguiente código.
co = Client(region_name=region)
co.create_endpoint(arn=model_package_arn, endpoint_name="cohere-rerank-multilingual-v3-0", instance_type="ml.g5.2xlarge", n_instances=1)
# If the endpoint is already created, you just need to connect to it
# co.connect_to_endpoint(endpoint_name="cohere-rerank-multilingual-v3-0”)Una vez creado el punto final, puedes realizar inferencias en tiempo real.
Crear la carga útil de entrada
Para crear la carga útil de entrada, utilice el siguiente código.
documents = (
{"Title":"Contraseña incorrecta","Content":"Hola, llevo una hora intentando acceder a mi cuenta y sigue diciendo que mi contraseña es incorrecta. ¿Puede ayudarme, por favor?"},
{"Title":"Confirmation Email Missed","Content":"Hi, I recently purchased a product from your website but I never received a confirmation email. Can you please look into this for me?"},
{"Title":"أسئلة حول سياسة الإرجاع","Content":"مرحبًا، لدي سؤال حول سياسة إرجاع هذا المنتج. لقد اشتريته قبل بضعة أسابيع وهو معيب"},
{"Title":"Customer Support is Busy","Content":"Good morning, I have been trying to reach your customer support team for the past week but I keep getting a busy signal. Can you please help me?"},
{"Title":"Falschen Artikel erhalten","Content":"Hallo, ich habe eine Frage zu meiner letzten Bestellung. Ich habe den falschen Artikel erhalten und muss ihn zurückschicken."},
{"Title":"Customer Service is Unavailable","Content":"Hello, I have been trying to reach your customer support team for the past hour but I keep getting a busy signal. Can you please help me?"},
{"Title":"Return Policy for Defective Product","Content":"Hi, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."},
{"Title":"收到错误物品","Content":"早上好,关于我最近的订单,我有一个问题。我收到了错误的商品,需要退货。"},
{"Title":"Return Defective Product","Content":"Hello, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."}
)
Perform real-time inference
To perform real-time inference, use the following code.response = co.rerank(documents=documents, query='What emails have been about returning items?', rank_fields=("Title","Content"), top_n=5)Visualizar la salida
Para visualizar la salida, utilice el siguiente código.
print(f'Documents: {response}')La siguiente captura de pantalla muestra la respuesta de salida.

Limpieza
Para evitar cargos recurrentes, utilice los siguientes pasos para limpiar los recursos creados en este tutorial.
Eliminar el modelo
Ahora que ha realizado una inferencia en tiempo real con éxito, ya no necesita el punto final. Puede finalizar el punto final para evitar que se le cobre.
co.delete_endpoint()
co.close()
Darse de baja del listado (opcional)
Si desea cancelar la suscripción al paquete de modelos, siga estos pasos. Antes de cancelar la suscripción, asegúrese de no tener un modelo implementable creado a partir del paquete de modelos o utilizando el algoritmo. Puede encontrar esta información consultando el nombre del contenedor asociado con el modelo.
Pasos para cancelar la suscripción al producto de AWS Marketplace:
- En la página de suscripciones de Su software, seleccione la opción Aprendizaje automático pestaña
- Localice el listado cuya suscripción desea cancelar y luego seleccione Cancelar suscripción
Resumen
RAG es una técnica capaz de desarrollar aplicaciones de IA que integran datos en tiempo real y permiten conversaciones interactivas utilizando información patentada. RAG mejora las respuestas de IA aprovechando fuentes de conocimiento externas y específicas del dominio, pero su eficacia depende de encontrar los materiales de origen adecuados. Esta publicación se centra en mejorar la eficiencia y la precisión de la búsqueda en sistemas RAG utilizando Cohere Rerank. La orquestación de RAG generalmente implica dos pasos: recuperación de documentos relevantes y generación de respuestas. Si bien la recuperación densa es eficiente para grandes conjuntos de datos, puede tener dificultades con datos y preguntas complejos debido a la compresión de la información. Cohere Rerank utiliza el aprendizaje profundo para evaluar la alineación entre documentos y consultas, lo que genera una puntuación de relevancia que permite una selección de documentos más matizada.
Los clientes pueden encontrar Cohere Rerank 3 y Cohere Rerank 3 Nimble en amazon Sagemaker Jumpstart.
Acerca de los autores
 Shashi Raina Shashi es socio sénior de arquitectura de soluciones en amazon Web Services (AWS), donde se especializa en brindar soporte a empresas emergentes de inteligencia artificial generativa (GenAI). Con casi 6 años de experiencia en AWS, Shashi ha desarrollado una gran experiencia en una variedad de dominios, incluidos DevOps, análisis e inteligencia artificial generativa.
Shashi Raina Shashi es socio sénior de arquitectura de soluciones en amazon Web Services (AWS), donde se especializa en brindar soporte a empresas emergentes de inteligencia artificial generativa (GenAI). Con casi 6 años de experiencia en AWS, Shashi ha desarrollado una gran experiencia en una variedad de dominios, incluidos DevOps, análisis e inteligencia artificial generativa.
 Pradeep Prabhakaran es gerente sénior de arquitectura de soluciones en Cohere. En su puesto actual en Cohere, Pradeep actúa como asesor técnico de confianza para clientes y socios, brindándoles orientación y estrategias para ayudarlos a aprovechar todo el potencial de la plataforma de inteligencia artificial generativa de vanguardia de Cohere.
Pradeep Prabhakaran es gerente sénior de arquitectura de soluciones en Cohere. En su puesto actual en Cohere, Pradeep actúa como asesor técnico de confianza para clientes y socios, brindándoles orientación y estrategias para ayudarlos a aprovechar todo el potencial de la plataforma de inteligencia artificial generativa de vanguardia de Cohere.





{kind=link}