 NEWSLETTER
NEWSLETTER
Deepseek Janus Pro 1B, lanzado el 27 de enero de 2025, es un modelo de IA multimodal avanzado creado para procesar y generar imágenes a partir de indicaciones textuales. Con su capacidad para comprender y crear imágenes basadas en el texto, esta versión de 1 mil millones de parámetros (1B) ofrece un rendimiento eficiente para una amplia gama de aplicaciones, incluida la generación de texto a imagen y la comprensión de la imagen. Además, se destaca en la producción de subtítulos detallados a partir de fotos, por lo que es una herramienta versátil para tareas creativas y analíticas.
Objetivos de aprendizaje
- Analizando su arquitectura y características clave que mejoran sus capacidades.
- Explorando el diseño subyacente y su impacto en el rendimiento.
- Una guía paso a paso para construir un sistema de generación de recuperación (trapo) de la generación de recuperación.
- Utilizando el modelo Deepseek Janus Pro 1 mil millones para aplicaciones del mundo real.
- Comprender cómo Deepseek Janus Pro optimiza las soluciones impulsadas por la IA.
Este artículo fue publicado como parte del Blogathon de ciencias de datos.
¿Qué es Deepseek Janus Pro?
Deepseek Janus Pro es un modelo de IA multimodal que integra el procesamiento de texto e imágenes, capaz de comprender y generar imágenes a partir de indicaciones de texto. La versión de 1 mil millones de parámetros (1B) está diseñada para un rendimiento eficiente en aplicaciones como la generación de texto a la imagen y las tareas de comprensión de imágenes.
Bajo la serie Janus Pro de Deepseek, los modelos principales disponibles son “Janus Pro 1B” y “Janus Pro 7b”, que difieren principalmente en su tamaño de parámetro, con el modelo 7B es significativamente mayor y ofrece un rendimiento mejorado en las tareas de generación de texto a imagen; Ambos se consideran modelos multimodales capaces de manejar la comprensión visual y la generación de texto basada en el contexto visual.
Características clave y aspectos de diseño de Janus Pro 1B
- Arquitectura: Janus Pro utiliza una arquitectura de transformador unificado, pero desacopla la codificación visual en vías separadas para mejorar el rendimiento tanto en la comprensión de la imagen como en las tareas de creación.
- Capacidades: Excelente en tareas relacionadas con la comprensión de las imágenes y la generación de nuevas basadas en las indicaciones de texto. Admite 384 × 384 entradas de imagen.
- Codificadores de imágenes: Para las tareas de comprensión de imágenes, Janus usa Siglip para codificar imágenes. Siglip es un modelo de incrustación de imagen que utiliza el marco de Clip, pero reemplaza la función de pérdida con una pérdida sigmoidea por pares. Para la generación de imágenes, Janus usa un codificador existente de Llamagen, un modo de generación de imágenes autorregresivo. Llamagen es una familia de modelos de generación de imágenes que aplica el siguiente paradigma de predicción de token de modelos de idiomas grandes a una generación visual
- Código abierto: Está disponible en GitHub bajo la licencia MIT, con el uso del modelo gobernado por la licencia Modelo de Deepseek.
Lea también: ¿Cómo acceder a Deepseek Janus Pro 7B?
Arquitectura desacoplada para la comprensión y generación de imágenes
Janus-Pro diverge de modelos multimodales anteriores mediante el empleo de vías separadas y especializadas para la codificación visual, en lugar de depender de un solo codificador visual tanto para la comprensión y la generación de imágenes.
- Codador de comprensión de imágenes. Esta vía extrae características semánticas de imágenes.
- Codador de generación de imágenes. Esta vía sintetiza imágenes basadas en descripciones de texto.
Esta arquitectura desacoplada facilita las optimizaciones específicas de la tarea, mitigando los conflictos entre la interpretación y la síntesis creativa. Los codificadores independientes interpretan características de entrada que luego son procesadas por un transformador autorregresivo unificado. Esto permite que tanto la comprensión multimodal como los componentes de generación seleccionen independientemente sus métodos de codificación más adecuados.
Lea también: ¿Cómo se compara Janus Pro de Deepseek contra Dall-E 3?
Características clave de la arquitectura de modelos
1. Arquitectura de doble vía para la comprensión visual y la generación
- Vía de comprensión visual: Para las tareas de comprensión multimodal, Janus Pro utiliza Siglip-L como el codificador visual, que admite entradas de imágenes de hasta 384 × 384 resolución. Este soporte de alta resolución permite al modelo capturar más detalles de la imagen, mejorando así la precisión de la comprensión visual.
- Vía de generación visual: Para las tareas de generación de imágenes, Janus Pro usa Tokenizer de Llamagen con una tasa de muestreo descendente de 16 para generar imágenes más detalladas.
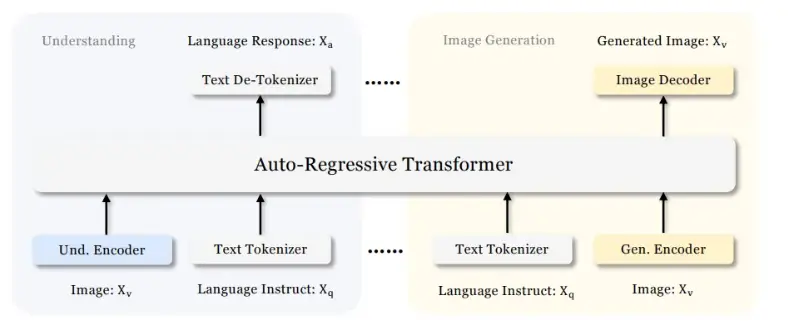
2. Arquitectura de transformador unificado
Se usa una red troncal de transformador compartida para la fusión de características de texto e imagen. Los métodos de codificación independientes para convertir las entradas sin procesar en características se procesan mediante un transformador autorregresivo unificado.
3. Estrategia de entrenamiento optimizada
En la capacitación anterior de Janus, hubo un proceso de entrenamiento de tres etapas para el modelo. La primera etapa se centró en entrenar a los adaptadores y al cabezal de la imagen. La segunda etapa manejó el pretratenamiento unificado, durante los cuales todos los componentes, excepto el codificador comprensivo y el codificador de generación, tienen sus parámetros actualizados. La etapa III cubrió el ajuste supervisado, basándose en la etapa II al desbloquear aún más los parámetros del codificador comprensivo durante el entrenamiento.
Esto se mejoró en Janus Pro:
- Al aumentar los pasos de entrenamiento en la Etapa I, permitiendo suficiente entrenamiento en el conjunto de datos de Imagenet.
- Además, en la Etapa II, para el entrenamiento de generación de texto a imagen, los datos de ImageNet se eliminaron por completo. En cambio, se utilizaron datos normales de texto a imagen para entrenar el modelo para generar imágenes basadas en descripciones densas. Se descubrió que esto mejora la eficiencia de capacitación y el rendimiento general.
Ahora, construamos un trapo multimodal con Deepseek Janus Pro:
Trapo multimodal con modelo de Deepseek Janus Pro 1B
En los siguientes pasos, construiremos un sistema de trapo multimodal para consultar las imágenes basadas en el modelo Deepseek Janus Pro 1B.
Paso 1. Instale las bibliotecas necesarias
!pip install byaldi ollama pdf2image
!sudo apt-get install -y poppler-utils
!git clone https://github.com/deepseek-ai/Janus.git
!pip install -e ./JanusPaso 2. Modelo para guardar incrustaciones de imágenes
import os
from pathlib import Path
from byaldi import RAGMultiModalModel
import ollama
# Initialize RAGMultiModalModel
model1 = RAGMultiModalModel.from_pretrained("vidore/colqwen2-v0.1")Byaldi ofrece un marco fácil de usar para configurar sistemas de trapos multimodales. Como se ve en el código anterior, cargamos Colqwen2, que es un modelo diseñado para una indexación de documentos eficiente utilizando características visuales.
Paso 3. Cargando la imagen PDF
# Use ColQwen2 to index and store the presentation
index_name = "image_index"
model1.index(input_path=Path("/content/PublicWaterMassMailing.pdf"),
index_name=index_name,
store_collection_with_index=True, # Stores base64 images along with the vectors
overwrite=True
)Usamos esto Pdf Para consultar y construir un sistema de trapo en los próximos pasos. En el código anterior, almacenamos la imagen PDF junto con los vectores.
Paso 4. Consulta y recuperación de imágenes guardadas
query = "How many clients drive more than 50% revenue?"
returned_page = model1.search(query, k=1)(0)
import base64
# Example Base64 string (truncated for brevity)
base64_string = returned_page('base64')
# Decode the Base64 string
image_data = base64.b64decode(base64_string)
with open('output_image.png', 'wb') as image_file:
image_file.write(image_data)La página relevante de las páginas del PDF se recupera y se guarda como output_image.png en función de la consulta.
Paso 5. Cargar el modelo Janus Pro
import os
os.chdir(r"/content/Janus")
from janus.models import VLChatProcessor
from transformers import AutoConfig, AutoModelForCausalLM
import torch
from janus.utils.io import load_pil_images
from PIL import Image
processor= VLChatProcessor.from_pretrained("deepseek-ai/Janus-Pro-1B")
tokenizer = processor.tokenizer
vl_gpt = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/Janus-Pro-1B", trust_remote_code=True
)
conversation = (
{
"role": "<|User|>",
"content": f"\n{query}",
"images": ('/content/output_image.png'),
},
{"role": "<|Assistant|>", "content": ""},
)
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
inputs = processor(conversations=conversation, images=pil_images)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**inputs)- Vlchatprocessor.from_preTrainter (“Deepseek-ai/janus-pro-1b”) Carga un procesador previo a la aparición para manejar entradas multimodales (imágenes y texto). Este procesador procesará y preparará datos de entrada (como texto e imágenes) para el modelo.
- El tokenizador se extrae del VlchatProcessor. Tokenizará la entrada de texto, convirtiendo el texto en un formato adecuado para el modelo.
- Automodelforcausallm.From_PreTrained (“Deepseek-ai/janus-pro-1b”) Carga el modelo Janus Pro previamente capacitado, específicamente para el modelado de lenguaje causal.
- También, un formato de conversación multimodal está configurado donde el usuario ingresa tanto texto como una imagen.
- El load_pil_images (conversación) es una función que probablemente carga las imágenes enumeradas en el objeto de conversación y las convierte en formato de imagen PIL, que se usa comúnmente para el procesamiento de imágenes en Python.
- El procesador Aquí hay una instancia de un procesador multimodal (el Procesador Vlchat Del modelo Janus Pro Deepseek), que toma datos de texto e imagen como entrada.
- preparar_inputs_embeds (entradas) es un método que toma las entradas procesadas (las entradas contienen tanto el texto como la imagen), y prepara los incrustaciones requeridas para que el modelo genere una respuesta.
Paso 6. Generación de salida
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs(0).cpu().tolist(), skip_special_tokens=True)
print(answer)El código genera una respuesta del modelo Deepseek Janus Pro 1B utilizando los incrustaciones de entrada preparadas (texto e imagen). Utiliza varios ajustes de configuración como relleno, tokens de inicio/finalización, longitud de token máximo y si usar almacenamiento en caché y muestreo. Después de generar la respuesta, decodifica las ID de token nuevamente en texto legible con humanos usando el tokenizer. La salida decodificada se almacena en la variable de respuesta.
Todo el código está presente en este cuaderno de colab.
Salida para la consulta
Salida para otra consulta
“¿Cuáles han sido los ingresos en Francia?”

La respuesta anterior no es precisa a pesar de que la página relevante fue recuperada por el modelo Colqwen2, el modelo Deepseek Janus Pro 1B no pudo generar la respuesta precisa de la página. La respuesta exacta debe ser de $ 2B.
Salida para otra consulta
“” ¿Cuál ha sido el número de promociones desde el comienzo del año fiscal 2010? “
La respuesta anterior es correcta ya que coincide con el texto mencionado en el PDF.
Conclusiones
En conclusión, el modelo Deepseek Janus Pro 1B representa un avance significativo en la IA multimodal, con su arquitectura desacoplada que optimiza tanto la comprensión de la imagen como las tareas de generación. Al utilizar codificadores visuales separados para estas tareas y refinar su estrategia de entrenamiento, Janus Pro ofrece un rendimiento mejorado en la generación de texto a imagen y el análisis de imágenes. Este enfoque innovador (trapo multimodal con Deepseek Janus Pro), combinado con su accesibilidad de código abierto, lo convierte en una herramienta poderosa para diversas aplicaciones en comprensión visual y creación impulsadas por ai.
Control de llave
- IA multimodal con vías duales: Janus Pro 1B integra tanto el procesamiento de texto como de imagen, utilizando codificadores separados para la comprensión de imágenes (SIGLIP) y la generación de imágenes (Llamagen), mejorando el rendimiento específico de la tarea.
- Arquitectura desacoplada: El modelo separa la codificación visual en vías distintas, lo que permite una optimización independiente para la comprensión y generación de imágenes, minimizando así los conflictos en las tareas de procesamiento.
- Columna vertebral unificada: Una arquitectura de transformador compartido fusiona las características de texto e imágenes, racionalizando la fusión de datos multimodales para un rendimiento de IA más efectivo.
- Estrategia de entrenamiento mejorada: El enfoque de entrenamiento optimizado de Janus Pro incluye un aumento de los pasos en la etapa I y el uso de datos especializados de texto a imagen en la etapa II, lo que aumenta significativamente la eficiencia de la capacitación y la calidad de la producción.
- Accesibilidad de código abierto: Janus Pro 1B está disponible en GitHub bajo la licencia MIT, fomentando el uso y la adaptación generalizados en varias aplicaciones basadas en IA.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se usan a discreción del autor.
Preguntas frecuentes
Ans. Deepseek Janus Pro 1B es un modelo de IA multimodal diseñado para integrar el procesamiento de texto e imágenes, capaz de comprender y generar imágenes a partir de descripciones de texto. Cuenta con 1 mil millones de parámetros para un rendimiento eficiente en tareas como la generación de texto a imagen y la comprensión de la imagen.
Ans. Janus Pro utiliza una arquitectura de transformador unificado con codificación visual desacoplada. Esto significa que emplea vías separadas para la comprensión y generación de imágenes, lo que permite la optimización específica de la tarea para cada tarea.
Ans. Janus Pro mejora las estrategias de capacitación anteriores aumentando los pasos de capacitación, dejando caer el conjunto de datos ImageNet a favor de datos especializados de texto a imagen y centrándose en un mejor ajuste para una mayor eficiencia y rendimiento.
Ans. Janus Pro 1B es particularmente útil para tareas que involucran la generación de texto a imagen, comprensión de imágenes y aplicaciones de IA multimodales que requieren capacidades de procesamiento de imágenes y texto
Ans. Janus-Pro-7b supera a Dall-E 3 en puntos de referencia como Gineval y DPG Bench, según Deepseek. Janus-Pro separa la comprensión/generación, escala los datos/modelos para la generación de imágenes estables, y mantiene una estructura unificada, flexible y rentable. Si bien ambos modelos realizan generación de texto a imagen, Janus-Pro también ofrece subtítulos de imágenes, que Dall-E 3 no.

(Tagstotranslate) Blogathon





