
Generative Artificial Intelligence has become increasingly popular in recent months. Being a subset of AI, it allows Large Language Models (LLM) to generate new data by learning from massive amounts of available textual data. LLMs understand and follow users’ intents and instructions through text-based conversations. These models mimic humans to produce new and creative content, summarize long paragraphs of text, answer questions accurately, etc. LLMs are limited to text-based conversations, which is presented as a limitation as text-only interaction between a human and a computer is not the most optimal form of communication for a powerful AI assistant or chatbot.
Researchers have been trying to integrate visual comprehension capabilities into LLMs, such as the BLIP-2 framework, which pretrains visual language by using pretrained, frozen picture encoders and language decoders. Although efforts have been made to add vision to LLMs, integrating video that contributes to much of the content on social media remains a challenge. This is because it can be difficult to understand non-static visual scenes in video effectively, and it is harder to bridge the modal gap between images and text than it is to bridge the modal gap between video and text because it requires both visual processing as visual. and audio inputs.
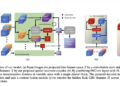
To address the challenges, a team of researchers from DAMO Academy, Alibaba Group, introduced Video-LLaMA, an audiovisual language model tuned to instructions for video comprehension. This multimodal framework enhances language models with the ability to understand the visual and auditory content of videos. Video-LLAMA explicitly addresses the difficulties of integrating audiovisual information and the challenges of temporal changes in visual scenes, in contrast to previous vision-LLMs that focus solely on understanding static images.
The team also presented a Video Q-former that captures temporal changes in visual scenes. This component assembles the pretrained image encoder into the video encoder and allows the model to process video frames. Using a video-to-text generation task, the model is trained on the connection between videos and textual descriptions. ImageBind has been used to integrate audiovisual signals as a pretrained audio encoder. It is a universal embedding model that aligns various modalities and is known for its ability to handle various input types and generate unified embeddings. Audio Q-former has also been used on top of ImageBind to learn reasonable audio query embeddings for the LLM module.
Video-LLaMA has been trained on large-scale video and image subtitle pairs to align the output of the visual and audio encoders with the LLM embedding space. This training data allows the model to learn the correspondence between visual and textual information. Video-LLaMA fine-tunes on visual instruction fitting data sets providing higher quality data to train the model to generate responses based on visual and auditory information.
Upon evaluation, experiments have shown that Video-LLaMA can perceive and understand video content, and produces insightful responses that are influenced by the audiovisual data offered in the videos. In conclusion, Video-LLaMA has a lot of potential as a prototype AI audiovisual assistant that can react to both visual and audio inputs in videos and can empower LLMs with audio and video comprehension capabilities.
review the Paper and Github. Don’t forget to join our 23k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at [email protected]
🚀 Check out 100 AI tools at AI Tools Club
Tanya Malhotra is a final year student at the University of Petroleum and Power Studies, Dehradun, studying BTech in Computer Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a data science enthusiast with good analytical and critical thinking, along with a keen interest in acquiring new skills, leading groups, and managing work in an organized manner.



{kind=link}