 NEWSLETTER
NEWSLETTER
Retrieval Augmented Generation (RAG) improves the output of large language models (LLM) using external knowledge bases. These systems work by retrieving relevant information linked to the input and including it in the model response, improving accuracy and relevance. However, the RAG system raises issues related to data security and privacy. These knowledge bases will be prone to contain sensitive information that can be accessed viciously when cues may lead the model to reveal sensitive information. This creates significant risks in applications such as customer support, organizational tools, and medical chatbots, where protecting sensitive information is essential.
Currently, methods used in recovery-augmented generation (RAG) systems and large language models (LLM) face significant vulnerabilities, especially when it comes to data privacy and security. Approaches such as membership inference attacks (MIA) attempt to identify whether specific data points belong to the training set. Still, the most advanced techniques focus on stealing sensitive knowledge directly from RAG systems. Methods, such as TGTB and PIDE, rely on static indications from data sets, which limits their adaptability. Dynamic Greedy Embedding Attack (DGEA) introduces adaptive algorithms but requires multiple iterative comparisons, making it complex and resource-intensive. Rag-Thief (RThief) uses memory mechanisms to extract text fragments, but its flexibility depends largely on predefined conditions. These approaches struggle with efficiency, adaptability, and effectiveness, often leaving RAG systems prone to privacy violations.
To address privacy issues in retrieval-augmented generation (RAG) systems, researchers from the University of Perugia, the University of Siena and the University of Pisa proposed a relevance-based framework designed to extract private knowledge and at the same time discourage repetitive information leakage. The framework employs open source language models and sentence encoders to automatically explore hidden knowledge bases without relying on pay-as-you-go services or knowledge of the system beforehand. Unlike other methods, this method learns progressively and tends to maximize coverage of the private knowledge base and broader exploration.
The framework operates in a blind context by leveraging a feature representation map and adaptive strategies to explore the private knowledge base. It is implemented as a black box attack that runs on standard home computers and does not require specialized hardware or external APIs. This approach emphasizes transferability between RAG configurations and provides a simpler and more cost-effective method of exposing vulnerabilities compared to previous non-adaptive or resource-intensive methods.
The researchers attempted to systematically discover private KKK knowledge and replicate it on the attacker's system as K∗K^*K∗. They achieved this by designing adaptive queries that exploited a relevance-based mechanism to identify high-relevance “anchors” correlated with hidden knowledge. Open source tools, including a small commercially available LLM and a text encoder, were used for query preparation, embedding creation, and similarity comparison. The attack followed a step-by-step algorithm that adaptively generated queries, extracted and updated anchors, and refined relevance scores to maximize knowledge exposure. Duplicate fragments and anchors were identified and discarded using cosine similarity thresholds to ensure efficient and noise-tolerant data extraction. The process continued iteratively until all anchors had zero relevance, effectively stopping the attack.
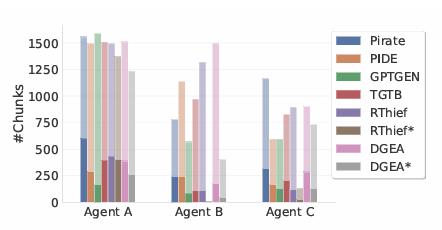
The researchers conducted experiments that simulated real-world attack scenarios on three RAG systems using different LLMs on the attacker side. The goal was to extract as much information as possible from private knowledge bases, and each RAG system implemented a chatbot-like virtual agent for user interaction through natural language queries. Three agents were defined: Agent A, a diagnostic support chatbot; Agent B, chemistry and medicine research assistant; and Agent C, children's educational assistant. Private knowledge bases were simulated using datasets, with 1000 fragments sampled per agent. The experiments compared the proposed method with competitors such as TGTB, PIDE, DGEA, RThief, and GPTGEN in different settings, including limited and unlimited attacks. Metrics such as browsing coverage, filtered knowledge, filtered fragments, unique filtered fragments, and attack query generation time were used for evaluation. The results showed that the proposed method outperformed competitors in navigation coverage and knowledge leakage in limited scenarios, with even more advantages in unlimited scenarios, outperforming RThief et al.
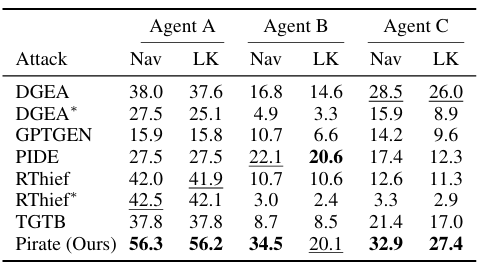
In conclusion, the suggested method presents an adaptive attack procedure that extracts private knowledge from RAG systems, outperforming competitors in terms of coverage, leaked knowledge, and time required to generate queries. This highlighted challenges such as the difficulty in comparing extracted fragments and the need for much stricter safeguards. The research can form a basis for future work on developing stronger defense mechanisms, targeted attacks, and improved evaluation methods for RAG systems.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Divyesh is a Consulting Intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of technology Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies in agriculture and solve challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}