 NEWSLETTER
NEWSLETTER
Artificial intelligence (AI) large language models (LLMs) can generate text, translate languages, write various forms of creative material, and provide helpful answers to your questions. However, LLMs have a few issues, such as the fact that they are trained on large datasets of text and code that may contain biases. The results produced by LLMs may reflect these prejudices, reinforcing negative stereotypes and spreading false information. Sometimes, LLMs will produce writing that has no basis in reality. Hallucination describes these experiences. Misinterpretation and erroneous inferences might result from reading hallucinatory text. It takes work to get a handle on how LLMs function inside. Because of this, it’s hard to understand the reasoning behind the models’ actions. This may cause issues in contexts where openness and responsibility are crucial, such as the medical and financial sectors. Training and deploying LLMs takes a large amount of computing power. They may become inaccessible to many smaller firms and nonprofits. Spam, phishing emails, and fake news are all examples of bad information that can be generated using LLMs. Users and businesses alike may be put in danger because of this.
Researchers from NVIDIA have collaborated with industry leaders like Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (now part of Databricks), OctoML, Tabnine, and Together AI to speed up and perfect LLM inference. These enhancements will be included in the forthcoming open-source NVIDIA TensorRT-LLM software version. TensorRT-LLM is a deep learning compiler that utilizes NVIDIA GPUs to provide state-of-the-art performance thanks to its optimized kernels, pre-and post-processing phases, and multi-GPU/multi-node communication primitives. Developers can experiment with new LLMs without needing in-depth familiarity with C++ or NVIDIA CUDA, providing top-notch performance and rapid customization options. With its open-source, modular Python API, TensorRT-LLM makes it simple to define, optimize, and execute new architectures and improvements as LLMs develop.
By leveraging NVIDIA’s latest data center GPUs, TensorRT-LLM hopes to increase LLM throughput while reducing expenses greatly. For creating, optimizing, and running LLMs for inference in production, it provides a straightforward, open-source Python API that encapsulates the TensorRT Deep Learning Compiler, optimized kernels from FasterTransformer, pre-and post-processing, and multi-GPU/multi-node communication.
TensorRT-LLM allows for a wider variety of LLM applications. Now that we have 70-billion-parameter models like Meta’s Llama 2 and Falcon 180B, a cookie-cutter approach is no longer practical. The real-time performance of such models is typically dependent on multi-GPU configurations and complex coordination. By providing tensor parallelism that distributes weight matrices among devices, TensorRT-LLM streamlines this process and eliminates the need for manual fragmentation and rearrangement on the part of developers.
The in-flight batching optimization is another notable feature tailored to manage the extremely fluctuating workloads typical of LLM applications effectively. This function enables dynamic parallel execution, which maximizes GPU usage for tasks like question-and-answer engagements in chatbots and document summarization. Given the increasing size and scope of AI implementations, businesses can anticipate reduced total cost of ownership (TCO).
The results in terms of performance are mind-blowing. Performance on benchmarks shows an 8x gain in tasks like article summarization when using TensorRT-LLM with NVIDIA H100 compared to the A100.
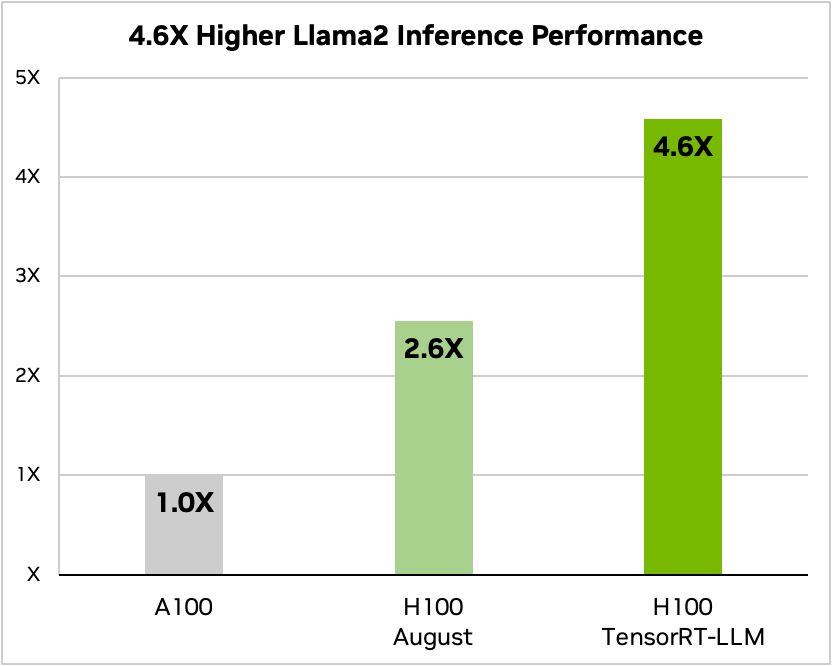
TensorRT-LLM can increase inference performance by 4.6x compared to A100 GPUs on Llama 2, a widely used language model released recently by Meta and used by many businesses wishing to implement generative AI.
Text summarization, variable I/O length, CNN / DailyMail dataset | A100 FP16 PyTorch eager mode| H100 FP8 | H100 FP8, in-flight batching, TensorRT-LLM | Image Source: https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/
To summarize, LLMs are developing quickly. Each day brings a new addition to the ever-expanding ecosystem of model designs. As a result, larger models open up new possibilities and use cases, boosting adoption in every sector. The data center is evolving due to LLM inference. TCO is improved for businesses due to higher performance with higher precision. Better client experiences, made possible through model changes, lead to increased sales and profits. There are numerous additional factors to consider when planning inference deployment initiatives to get the most out of state-of-the-art LLMs. Rarely does optimization occur by itself. Users should think about parallelism, end-to-end pipelines, and sophisticated scheduling methods as they perform fine-tuning. They need a computer system that can handle data of varying degrees of precision without sacrificing accuracy. TensorRT-LLM is a straightforward, open-source Python API for creating, optimizing, and running LLMs for inference in production. It features TensorRT’s Deep Learning Compiler, optimized kernels, pre-and post-processing, and multi-GPU/multi-node communication.
Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
References:
- https://developer.nvidia.com/blog/nvidia-tensorrt-llm-supercharges-large-language-model-inference-on-nvidia-h100-gpus/
- https://developer.nvidia.com/tensorrt-llm-early-access
![]()
Prathamesh Ingle is a Mechanical Engineer and works as a Data Analyst. He is also an AI practitioner and certified Data Scientist with an interest in applications of AI. He is enthusiastic about exploring new technologies and advancements with their real-life applications
 The end of project management by humans (Sponsored)
The end of project management by humans (Sponsored) 





{kind=link}