 NEWSLETTER
NEWSLETTER
The development of ai agents capable of making independent decisions, especially for several steps tasks, is an important challenge. Deep thicknessA leader in the progress of the great language models and reinforcement learning, focuses on allowing ai to process information, predicts the results and adjust the actions as situations evolve. Underline the importance of proper reasoning in dynamic configuration. The new development of Deepseekai captures avant -garde methods in reinforcement learning, large language models and agents based on agents to ensure that the research and current applications of ai are kept aware. It deals with many common problems, such as decision -making inconsistencies, long -term planning problems and the inability to adapt to changing conditions. However, ai can take suboptimal actions or even make mistakes without an adequate reasoning mechanism.
Many IA training methodologies suffer inconsistent processing problems, which, in turn, leads to errors in tasks that require multiple decision -making rounds. These approaches do not describe an environment that, through the ai action, provides a complete understanding of the consequences, due to which the results are not analyzed and dark. In addition, training is implemented in a step -by procedure by which there are breaks in learning sequences, and reward functions become unstable, resulting in the lack of adequate long -term political development. Therefore, the decision and problem solving systems become inefficient and ineffective. Deepseekai resolves this dilemma by providing a more integrated and well -transmitted training, helping ai to make good, consistent and reliable decisions while quickly adapts to new environments.
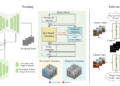
Meet ExcelThe first reproduction of Deepseek-R1 (-Cero) Methods to train agent models, to address the challenges in the training of ai agents for real -steps and real -world reasoning. Deepseekai, known for its advances in large language models and reinforcement learning, developed Deepseek-R1 To improve agent reasoning through structured training. Unlike other methods that fight with the processing of inconsistent lots, limited planning and unstable rewards, Excel Agenda line training using a two -phase approach: a deployment phase where environmental states and reasoning tokens generated by the model are processed together and an update phase in which only critical tokens (actions and rewards) They contribute to learning, guaranteeing display of stable lots and improving decision making. The framework efficiently avoids the instability of the variable sequence lengths by generating reasoning and action tokens during deployment, executing only actions in the environment and reinforcing strategic planning through the aggregation of rewards in the update phase. Tested in the puzzle of Sokoban, Excel He showed that smaller models work comparable to the largest and that models without explicit instructions adapt well. Excel Improves sequential decision making when reproducing the Deepseek-R1 training methodology, so it is valuable for applications such as logistics automation and ai attendees.
In the end, Excel Improves the training of ai agents eliminating inconsistent decision making, unstable rewards and planning limitations. By imitating the Deepseek-R1 approach, it guarantees stable learning and better adaptability. Tabled in Sokoban's puzzle, he showed that smaller models work well as an efficiency indicator. As a baseline for future research, Ragen can help refine ai training methods, improve reinforcement learning and support advances in general use ai systems.
Verify he Github page. All credit for this investigation goes to the researchers of this project. Besides, don't forget to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LINKEDIN GRsplash. Do not forget to join our 70k+ ml of submen.
Know Intellagent: A framework of multiple open source agents to evaluate a complex conversational system (Promoted)
Divyesh is a consulting intern in Marktechpost. He is looking for a BTECH in agricultural and food engineering of the Indian Institute of technology, Kharagpur. He is a data science enthusiast and automatic learning that wants to integrate these leading technologies in the agricultural domain and solve challenges.





{kind=link}