 NEWSLETTER
NEWSLETTER
Text-to-image synthesis refers to the process of generating realistic images from descriptions of textual messages. This technology is an offshoot of generative models in the field of artificial intelligence (AI) and has been gaining more and more attention in recent years.
Text-to-image generation aims to enable neural networks to interpret and translate human language into visual representations, allowing for a wide variety of synthesis combinations. Also, unless otherwise taught, the generative network results in several different images for the same textual description. This can be extremely useful for gathering new ideas or portraying the exact vision that we have in mind but can’t find on the internet.
This technology has potential applications in various fields, such as virtual and augmented reality, digital marketing, and entertainment.
Among the most widely adopted text-to-image generative networks, we find diffusion models.
 Best Image Annotation Tools in 2023
Best Image Annotation Tools in 2023
Text-to-image diffusion models generate images by iteratively refining a noise distribution conditioned by text input. They encode the given textual description into a latent vector, which affects the noise distribution, and iteratively refine the noise distribution using a diffusion process. This process results in diverse, high-resolution images that match the input text, achieved through a U-net architecture that captures and incorporates visual features of the input text.
The conditioned space in these models is known as the P space, defined by the token embedding space of the language model. Essentially, P represents the textual conditioning space, where an input instance “p“belonging to P (which has passed through a text encoder) is injected into all attention layers of a U network during synthesis.
The following is an overview of the text conditioning mechanism of a denoising diffusion model.
Through this process, from a single instance, “p”, is fed to the U-net architecture, the unraveling obtained and control over the encoded text is limited.
For this reason, the authors introduce a new conditioning space for the text called P+.
This space consists of multiple textual conditions, each injected into a different layer in the U-grid. Over here, P+ can ensure greater expressiveness and unraveling, providing better control of the synthesized image. As the authors describe, the different layers of the U network have varying degrees of control over the attributes of the synthesized image. In particular, thick layers mainly affect the structure of the image, while thin layers predominantly influence its appearance.
Having presented the P+ space, the authors introduce a related process called Extended Textual Inversion (XTI). It refers to a revised version of classic textual inversion (TI), a process in which the model learns to represent a specific concept described in a few input images as a dedicated token. In XTI, the goal is to invert the input images into a set of tile overlays, one per layer, i.e. inversion in P+.
To clearly establish the difference between the two, imagine providing the image of a “green lizard” at the input of a two-layer U-net. TI’s goal is to get “green lizard” in the output, while XTI requires two different instances in the output, which in this case would be “green” and “lizard”.
The authors prove in their work that the process of expanded investment in P+ it is not only more expressive and precise than TI, but also faster.
In addition, the increase in unraveling in P+ allows blending via text to image generation such as object style blending.
An example of the aforementioned work is reported below.
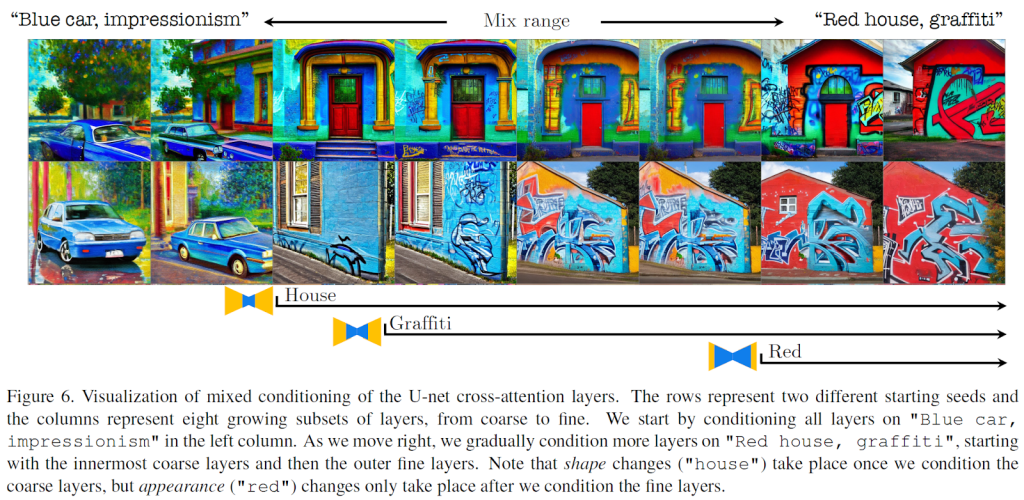
This was the summary of P+rich text conditioning space for extended text inversion.
review the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 16k+ ML SubReddit, discord channeland electronic newsletterwhere we share the latest AI research news, exciting AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He currently works at the Christian Doppler ATHENA Laboratory and his research interests include adaptive video streaming, immersive media, machine learning and QoS / QoE evaluation.




{kind=link}