 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have demonstrated impressive proficiency in numerous tasks, but their ability to perform multi-step reasoning remains a major challenge. This limitation becomes particularly evident in complex scenarios such as solving mathematical problems, controlling embedded agents, and web browsing. Traditional reinforcement learning (RL) methods, such as proximal policy optimization (PPO), have been applied to address this problem, but they often entail high computational and data costs, making them less practical. Similarly, methods such as direct preference optimization (DPO), while effective at aligning models with human preferences, struggle with multi-step reasoning tasks. DPO's reliance on pairwise preference data and uniform token treatment undermines its ability to allocate credit effectively in low-reward situations. These obstacles highlight the need for more targeted and efficient solutions to improve LLM reasoning capabilities.
Introducing OREO: Offline Reasoning Optimization
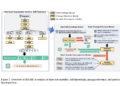
OREO (Offline REasoning Optimization) is an offline RL approach specifically designed to address the shortcomings of existing methods to improve multi-step reasoning for LLMs. Developed collaboratively by researchers at UC San Diego, Tsinghua University, Salesforce Research, and Northwestern University, OREO is based on insights from maximum entropy reinforcement learning. Train a policy model and a value function simultaneously by optimizing the smooth Bellman equation. This methodology eliminates the reliance on pairwise preference data, allowing the use of unpaired data sets with sparse rewards. Additionally, OREO allows for the precise allocation of credits along reasoning trajectories, which is especially beneficial when success depends on a few critical steps. The framework can also be extended to iterative exploration settings and incorporates a learned value function to improve inference through tree search during testing.
Technical details and benefits
OREO's main innovation lies in optimizing the smooth Bellman equation to simultaneously train policy and value models. This strategy ensures accurate credit allocation at all reasoning steps, addressing the limitations of methods such as DPO. Additionally, OREO offers step-level and response-level objectives, providing flexibility for different granularities of reasoning tasks. During test-time inference, the value function supports advanced search techniques such as beam search, which improves accuracy. Unlike benchmark methods such as supervised fine-tuning (SFT) or rejection sampling, OREO excels at leveraging failed trajectories to improve model robustness and adaptability. This ability to learn from failure makes it particularly valuable for iterative, multi-step reasoning tasks.
Results and insights
OREO's performance has been rigorously evaluated on benchmarks such as GSM8K and MATH for mathematical reasoning, and ALFWorld for embedded agent control. Key findings include:
- On GSM8K, OREO achieved a 5.2% relative improvement in accuracy using a 1.5 billion parameter model compared to SFT, along with a 10.5% improvement on MATH.
- 52.5% in MATHEMATICS with 1.5 billion LLM (without use of increased problem set)
- On ALFWorld, OREO achieved a 17.7% relative improvement in performance in unseen environments, underscoring its ability to generalize beyond the training data.
Iterative training further amplified the effectiveness of OREO, showing consistent gains in accuracy across multiple iterations. While approaches such as rejection sampling showed diminishing returns, OREO continued to improve by incorporating insights from failed attempts. Searching at test time using OREO's value function resulted in a relative improvement of up to 17.9% over greedy decoding on the MATH dataset, highlighting its impact on inference quality.
Conclusion
OREO provides a practical and effective solution to improve multi-step reasoning in LLM through offline RL. By addressing the limitations of existing approaches, it offers a scalable method to improve reasoning capabilities. Its integration of detailed credit assignment, iterative training, and exam-time searching makes it a versatile tool for addressing complex reasoning challenges. The results demonstrate the potential of OREO for application in a variety of domains that require sophisticated problem solving, contributing to the evolution of artificial intelligence systems capable of deeper reasoning.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}