 NEWSLETTER
NEWSLETTER
Pretrained models that speak many languages have performed excellently on natural language interpretation challenges. Large volumes of unlabeled data in hundreds of languages are often used to train these models. Despite being pre-trained primarily on English data, recent huge language models have remarkable multilingual abilities. All of these models, however, have one thing in common: they can only hold so many different language representations. As a result, the models perform poorly on languages with less pretrained data and more pretrained languages. The “curse of multilingualism” is another name for it.
For existing multilingual models, natural language production tasks bring additional problems, as they can overfit the training languages and partially forget their ability to generate in the target language, resulting in text that has the correct meaning. but it must be spelled correctly. The “source language hallucination problem” is how they describe this. Google DeepMind researchers suggest the multilingual modular T5, the first multilingual modular generative model, to overcome these two drawbacks. To increase multilingual modeling capability, mmT5 assigns a modest number of language-specific parameters during pretraining.
By freezing language-specific modules during fine tuning and common parameter adjustment, they allow direct adaptation to a target language by switching to the appropriate language-specific module. They also point out another area of improvement with mmT5: the adjusted shared representations could diverge from the decoder’s frozen modular representations. Therefore, the modular approach is much like its non-modular counterparts, which are prone to producing content in the wrong language. They suggest freezing a part of the common decoder parameters to help with this, which makes a significant difference in zero-throw multilingual generation for modular generative models.
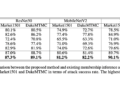
They find that the mmT5 model effectively addresses two drawbacks of stream-to-stream multilingual models: 1) By allowing more modeling capability to be added to multiple languages during pre-training, mmT5 alleviates the curse of multilingualism. In a typical collection of multilingual NLU and NLG tasks, it outperforms conventional and mT5 baselines with the same parameter sizes; Furthermore, mmT5 impressively addresses the problem of source language hallucinations in zero-shot multilingual text production. According to his research, for a zero-throw multilingual abstract job, mT5 only produces text in the target language 7% of the time, but mmT5 produces the text in the correct language 99% of the time.
A modular multilingual codec model called mmT5 has been suggested. Most of the mmT5 parameters used during multilingual pretraining are shared between tasks, but each language also receives a limited number of parameters that are unique to that language. They showed that adding modularity as an architectural inductive bias greatly increases training efficiency, achieving the same perplexity as a comparable fully dense model in a quarter of the update steps. Across a wide range of tasks, including question answering, semantic analysis, summarizing, and classification, in both multilingual and zero-shot contexts, mmT5 significantly outperforms comparable models.
Finally, they demonstrate that the model reliably produces text in the target language while fitting mmT5 in a target task in a source language by freezing certain regions of the decoder. Therefore, modularity eliminates source-language hallucinations in cases of cross-language transmission.
review the Paper. Don’t forget to join our 23k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at asif@marktechpost.com
 Check out 100 AI tools at AI Tools Club
Check out 100 AI tools at AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. She is currently pursuing her bachelor’s degree in Information Science and Artificial Intelligence at the Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects aimed at harnessing the power of machine learning. Her research interest is image processing and she is passionate about creating solutions around her. She loves connecting with people and collaborating on interesting projects.





{kind=link}