 NEWSLETTER
NEWSLETTER
The rise of the information age has brought an overwhelming amount of data in various formats. Documents, presentations and images are generated at an astonishing rate in multiple languages and domains. However, retrieving useful information from these various sources presents a significant challenge. Conventional retrieval models, while effective for text-based queries, struggle with complex multimodal content such as screenshots or slideshows. This poses particular challenges for businesses, researchers and educators, who need to query and extract information from documents that combine text and visuals. To address this challenge, a model capable of efficiently handling such diverse content is required.
Introducing mcdse-2b-v1: a new approach to document recovery
Meet mcdse-2b-v1a new ai model that allows you to embed screenshots of pages or slides and query them using natural language. Unlike traditional retrieval systems, which rely solely on text for indexing and searching, mcdse-2b-v1 allows users to work with screenshots or slides that contain a combination of text, images, and diagrams. This opens up new possibilities for those who often work with documents that are not purely text-based. With mcdse-2b-v1You can take a screenshot of a slideshow or infographic-heavy document, embed it in the model, and perform natural language searches for relevant information.
mcdse-2b-v1 It bridges the gap between traditional text-based queries and more complex visual data, making it ideal for industries that require frequent content analysis of presentations, reports, or other visual documentation. This capability makes the model invaluable in content-rich environments, where manual navigation through visual-heavy documents is time-consuming and impractical. Instead of struggling to find a presentation slide or manually reviewing dense reports, users can leverage natural language to instantly search for embedded content, saving time and improving productivity.
Technical details and benefits
mcdse-2b-v1 () is based on MrLight/dse-qwen2-2b-mrl-v1 and is trained using the DSE approach. mcdse-2b-v1 is an effective, scalable and efficient multilingual document retrieval model that can seamlessly handle mixed content sources. Provides an embedding mechanism that effectively captures textual and visual components, enabling robust retrieval operations on multimodal data types.
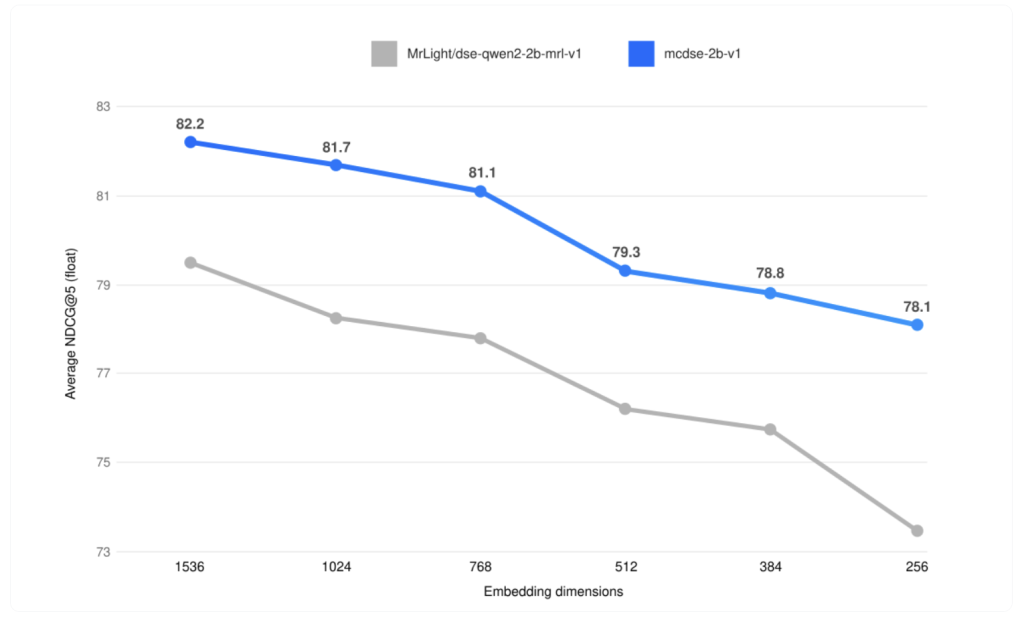
One of the most notable features of mcdse-2b-v1 is its resource efficiency. For example, you can fit 100 million pages in just 10 GB of space. This level of optimization makes it ideal for applications where data storage is scarce, such as on-premises solutions or edge deployments. Additionally, the model can be scaled down by up to six times with minimal performance degradation, allowing it to run on devices with limited computational resources while maintaining high retrieval accuracy.
Another benefit of mcdse-2b-v1 It is its compatibility with commonly used frameworks such as Transformers or vLLM, which makes it accessible to a wide range of users. This flexibility allows the model to be easily integrated into existing machine learning workflows without major modifications, making it a convenient option for developers and data scientists.
Why mcdse-2b-v1 is important
The importance of mcdse-2b-v1 It lies not only in its ability to retrieve information efficiently but also in how it democratizes access to the analysis of complex documents. Traditional document retrieval methods require precise structuring and often overlook the rich visual elements present in modern documents. mcdse-2b-v1 changes this by allowing users to access information embedded in diagrams, charts, and other non-textual components as easily as they would with a text-based query.
The first results have shown that mcdse-2b-v1 Consistently delivers high retrieval accuracy, even when compressed to one-sixth of its original size. This level of performance makes it practical for large-scale deployments without the typical computational overhead. Additionally, its multilingual capability means it can serve a wide range of users around the world, making it valuable in multinational organizations or academic environments where multiple languages are used.
For those working on multi-modal recovery augmented generation (RAG), mcdse-2b-v1 offers a scalable solution that provides high-performance embeds for documents that include text and images. This combination improves the capability of downstream tasks, such as answering complex user queries or generating detailed reports from multimodal inputs.
Conclusion
mcdse-2b-v1 addresses the challenges of multimodal document retrieval by incorporating page and slide screenshots with scalability, efficiency, and multilingual capabilities. Streamlines interactions with complex documents, freeing users from the tedious process of manual searches. Users get a powerful retrieval model that effectively handles multimodal content, recognizing the complexities of real-world data. This model reshapes the way we access and interact with knowledge embedded in both text and images, setting a new benchmark for document retrieval.
look at the Model hugging face and Details. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}