
The development of vision-language models (VLM) has faced challenges in handling complex visual question answering tasks. Despite substantial advances in reasoning capabilities using large language models like OpenAI's GPT-o1, VLMs still struggle with systematic and structured reasoning. Current models often lack the ability to organize information and engage in logical and sequential reasoning, limiting their effectiveness for tasks that require deep cognitive processing, particularly when dealing with multimodal inputs such as images combined with text. Traditional VLMs tend to generate immediate answers without a step-by-step reasoning approach, leading to errors and inconsistencies.
Get to know LLaVA-o1
A team of researchers from Peking University, Tsinghua University, Peng Cheng Laboratory, Alibaba DAMO Academy and Lehigh University has presented LLaVA-o1: a visual language model capable of systematic reasoning, similar to GPT-o1 . LLaVA-o1 is an 11 billion parameter model designed for multi-stage autonomous reasoning. It is based on the Llama-3.2-Vision-Instruct model and introduces a structured reasoning process, addressing the limitations of previous VLMs with a more methodical approach. The key innovation in LLaVA-o1 is the implementation of four distinct reasoning stages: summary, title, reasoning, and conclusion.
The model is fine-tuned using a dataset called LLaVA-o1-100k, derived from visual question answering (VQA) feeds and structured reasoning annotations generated by GPT-4o. This allows LLaVA-o1 to perform multi-stage reasoning, extending GPT-o1-like capabilities in vision and language tasks, which have historically lagged behind text-based models.
Technical details and benefits
LLaVA-o1 employs a novel inference time scaling technique called stage-level beam search. Unlike previous methods such as sentence-level best-of-N beam search, LLaVA-o1 generates multiple answers for each stage of its structured reasoning process and selects the best candidate at each step, guaranteeing results. of higher quality. This structured approach maintains logical consistency throughout the reasoning process, leading to more accurate conclusions.
Fine-tuned from the Llama-3.2-11B-Vision-Instruct model, LLaVA-o1 shows an 8.9% improvement in multimodal reasoning benchmarks compared to its base model, outperforming even larger or code-based competitors. closed like Gemini-1.5-pro, GPT. -4o-mini and Llama-3.2-90B-Vision-Instruct. It achieves this with only 100,000 training samples, making LLaVA-o1 an efficient solution in terms of performance and scalability. By employing structured thinking through different stages, LLaVA-o1 systematically addresses problems, minimizing reasoning errors common in other VLMs.
Importance and results
LLaVA-o1 addresses a significant gap between textual and visual question answering models by enabling systematic reasoning in vision and language tasks. Experimental results show that LLaVA-o1 improves performance on benchmarks such as MMStar, MMBench, MMVet, MathVista, AI2D, and HalllusionBench. It consistently outperforms its base model by over 6.9% on multimodal benchmarks, particularly in reasoning-intensive domains such as visual math and science questions.
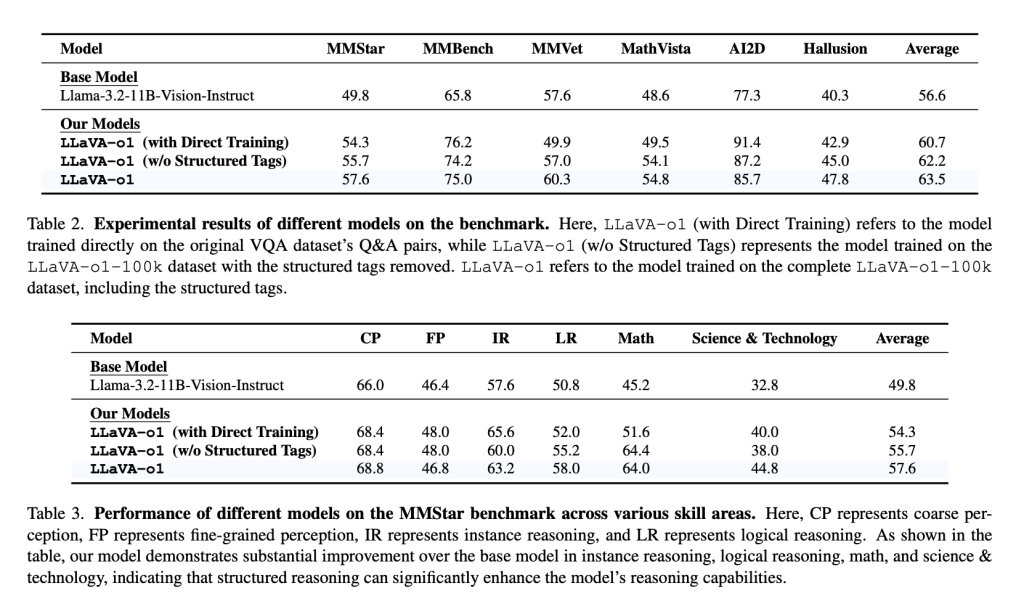
Stage-level beam search improves model reliability by generating and verifying multiple candidate responses for each stage, selecting the most appropriate one. This allows LLaVA-o1 to excel in complex visual tasks, compared to traditional inference scaling methods that can be inefficient. LLaVA-o1 demonstrates that structured responses are crucial to achieving consistent, high-quality reasoning, setting a new standard for similarly sized models.
Conclusion
LLaVA-o1 is a visual language model capable of systematic reasoning, similar to GPT-o1. Its four-stage reasoning structure, combined with stage-level beam search, sets a new benchmark for multimodal ai. By training on a relatively small but strategically constructed dataset, LLaVA-o1 demonstrates that efficient and scalable multimodal reasoning can be achieved without the massive resources that larger closed-source models require. LLaVA-o1 paves the way for future research on structured reasoning within vision and language models, promising more advanced capabilities in ai-driven cognitive processing in the visual and textual domains.
look at the Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
Why ai language models remain vulnerable: Key insights from Kili technology's report on large language model vulnerabilities (Read the full whitepaper here)
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}