 NEWSLETTER
NEWSLETTER
As artificial intelligence continues to permeate all facets of technology, optimizing the performance of large language models (LLMs) for practical applications has become a fundamental challenge. The arrival of Transformer-based LLMs has revolutionized the way we interact with ai, enabling applications ranging from conversational agents to complex problem-solving tools. However, the widespread deployment of these models, especially in scenarios where they process batches of sequences that share common prefixes, has highlighted a major efficiency bottleneck. Traditional attention mechanisms, while critical to the success of LLMs, often struggle with computational redundancy when sequences within a batch share a starting point. This inefficiency overloads computing resources and limits the scalability of LLM applications.
To address this challenge, an innovative approach by the research team at Stanford University, the University of Oxford and the University of Waterloo called Hydragen has been introduced. Hydragen is cleverly designed to optimize LLM inference in shared prefix scenarios, dramatically improving performance and reducing computational overhead. By decomposing the attention operation into separate calculations for shared prefixes and unique suffixes, Hydragen minimizes redundant memory reads and maximizes the efficiency of matrix multiplications, a process better aligned with the capabilities of modern GPUs. This decomposition allows attention queries to be grouped into sequences by processing the shared prefix, which significantly improves computational efficiency.
Hydragen's innovation lies in its two-pronged approach. First, she decomposes the attention mechanism to address shared prefixes and distinct sequence suffixes separately. This strategy cleverly avoids the inefficiencies of traditional attention calculations, which treat each sequence independently, leading to unnecessary repetition of calculations for shared segments. Second, Hydragen introduces cross-stream batching for the shared prefix, taking advantage of the uniformity of this cross-stream segment to perform a single, consolidated attention calculation. This method reduces the workload on the GPU and ensures that the computational power of the tensor cores is used to its full potential.
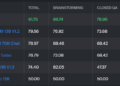
Hydragen's impact is profound, delivering up to a 32x improvement in end-to-end LLM performance compared to existing methods. This performance improvement is particularly significant as it scales with both batch size and shared prefix length, showing Hydragen's adaptability to various scales and operational scenarios. Additionally, Hydragen's methodology extends beyond simple prefix and suffix splits, and accommodates more complex tree-based exchange patterns common in advanced LLM applications. This flexibility allows Hydragen to significantly reduce inference times in diverse environments, from chatbot interactions to competitive programming challenges.
The results of Hydragen's implementation are compelling and underline its ability to transform LLM inference. Hydragen not only dramatically increases performance, but also enables efficient processing of very long shared contexts with minimal performance penalty. This means that LLMs can now handle longer, context-rich prompts without a corresponding increase in computational cost or time. For example, in tasks that involve answering questions about long documents, Hydragen demonstrates its superiority by processing queries in much less time than traditional methods, even when dealing with documents with tens of thousands of long tokens.
In conclusion, the development of Hydragen marks an important milestone in optimizing LLMs for real-world applications. Key findings from this research include:
- Innovative decomposition: Hydragen's unique attention decomposition method significantly improves the computational efficiency of batching sequences with shared prefixes.
- Improved performance: Hydragen demonstrates up to 32x performance improvement, setting a new standard for LLM performance, especially in large batch and shared prefix scenarios.
- Versatile application: The methodology adapts to complex patterns of exchange, making it suitable for a wide range of LLM applications, from conversational ai to complex problem-solving tools.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter and Google news. Join our 36k+ ML SubReddit, 41k+ Facebook community, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Hello, my name is Adnan Hassan. I'm a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a double degree from the Indian Institute of technology, Kharagpur. I am passionate about technology and I want to create new products that make a difference.
<!– ai CONTENT END 2 –>





{kind=link}