
Medical artificial intelligence (ai) holds great promise, but comes with its own set of challenges. Unlike simple math problems, medical tasks often require a deeper level of reasoning to support real-world diagnoses and treatments. The complexity and variability of medical scenarios make it difficult to effectively verify reasoning processes. As a result, existing healthcare-specific large language models (LLMs) often fail to provide the accuracy and reliability needed for high-risk applications. Closing these gaps requires creative approaches to data training and model design, an effort that HuatuoGPT-o1 intends to comply.
What is HuatuoGPT-o1?
A team of researchers from the Chinese University of Hong Kong and the Shenzhen Big Data Research Institute present HuatuoGPT-o1: a medical LLM designed to improve reasoning abilities in healthcare.. It is constructed using a data set of 40,000 carefully selected and verifiable medical problems. This model outperforms general-purpose and domain-specific LLMs by following a two-stage learning process. First, it develops complex reasoning skills through feedback-driven iterations. Second, hone these skills with reinforcement learning (RL). This dual approach allows HuatuoGPT-o1 to create detailed chains of thought (CoT), iteratively refine its answers, and align its solutions with verifiable results. These capabilities make it an essential tool for addressing the complex challenges of medical reasoning.
| Backbone | Supported languages | Link | |
|---|---|---|---|
| HuatuoGPT-o1-8B | LLaMA-3.1-8B | English | HF link |
| HuatuoGPT-o1-70B | LLaMA-3.1-70B | English | HF link |
| HuatuoGPT-o1-7B | Qwen2.5-7B | english and chinese | HF link |
| HuatuoGPT-o1-72B | Qwen2.5-72B | english and chinese | HF link |
Technical advances
The development of HuatuoGPT-o1 brought several important advances. The data set for training came from challenging medical examinations, transformed into open problems with unique and objective answers. A medical verifier, powered by GPT-4o, verifies the correctness of the solutions, allowing the model to develop robust reasoning pathways. These pathways are integrated into the model during fitting, encouraging reflective and iterative thinking.
In the second stage, reinforcement learning, specifically proximal policy optimization (PPO), is employed to further improve the model. The verifier's sparse rewards guide this process, helping HuatuoGPT-o1 hone its reasoning accuracy. This step-by-step problem-solving approach ensures that the model can effectively handle the demands of real-world medical applications.
Performance and findings
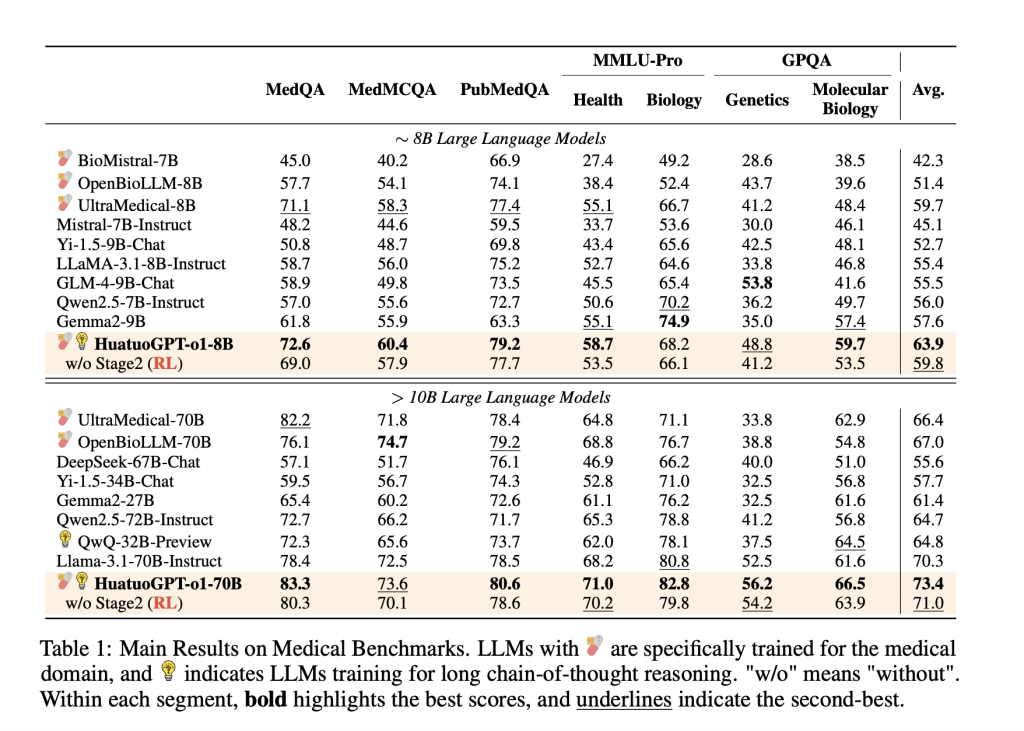
HuatuoGPT-o1 has shown impressive results on various benchmarks. He The 8 billion parameter version delivered an 8.5 point improvement over its baseline, while the 70 billion parameter version outperformed leading medical LLMs on datasets such as MedQA and PubMedQA . Its ability to perform well on both traditional and complex data sets underlines its strong reasoning capabilities.
Ablation studies emphasized the importance of the two-stage training process of the model. Models that omitted reinforcement learning showed weaker performance, highlighting the value of tester-guided CoT and RL improvements. Additionally, the medical verifier showed great reliability, achieving a 96.5% accuracy rate during the first stage of training, a testament to its crucial role in the overall process.
Conclusion
HuatuoGPT-o1 represents an important step forward in medical ai. By combining advanced reasoning techniques with a structured training process, it addresses long-standing challenges in reasoning and verification. Their success, achieved with a relatively small data set, highlights the impact of well-thought-out training methods. As ai continues to evolve in healthcare, models like HuatuoGPT-o1 have the potential to improve the accuracy of diagnosis and treatment planning, setting a benchmark for future developments in this field.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}