 NEWSLETTER
NEWSLETTER
The demand for powerful and versatile language models has become more pressing in natural language processing and artificial intelligence. These models are the backbone of numerous applications, from chatbots and virtual assistants to machine translation and sentiment analysis. However, building language models that can excel in various language tasks remains a complex challenge. This is the central problem that a recent breakthrough aims to address.
In the quest to develop advanced language models, researchers have often encountered limitations associated with model size, training data, and versatility. These limitations have led to a fragmented landscape where different models excel in specific tasks, but only some can truly claim to be a one-size-fits-all solution.
Technology Innovation Institute (TII) researchers introduced a groundbreaking language model: Falcon 180B. Falcon 180B represents a leap forward in language models, boasting 180 billion parameters. But what sets it apart from its predecessors and competitors is its size and the promise of versatility and accessibility. While Falcon 180B is not the first large language model, it is distinctive in its open-access nature. Unlike many closed-source models that remain proprietary, Falcon 180B is designed to be available for research and commercial use. This shift towards open access aligns with a broader trend in the AI community, where transparency and collaboration are increasingly valued.
Falcon 180B’s remarkable capabilities result from its extensive training on a diverse dataset containing a staggering 3.5 trillion tokens. This vast corpus of text gives the model an unparalleled understanding of language and context, allowing it to excel in a wide range of natural language processing tasks
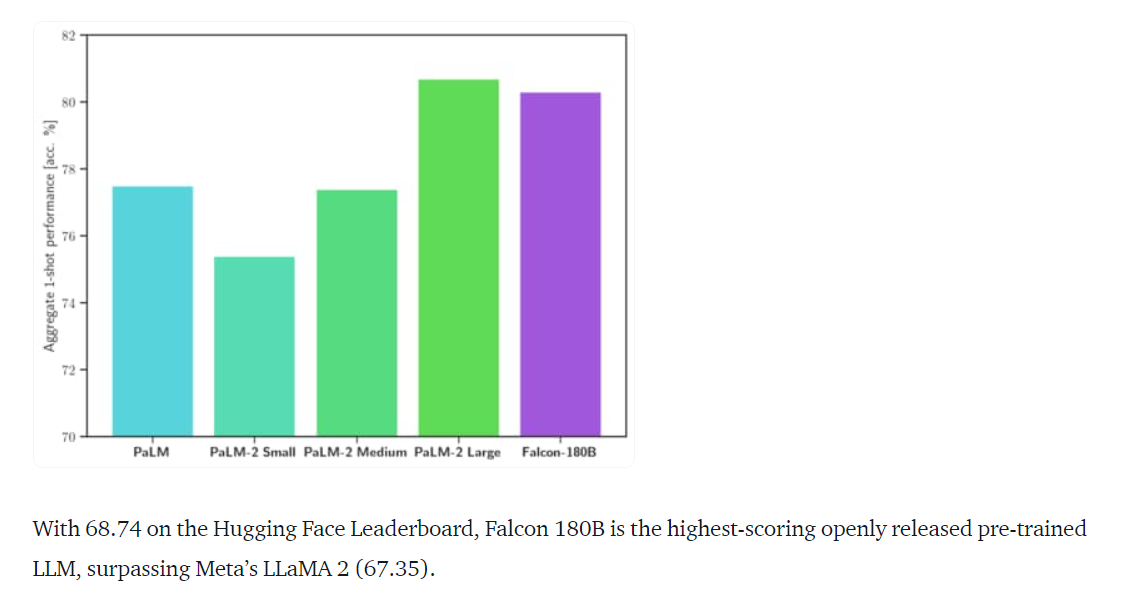
.One of the model’s key strengths is its ability to handle diverse language tasks, including reasoning, coding, proficiency assessments, and knowledge testing. This versatility is a testament to its training on a rich and varied dataset that includes web data, conversations, technical papers, and even a fraction of code. Falcon 180B’s performance in these tasks rivals and often surpasses closed-source competitors like Meta’s LLaMA 2.
It’s important to highlight the model’s ranking on the Hugging Face Leaderboard, where it currently holds a competitive score 68.74. This leaderboard ranking solidifies Falcon 180B’s position as a top-tier language model capable of addressing many language-related challenges.
In conclusion, Falcon 180B from TII represents a significant step forward in natural language processing. Its size, training data, and open-access availability make it a powerful and versatile tool for researchers and developers alike. The decision to provide open access to Falcon 180B is particularly noteworthy, as it aligns with the growing importance of transparency and collaboration in the AI community.
The implications of Falcon 180B’s introduction are far-reaching. By offering an open-access model with 180 billion parameters, TII empowers researchers and developers to explore new horizons in natural language processing. Compared to closed-source counterparts, this model’s competitive performance opens the door to innovation across various domains, including healthcare, finance, education, and more.
Moreover, Falcon 180B’s success underscores the value of open-source initiatives in AI. It demonstrates that when researchers prioritize collaboration and accessibility, breakthroughs in AI become more accessible to a wider audience. As the AI community continues to evolve and embrace open-source principles, Falcon 180B is a shining example of what can be achieved through transparency, collaboration, and a commitment to pushing the boundaries of AI capabilities. With Falcon 180B and similar initiatives, AI’s future is promising and more inclusive and collaborative, ultimately benefiting society as a whole.
Check out the Reference Article and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Madhur Garg is a consulting intern at MarktechPost. He is currently pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Technology (IIT), Patna. He shares a strong passion for Machine Learning and enjoys exploring the latest advancements in technologies and their practical applications. With a keen interest in artificial intelligence and its diverse applications, Madhur is determined to contribute to the field of Data Science and leverage its potential impact in various industries.
 Check out Noah AI: ChatGPT with Hundreds of Your Google Drive Documents, Spreadsheets, and Presentations (Sponsored)
Check out Noah AI: ChatGPT with Hundreds of Your Google Drive Documents, Spreadsheets, and Presentations (Sponsored) 





{kind=link}