 NEWSLETTER
NEWSLETTER
In recent years, there has been a notable appearance of robust and cross-modal models capable of generating one type of information from another, such as transforming text into text, images or audio. One example is the remarkable stable spread, which can generate amazing images from an input indicator that describes the expected result.
Despite offering realistic results, these models face limitations in their practical application when multiple modalities coexist and interact. Suppose we want to generate an image from a text description like “cute puppy sleeping on a leather sofa”. However, that is not enough. After receiving the output image of a text-to-image model, we also want to hear what that situation would sound like, for example, with the puppy snoring on the couch. In this case, we would need another model to transform the resulting text or image into a sound. Therefore, while it is possible to connect multiple specific generative models in a multi-step build scenario, this approach can be cumbersome and time consuming. Additionally, independently generated unimodal streams will lack consistency and alignment when combined in a form of post-processing, such as video and audio synchronization.
A comprehensive and versatile any-to-any model could simultaneously generate consistent video, audio, and text descriptions, improving the overall experience and reducing the time required.
 Unleash the power of Live Proxies: private and undetectable residential and mobile IPs.
Unleash the power of Live Proxies: private and undetectable residential and mobile IPs. In pursuit of this goal, Composable Diffusion (CoDi) has been developed to simultaneously process and generate arbitrary combinations of modalities.
The architecture overview is reported below.
Training a model to handle any combination of input modalities and flexibly generate various combinations of output involves significant computational and data requirements.
This is due to the exponential growth of the possible combinations of entry and exit modalities. In addition, obtaining aligned training data for many groups of modalities is very limited and non-existent, which makes it unfeasible to train the model using all possible input and output combinations. To address this challenge, a strategy is proposed to align multiple modalities in the input generation and conditioning diffusion step. Furthermore, a “bridge alignment” strategy for contrastive learning efficiently models the exponential number of input-output combinations with a linear number of training targets.
Achieving a model with the ability to generate any combination and maintaining high-quality generation requires a comprehensive model design and training approach that takes advantage of diverse data resources. The researchers have taken an integrative approach to building CoDi. First, they train a latent diffusion model (LDM) for each modality, such as text, image, video, and audio. These LDMs can be trained independently and in parallel, ensuring excellent generation quality for each individual modality using available modality-specific training data. This data consists of inputs with one or more modes and an output mode.
For conditional cross-modality generation, where combinations of modalities are involved, such as image generation using audio and language cues, the input modalities are projected onto a shared feature space. This multimodal conditioning mechanism prepares the diffusion model to condition any modality or combination of modalities without requiring direct training for specific settings. The output BOM then services the combined input features, allowing for cross-modality generation. This approach allows CoDi to handle various modality combinations effectively and generate high-quality results.
The second stage of training in CoDi facilitates the model’s ability to handle many-to-many generation strategies, allowing the simultaneous generation of various combinations of output modes. According to current knowledge, CoDi stands as the first AI model to possess this ability. This achievement is made possible by the introduction of a cross-attention module in each diffuser and a V-environment encoder, which maps the latent variables of different LDMs into a shared latent space.
During this stage, the LDM parameters are frozen and only the cross-attention and V parameters are trained. As the environment encoder aligns the representations of different modalities, an LDM can cross-assist with any set of cogenerated modalities at the same time. interpolate the output representation using V. This seamless integration allows CoDi to generate arbitrary combinations of modalities without the need to train on all possible generational combinations. Consequently, the number of training targets is reduced from exponential to linear, providing significant efficiency in the training process.
Some output samples produced by the model are reported below for each build task.
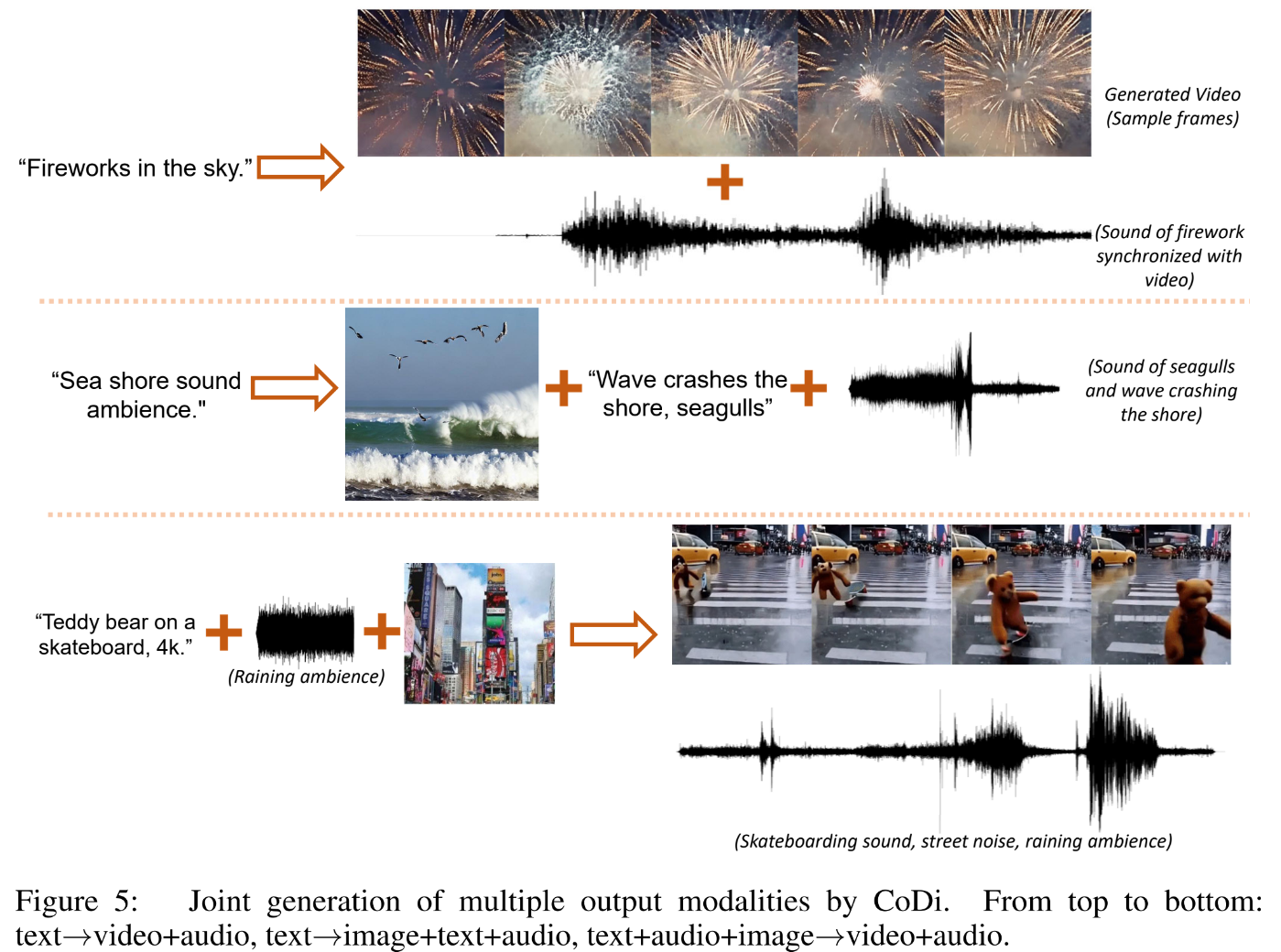
This was the summary of CoDi, an efficient cross-modal generation model for any generation with top quality. If you are interested, you can learn more about this technique at the links below.
review the Paper and Github. Don’t forget to join our 25k+ ML SubReddit, discord channel, and electronic newsletter, where we share the latest AI research news, exciting AI projects, and more. If you have any questions about the article above or if we missed anything, feel free to email us at asif@marktechpost.com
featured tools Of AI Tools Club
 Check out 100 AI tools at AI Tools Club
Check out 100 AI tools at AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He currently works at the Christian Doppler ATHENA Laboratory and his research interests include adaptive video streaming, immersive media, machine learning and QoS / QoE evaluation.






{kind=link}