 NEWSLETTER
NEWSLETTER

Image created by the author using DE-E 3
“Computers are like bicycles for our minds,” Steve Jobs once commented. Let's think about pedaling through the scenic landscape of Web Scraping with ChatGPT as your guide.
Apart from its other great uses, ChatGPT can be your guide and companion in learning anything, including Web Scraping. And remember, we're not just talking about learning Web Scraping; We're talking about rethinking how we learn it.
Buckle up for sections that marry curiosity with code and explanations. Let us begin.
We need a big plan here. Web Scraping can help you do novel data science projects that will attract employers and can help you find your dream job. Or you can even sell the data you extract. But before all this, you must make a plan. Let's explore what I'm talking about.
First things first: let's make a plan
Albert Einstein once said, “If I had an hour to solve a problem, I would spend 55 minutes thinking about the problem and five minutes thinking about solutions.” In this example, we will follow his logic.
To learn Web Scraping, you must first define which coding library to use. For example, if you want to learn Python for data science, you should divide it into subsections, such as:
- web scraping
- Data exploration and analysis
- Data visualization
- Machine learning
This way, we can divide Web Scraping into subsections before making our selection. We still have many minutes to spend. Here are the Web Scraping libraries;
- Requests
- Scrappy
- beautifulsopa
- Selenium
Great, let's say you've chosen BeautifulSoup. I would advise you to prepare an excellent table of contents. You can choose this table of contents from a book you found on the web. Let's say the first two sections of your table of contents will look like this:
Qualification: Master web scraping with BeautifulSoup
Content
Section 1: Web Scraping Fundamentals
- Introduction to web scraping
- Getting started with Python and BeautifulSoup
- Understand HTML and DOM structure
Section 2: Basic Setup and Techniques
- Setting up your web scraping environment
- Basic Techniques in BeautifulSoup
Also, don't research the eBook mentioned above as I created it just for this example.
Now you have your table of contents. It's time to follow your daily learning schedule. Let's say today you want to learn Section 1. Here is the prompt you can use:
Act as a Python teacher and explain the following subsections to me, using coding examples. Keep the tone conversational and suitable for a 9th grade level, and assume I am a complete beginner. After each subsection, ask if I have understood the concepts and if I have any questions
Section 1: Foundations of Web Scraping
- Introduction to Web Scraping
- Getting Started with Python and BeautifulSoup
- Understanding HTML and the DOM Structure”
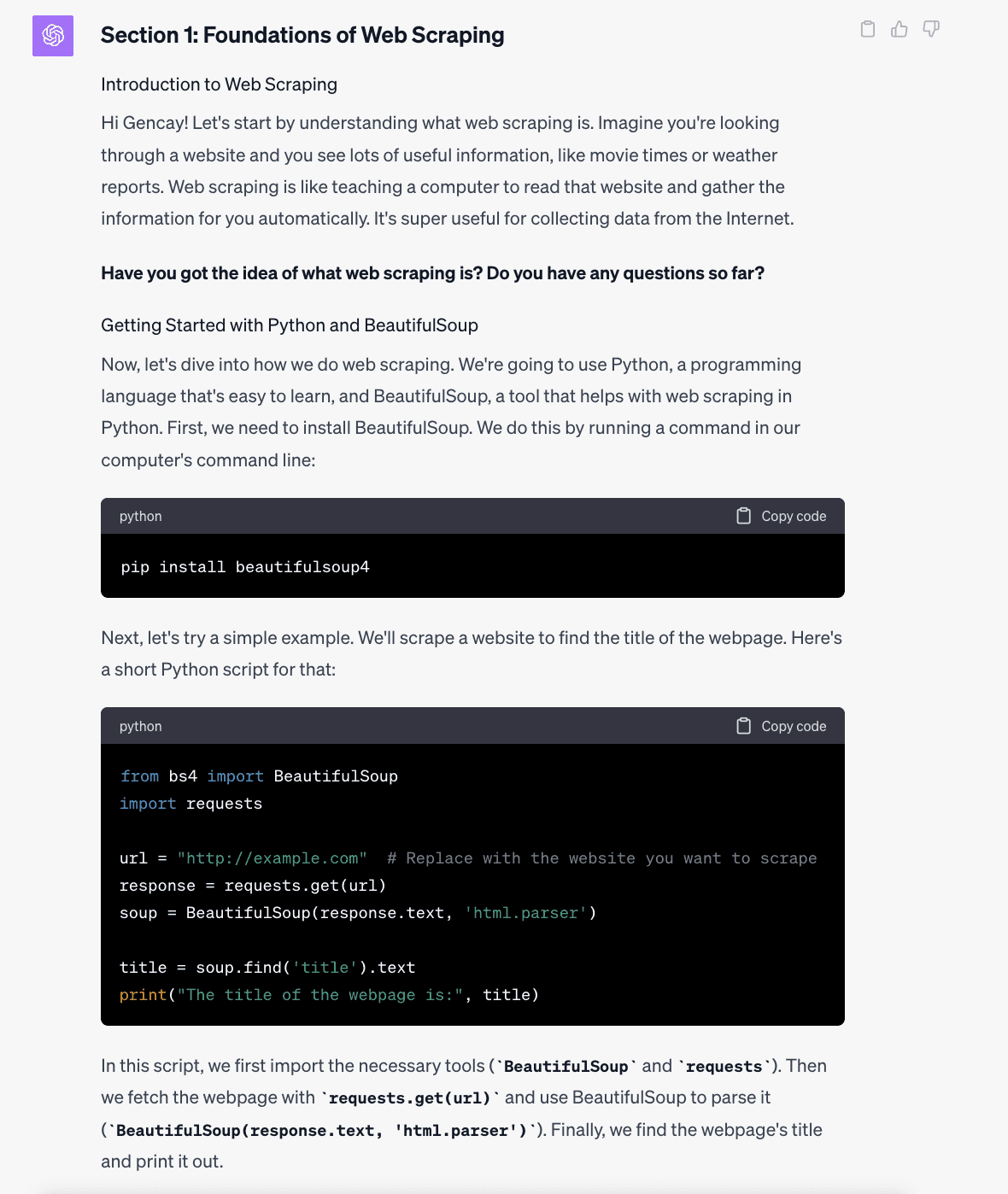
Here is the first section of the ChatGPT output. He explains concepts as if he were a beginner, provides coding examples, and asks questions to check your understanding, which is great. Let's look at the remaining part of his answer.
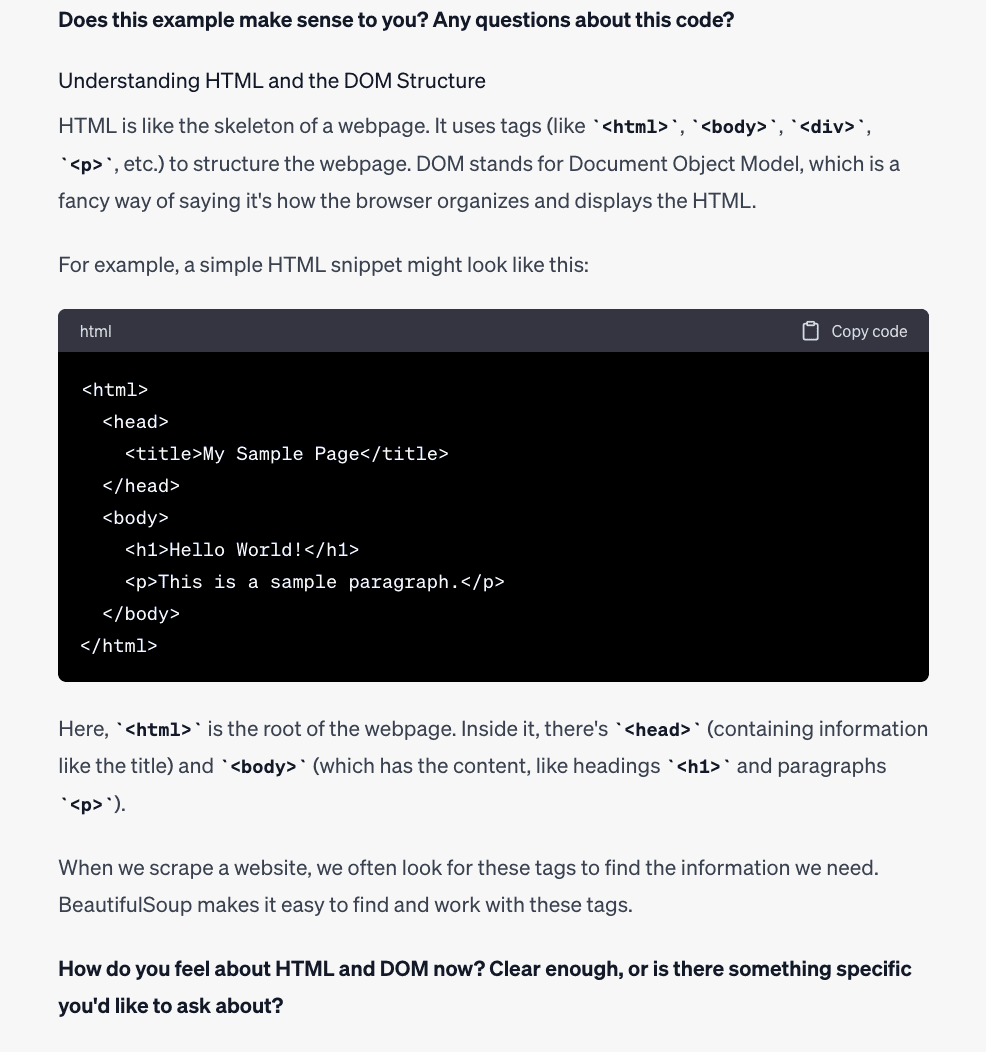
Great, now you understand it a little better. As you can see from this example, you have already provided valuable information about Web Scraping. But let's explore how it can help you with more advanced applications.
Important note: Please be aware of potential inaccuracies in ChatGPT responses. Always verify the information you provide afterwards.
As you can see from the examples above, once you have a solid plan, ChatGPT can be very useful for learning concepts, such as Web Scraping. In this section, we will explore more applications of ChatGPT, such as debugging or improving your code.
Debug your code
Sometimes debugging can be really difficult and time-consuming, and if you didn't write the code correctly, you might spend a lot of time on it, as shown in the code below.
In the code below, our goal is to extract quotes from the frequently used website, while learning Web Scraping with Python, let's see.
import requests
from bs4 import BeautifulSoup
def scrape_quotes():
page = 1
while True:
# This URL will not change with page number, causing the bug.
url = "https://quotes.toscrape.com/page/1/"
response = requests.get(url)
if response.ok:
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.find_all('span', class_='text')
if quotes:
for quote in quotes:
print(quote.text)
else:
# This condition will never be true since 'quotes' will not be empty.
print("No more quotes to scrape.")
break
# The page variable is incremented, but not used in the URL.
page += 1
else:
print(f"Failed to retrieve the webpage, status code: {response.status_code}")
break
scrape_quotes()
Can you spot the error in the code? If not, that's fine; I guess apart from experts there are very few people who can do that.
The bug was a classic case of a loop never reaching its end condition, so be careful before running it or be prepared to stop it manually.
This bug meant that even though our page variable increased, our script continued to request the same page, trapping us in an infinite loop.
Here, all you need to do is use the following message to debug your code.
And voila, it will debug your code snippet instantly and provide you with the latest version.
import requests
from bs4 import BeautifulSoup
def scrape_quotes():
page = 1
while True:
url = f"https://quotes.toscrape.com/page/{page}/" # Now the URL updates with the page number.
response = requests.get(url)
if response.ok:
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.find_all('span', class_='text')
if quotes:
for quote in quotes:
print(quote.text)
else:
print("No more quotes to scrape.")
break
page += 1 # Increment the page number.
else:
print(f"Failed to retrieve the webpage, status code: {response.status_code}")
break
scrape_quotes()The result will contain all the citations from the website.
Improve your code
Let's say you will pull quotes from the above website.
Here is the code.
import requests
from bs4 import BeautifulSoup
import time
def scrape_quotes_longer():
page = 1
all_quotes = ()
while True:
try:
response = requests.get(f"https://quotes.toscrape.com/page/{page}/", timeout=5)
if not response.ok:
break
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.find_all('span', class_='text')
for quote in quotes:
all_quotes.append(quote.text)
# Naive check for the 'next' button
next_btn = soup.select_one('li.next > a')
if not next_btn:
break
page += 1
time.sleep(2) # Sleep for 2 seconds between requests
except requests.RequestException as e:
print(f"Request failed: {e}")
break
return all_quotes
quotes = scrape_quotes_longer()
for q in quotes:
print(q)The result will be the same as we had before, all the quotes will be there, but let's say you are not happy with the code and want to improve it.
You can use the following message, it is simple but powerful.
Now let's look at the new code offered by ChatGPT.
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
from time import sleep
def scrape_quotes_improved():
page = 1
all_quotes = ()
headers = {'User-Agent': 'Mozilla/5.0'}
while True:
url = f"https://quotes.toscrape.com/page/{page}/"
try:
response = requests.get(url, headers=headers, timeout=5)
response.raise_for_status() # Will raise an HTTPError if the HTTP request returned an unsuccessful status code
soup = BeautifulSoup(response.text, 'html.parser')
quotes = (quote.text for quote in soup.find_all('span', class_='text'))
if not quotes:
break
all_quotes.extend(quotes)
next_btn = soup.select_one('li.next > a')
if not next_btn:
break # No more pages
page += 1
sleep(1) # More reasonable delay
except RequestException as e:
print(f"Request failed: {e}")
break
return all_quotes
quotes = scrape_quotes_improved()
for q in quotes:
print(q)
The result will be the same, but here are the improvements ChatGPT made.

As you can see it is really powerful.

Image created by the author using DE-E 3
Here, you can try to automate the entire web scraping process by downloading the HTML file of the web page you want to scrape and sending the HTML document to ChatGPT Advanced Data Analysis, adding the file to it.
Let's see with the example. Here is the IMDB websitewhich contains the top 100 rated movies, as rated by IMDB users, but at the bottom of this web page, don't forget to click 50 more to allow this web page, which will show all 100 together.
After that, let's download the html file by right clicking on the web page and then click save as and select the html file. Now that you have the file, open ChatGPT and select advanced data analysis.
Now it's time to add the HTML file you downloaded at the beginning. After adding the file, use the following message.
Save the top 100 IMDb movies, including the movie name, IMDb rating, Then, display the first five rows. Additionally, save this dataframe as a CSV file and send it to me.But here, if the structure of web pages is a little complicated, ChatGPT may not fully understand the structure of your website. Here I advise you to use its new function, sending photos. You can send the screenshot of the web page you want to collect information from.
To use this feature, right click on the web page and click inspect, here you can see the html elements.
Send the screenshot of this page to ChatGPT and request more information about the elements of this web page. Once you get the additional information ChatGPT needs, go back to your previous conversation and send that information to ChatGPT again. And voila!

We discovered Web Scraping through ChatGPT. Planning, debugging, and refining the code along with ai proved not only productive but also insightful. It is a dialogue with technology that leads us to new knowledge.
As you already know, data science like Web Scraping requires practice. It's like doing crafts. Code, fix, and code again: that's the mantra of budding data scientists looking to make their mark.
Ready for a hands-on experience? StrataScratch Platform It's your sand. Jump into data projects and solve interview questions, and join a community that will help you grow. I see you there!
Nate Rosidi He is a data scientist and in product strategy. He is also an adjunct professor of analysis and is the founder of StrataScratch, a platform that helps data scientists prepare for their interviews with real questions from top companies. Connect with him on Twitter: StrataScratch either LinkedIn.





{kind=link}