 NEWSLETTER
NEWSLETTER

Image by author
LSTMs were initially introduced in the early 1990s by authors Sepp Hochreiter and Jürgen Schmidhuber. The original model was extremely computationally expensive and it was in the mid-2010s that RNNs and LSTMs gained attention. With more data and better GPUs available, LSTM networks became the standard method for language modeling and became the backbone of the first large language model. This was until the launch of Attention-based transformer architecture in 2017. LSTMs were gradually overtaken by the Transformer architecture, which is now the standard for all recent large language models, including ChatGPT, Mistral, and Llama.
However, the recent publication of xLSTM paper by the original author of LSTM, Sepp Hochreiter, has caused quite a stir in the research community. The results show comparative pre-training results with the latest LLMs and have raised the question of whether LSTMs can once again take over natural language processing.
High-level architecture overview
The original LSTM network had some important limitations that limited its usability for larger contexts and deeper models. Namely:
- LSTMs were sequential models which made it difficult to parallelize training and inference.
- They had limited storage capabilities and all information had to be compressed into a single-cell state.
The recent xLSTM network introduces new sLSTM and mLSTM blocks to address both shortcomings. Let's take a general look at the architecture of the model and see the approach used by the authors.
Brief review of the original LSTM
The LSTM network used a hidden state and a cell state to counteract the vanishing gradient problem in basic RNN networks. They also added the forget, input, and output sigmoid gates to control the flow of information. The equations are the following:
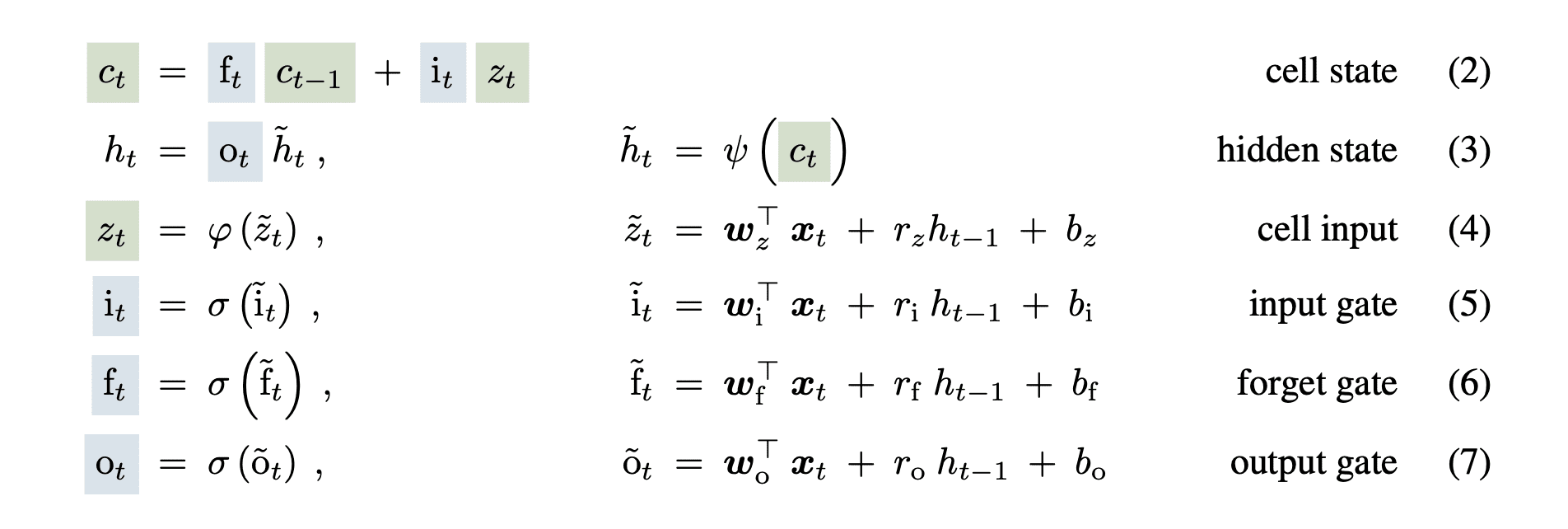
Picture of Paper
The cell state (ct) was passed through the cell LSTM with minor linear transformations that helped preserve the gradient over large input sequences.
The xLSTM model modifies these equations in the new blocks to remedy known limitations of the model.
sLSTM block
The block modifies the sigmoid gates and uses the exponential function for the enter and forget gate. As cited by the authors, this can improve storage issues in LSTM and still allow multiple memory cells to allow memory mixing within each head but not between heads. The modified sLSTM block equation is as follows:
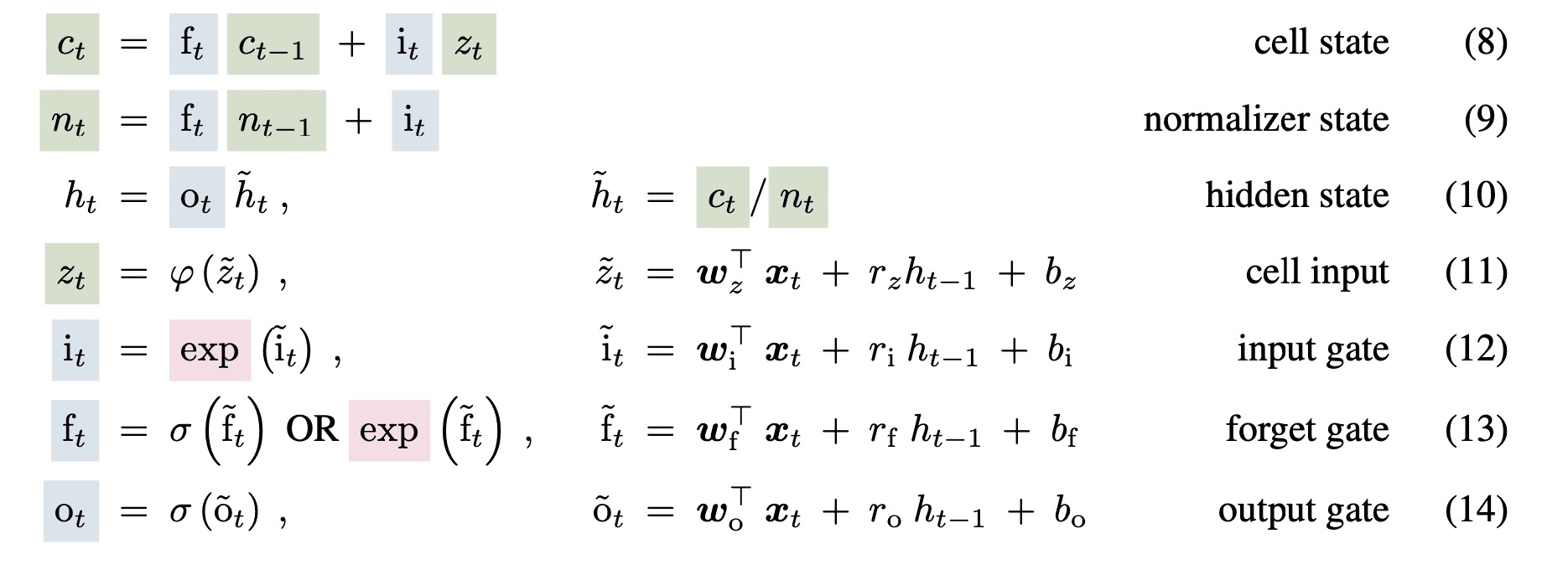
Picture of Paper
Furthermore, since the exponential function can generate large values, the gate values are normalized and stabilized by logarithmic functions.
mLSTM block
To counter parallelization and storage issues in the LSTM network, xLSTM modifies the cell state from a one-dimensional vector to a two-dimensional square matrix. They store a decomposed version as key-value vectors and use the same exponential gate as the sLSTM block. The equations are the following:
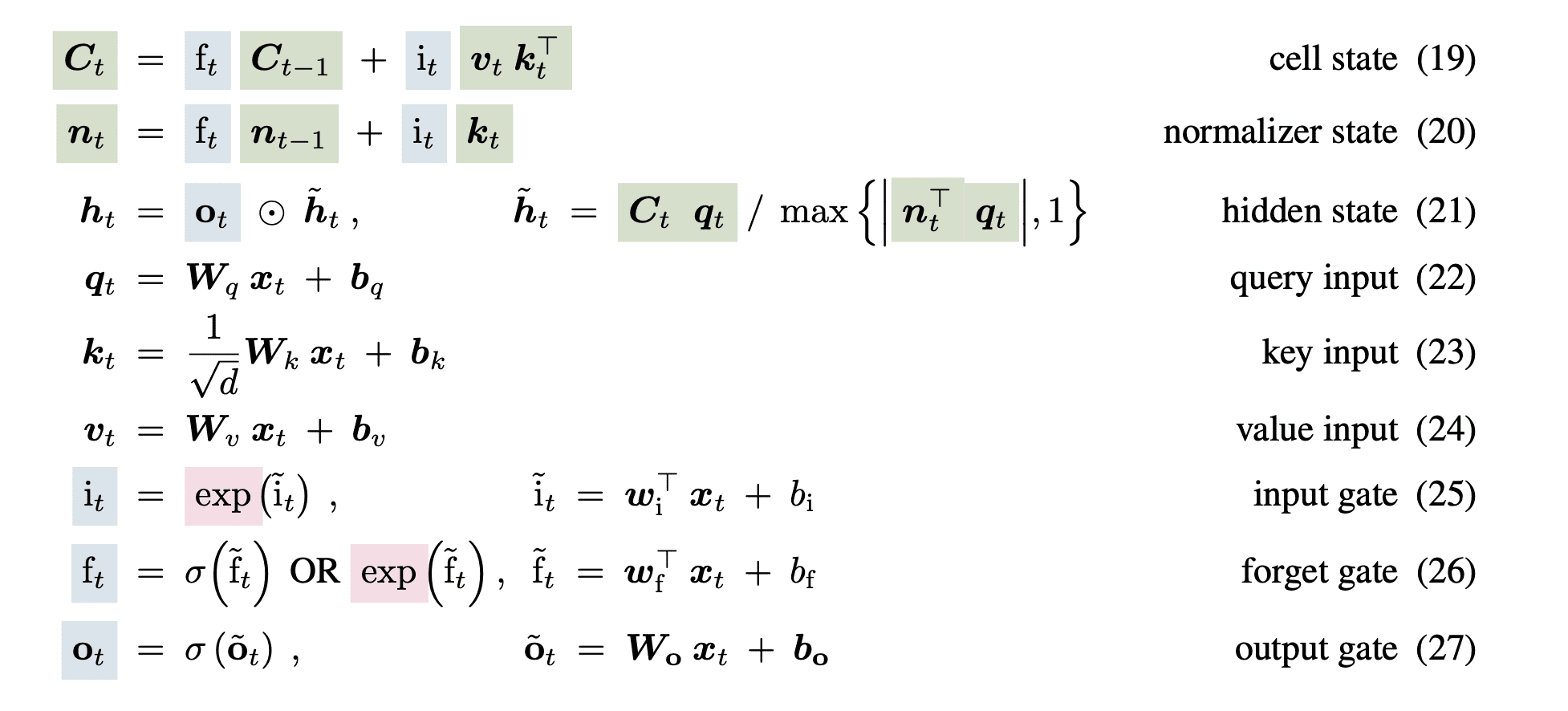
Picture of Paper
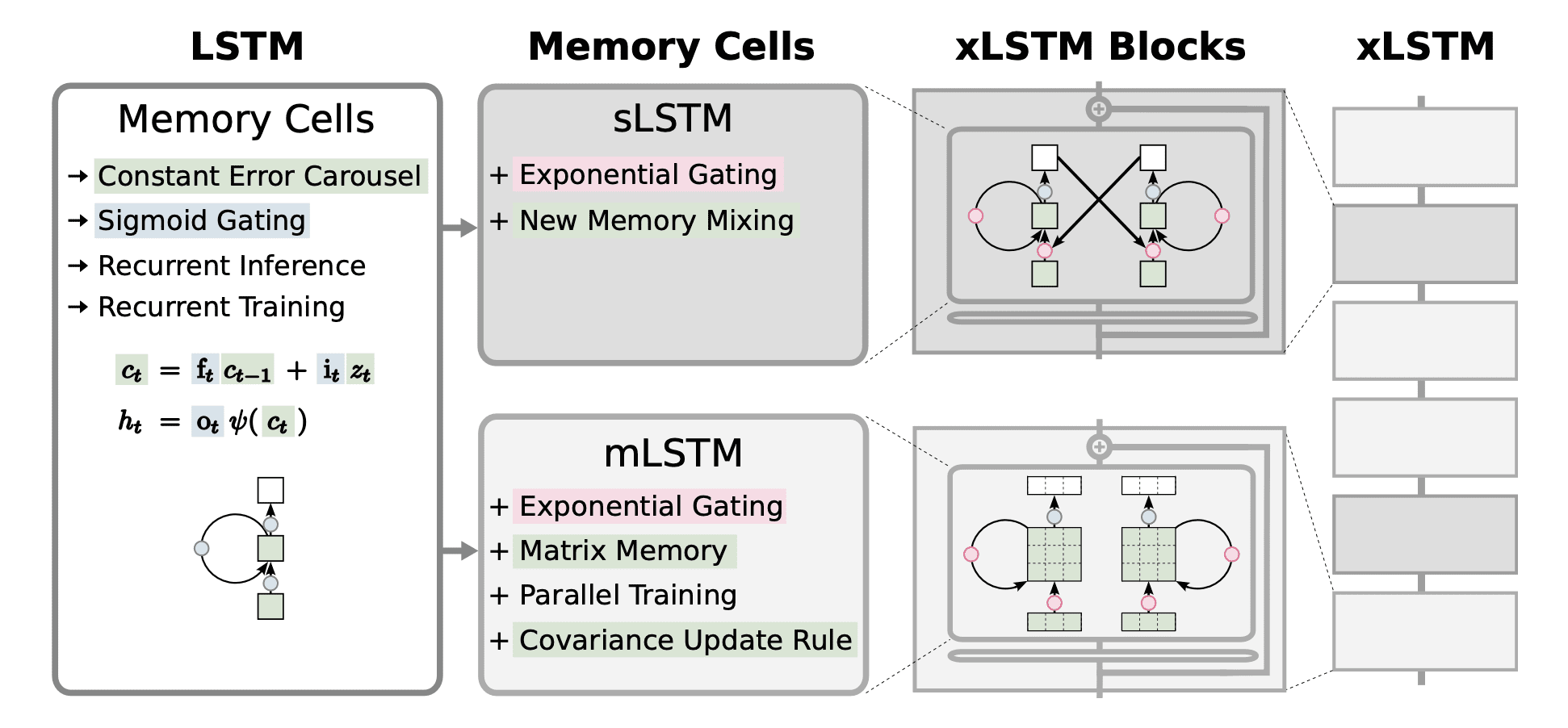
Architecture diagram
Picture of Paper
The general xLSTM architecture is a sequential combination of mLSTM and sLSTM blocks in different proportions. As the diagram shows, the xLSTM block can have any memory cell. The different blocks are stacked together with layer normalizations to form a deep network of residual blocks.
Evaluation and comparison results
The authors train the xLSTM network on language model tasks and compare perplexity (lower is better) of the model trained with current Transformer-based LLMs.
The authors first train the models with 15 billion SlimPajama tokens. The results showed that xLSTM outperforms all other models in the validation set with the lowest perplexity score.
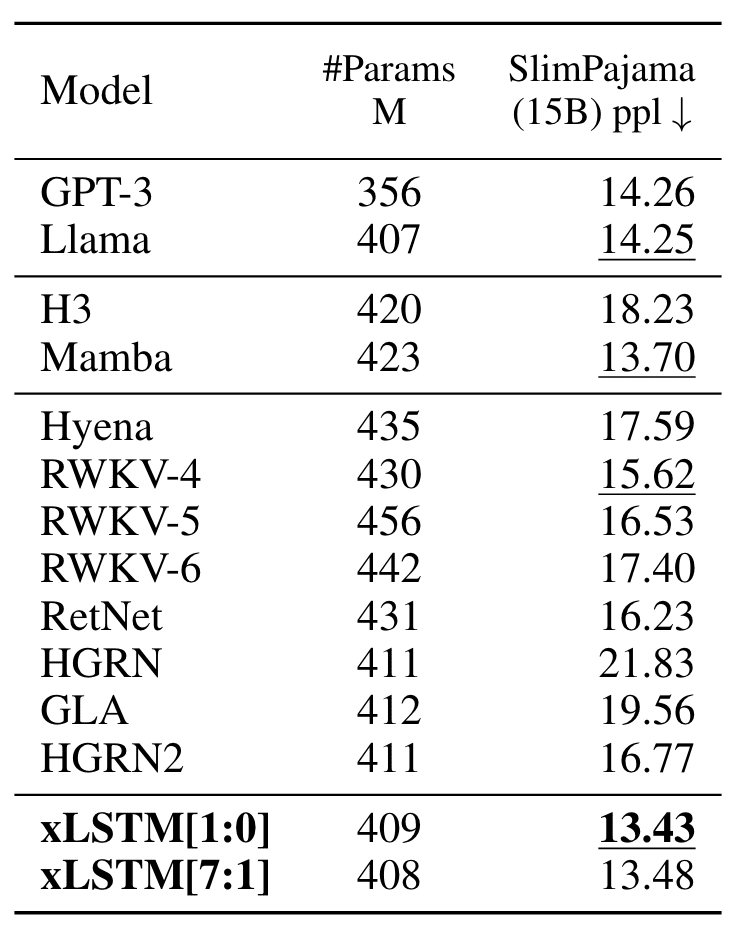
Picture of Paper
Sequence length extrapolation
The authors also analyze performance when the duration of the test time sequence exceeds the duration of the context on which the model was trained. They trained all models with a sequence length of 2048 and the following graph shows the perplexity of the validation with changes in token position:
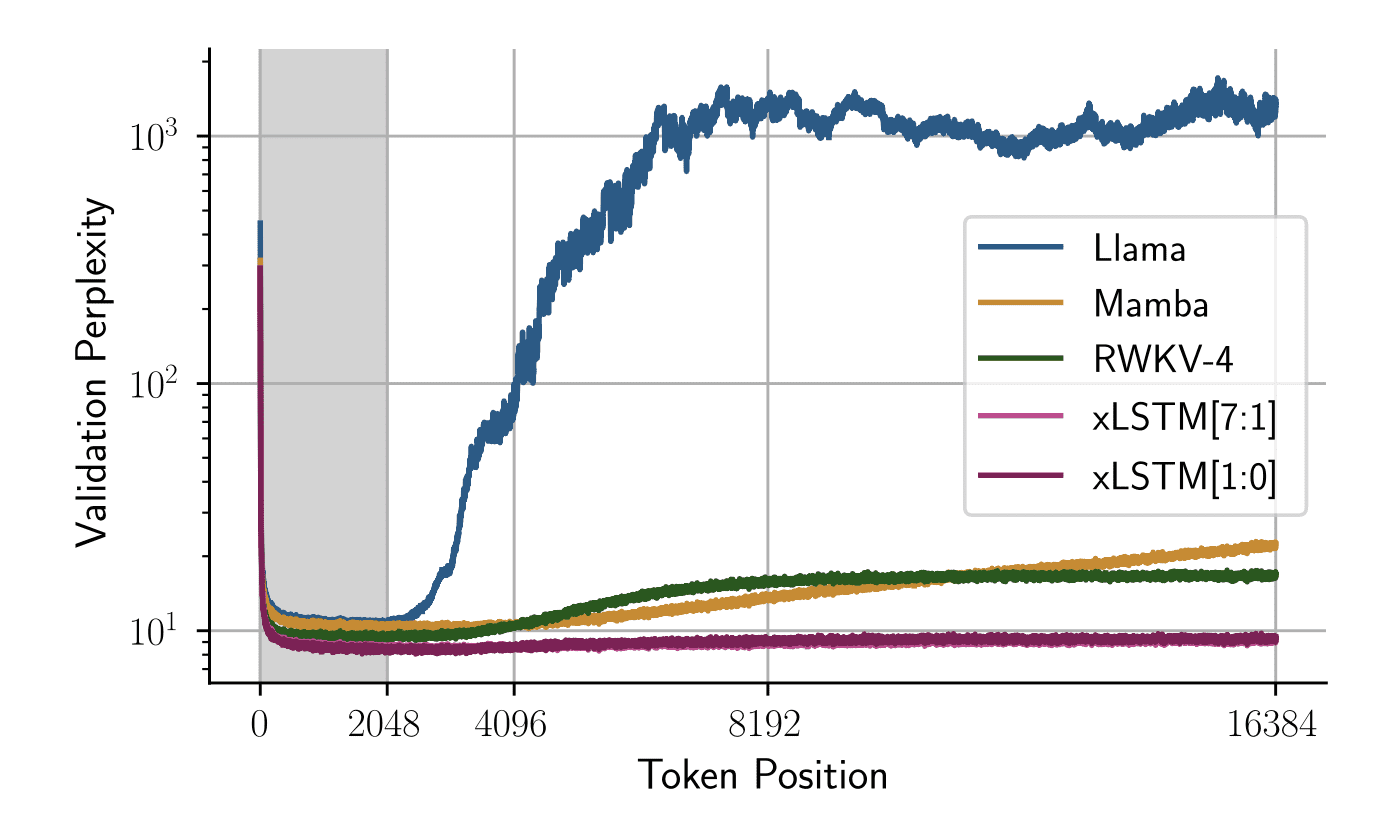
Picture of Paper
The graph shows that even for much longer sequences, xLSTM networks maintain a stable perplexity score and perform better than any other model for much longer context lengths.
Scaling xLSMT to larger model sizes
The authors further train the model with 300 billion tokens from the SlimPajama dataset. The results show that even for larger models, xLSTM scales better than the current Transformer and Mamba architecture.
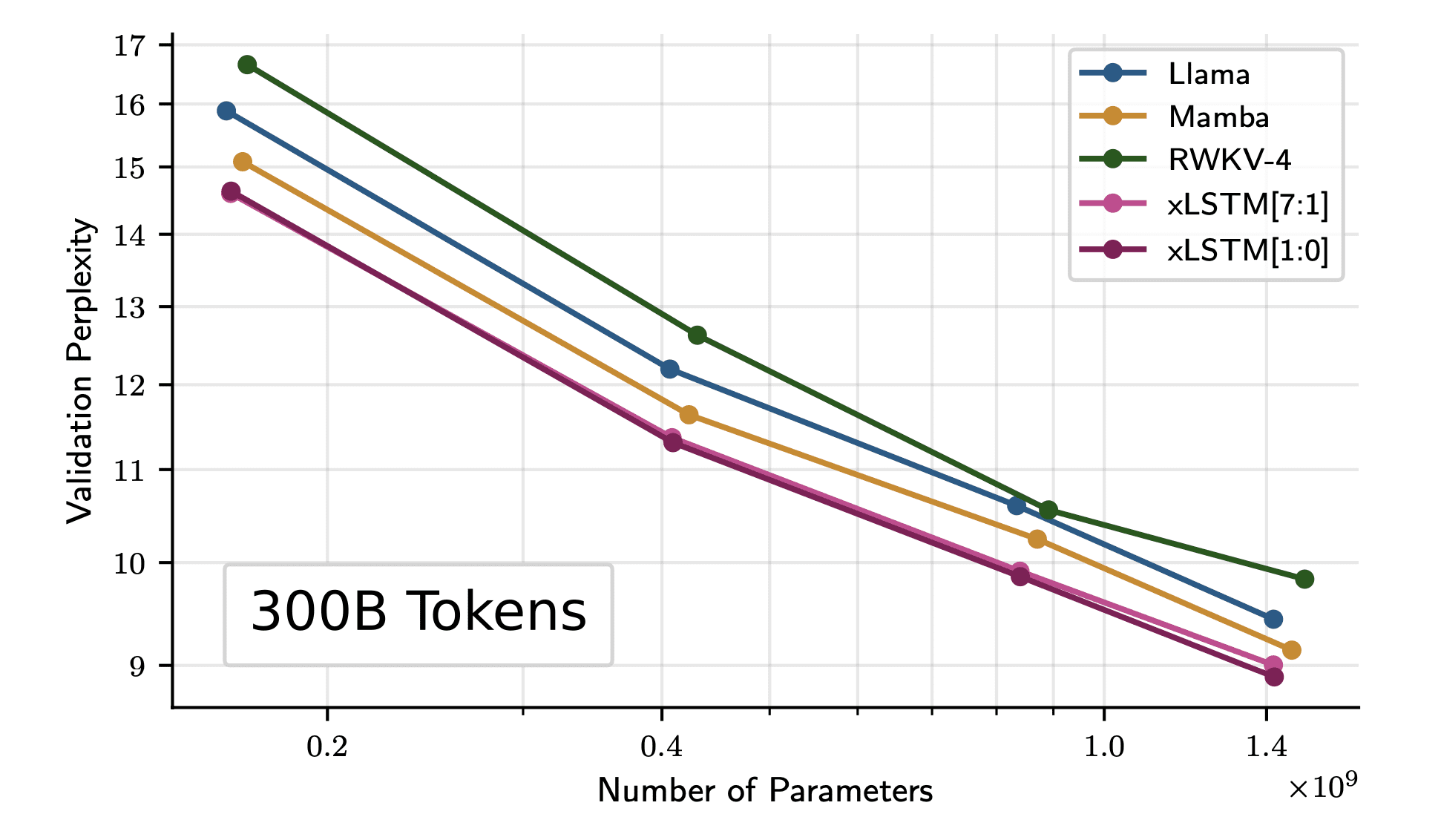
Picture of Paper
Ending
That might have been hard to understand and that's okay! However, you should now understand why this research work has received all the attention recently. It has been shown to perform at least as well as recent large language models, if not better. It has been proven to be scalable for larger models and can be a serious competitor to all the recent LLMs created with Transformers. Only time will tell if LSTMs will regain their glory once again, but for now we know that the xLSTM architecture is here to challenge the superiority of the renowned Transformers architecture.
Kanwal Mehreen Kanwal is a machine learning engineer and technical writer with a deep passion for data science and the intersection of ai with medicine. She is the co-author of the eBook “Maximize Productivity with ChatGPT.” As a Google Generation Scholar 2022 for APAC, she champions diversity and academic excellence. She is also recognized as a Teradata Diversity in tech Scholar, Mitacs Globalink Research Scholar, and Harvard WeCode Scholar. Kanwal is a passionate advocate for change and founded FEMCodes to empower women in STEM fields.






{kind=link}