 NEWSLETTER
NEWSLETTER
Esta publicación está coescrita con Matt Marzillo de Snowflake.
Hoy, nos complace anunciar que el modelo Snowflake Arctic Instruct está disponible a través de amazon SageMaker JumpStart para implementar y ejecutar inferencias. Copo de nieve del Ártico es una familia de modelos de lenguaje grandes (LLM) de nivel empresarial creados por Copo de nieve para satisfacer las necesidades de los usuarios empresariales, exhibiendo capacidades excepcionales (como se muestra en la siguiente imagen). puntos de referencia) en consultas SQL, codificación y seguimiento preciso de instrucciones. SageMaker JumpStart es un centro de aprendizaje automático (ML) que brinda acceso a algoritmos, modelos y soluciones de ML para que pueda comenzar rápidamente con ML.
En esta publicación, explicamos cómo descubrir e implementar el modelo Snowflake Arctic Instruct usando SageMaker JumpStart y brindamos casos de uso de ejemplo con indicaciones específicas.
¿Qué es Snowflake Arctic?
Copo de nieve del Ártico es un LLM enfocado en la empresa que ofrece inteligencia empresarial de primer nivel entre los LLM abiertos con una relación costo-beneficio altamente competitiva. Snowflake puede lograr una alta inteligencia empresarial a través de una densa combinación de expertos (MoE). arquitectura de transformador híbrido y técnicas de entrenamiento eficientes. Con la arquitectura de transformador híbrido, Artic está diseñado con un modelo de transformador denso de 10 mil millones combinado con un MLP residual de 128 × 3,66 B MoE que da como resultado un total de 480 mil millones de parámetros distribuidos entre 128 expertos de grano fino y utiliza una selección de top-2 para elegir 17 mil millones de parámetros activos. Esto permite que Snowflake Arctic tenga una mayor capacidad para la inteligencia empresarial debido a la gran cantidad de parámetros totales y, al mismo tiempo, sea más eficiente en términos de recursos para el entrenamiento y la inferencia al utilizar la cantidad moderada de parámetros activos.
Snowflake Arctic se capacita con un plan de estudios de datos de tres etapas con diferente composición de datos que se centra en habilidades genéricas en la primera fase (1 billón de tokens, la mayoría de datos web) y habilidades centradas en la empresa en las dos fases siguientes (1,5 billones y 1 billón de tokens, respectivamente, con más datos de código, SQL y STEM). Esto ayuda al modelo Snowflake Arctic a establecer una nueva base de inteligencia empresarial y, al mismo tiempo, a ser rentable.
Además de la capacitación rentable, Snowflake Arctic también viene con una serie de innovaciones y optimizaciones para ejecutar la inferencia de manera eficiente. En tamaños de lotes pequeños, la inferencia está limitada por el ancho de banda de la memoria, y Snowflake Arctic puede tener hasta cuatro veces menos lecturas de memoria en comparación con otros modelos disponibles abiertamente, lo que genera un rendimiento de inferencia más rápido. En tamaños de lotes muy grandes, la inferencia pasa a estar limitada por el cálculo y Snowflake Arctic incurre en hasta cuatro veces menos cálculo en comparación con otros modelos disponibles abiertamente. Los modelos de Snowflake Arctic están disponibles bajo una licencia Apache 2.0, que proporciona acceso sin restricciones a los pesos y al código. Todas las recetas de datos y los conocimientos de investigación también estarán disponibles para los clientes.
¿Qué es SageMaker JumpStart?
Con SageMaker JumpStart, puede elegir entre una amplia selección de modelos de base (FM) disponibles públicamente. Los profesionales de ML pueden implementar FM en instancias dedicadas de amazon SageMaker desde un entorno aislado de la red y personalizar modelos utilizando SageMaker para el entrenamiento y la implementación de modelos. Ahora puede descubrir e implementar el modelo Arctic Instruct con unos pocos clics en amazon SageMaker Studio o programáticamente a través del SDK de Python de SageMaker, lo que le permite derivar controles de operaciones de aprendizaje automático (MLOps) y rendimiento del modelo con características de SageMaker como amazon SageMaker Pipelines, amazon SageMaker Debugger o registros de contenedores. El modelo se implementa en un entorno seguro de AWS y bajo los controles de su nube privada virtual (VPC), lo que ayuda a brindar seguridad a los datos. El modelo Arctic Instruct de Snowflake está disponible hoy para implementación e inferencia en SageMaker Studio en el us-east-2 Región de AWS, con disponibilidad futura planificada en regiones adicionales.
Descubre modelos
Puede acceder a los modelos de modelo a través de SageMaker JumpStart en la interfaz de usuario de SageMaker Studio y el SDK de Python de SageMaker. En esta sección, repasaremos cómo descubrir los modelos en SageMaker Studio.
SageMaker Studio es un entorno de desarrollo integrado (IDE) que proporciona una única interfaz visual basada en la Web en la que puede acceder a herramientas diseñadas específicamente para realizar todos los pasos de desarrollo de ML, desde la preparación de datos hasta la creación, el entrenamiento y la implementación de sus modelos de ML. Para obtener más detalles sobre cómo comenzar y configurar SageMaker Studio, consulte amazon SageMaker Studio.
En SageMaker Studio, puede acceder a SageMaker JumpStart, que contiene modelos entrenados previamente, cuadernos y soluciones prediseñadas, en Soluciones preconstruidas y automatizadas.
Desde la página de inicio de SageMaker JumpStart, puede descubrir varios modelos explorando diferentes centros, que reciben el nombre de proveedores de modelos. Puede encontrar el modelo Snowflake Arctic Instruct en el centro Hugging Face. Si no ve el modelo Arctic Instruct, actualice su versión de SageMaker Studio apagándolo y reiniciándolo. Para obtener más información, consulte Apagado y actualización de aplicaciones de Studio Classic.
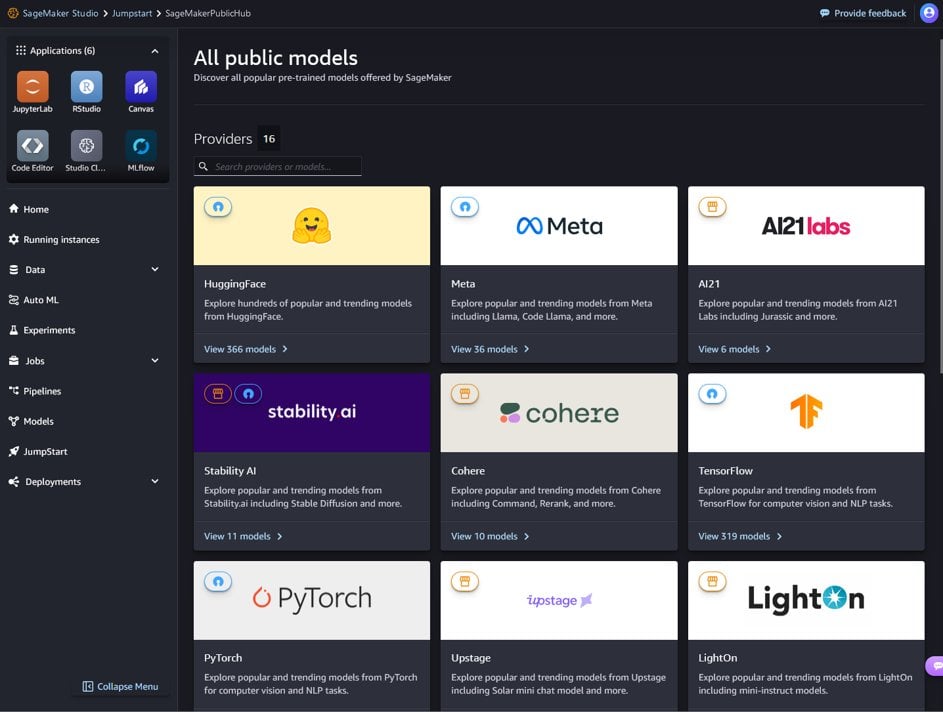
También puedes encontrar el modelo Snowflake Arctic Instruct buscando “Snowflake” en el campo de búsqueda.
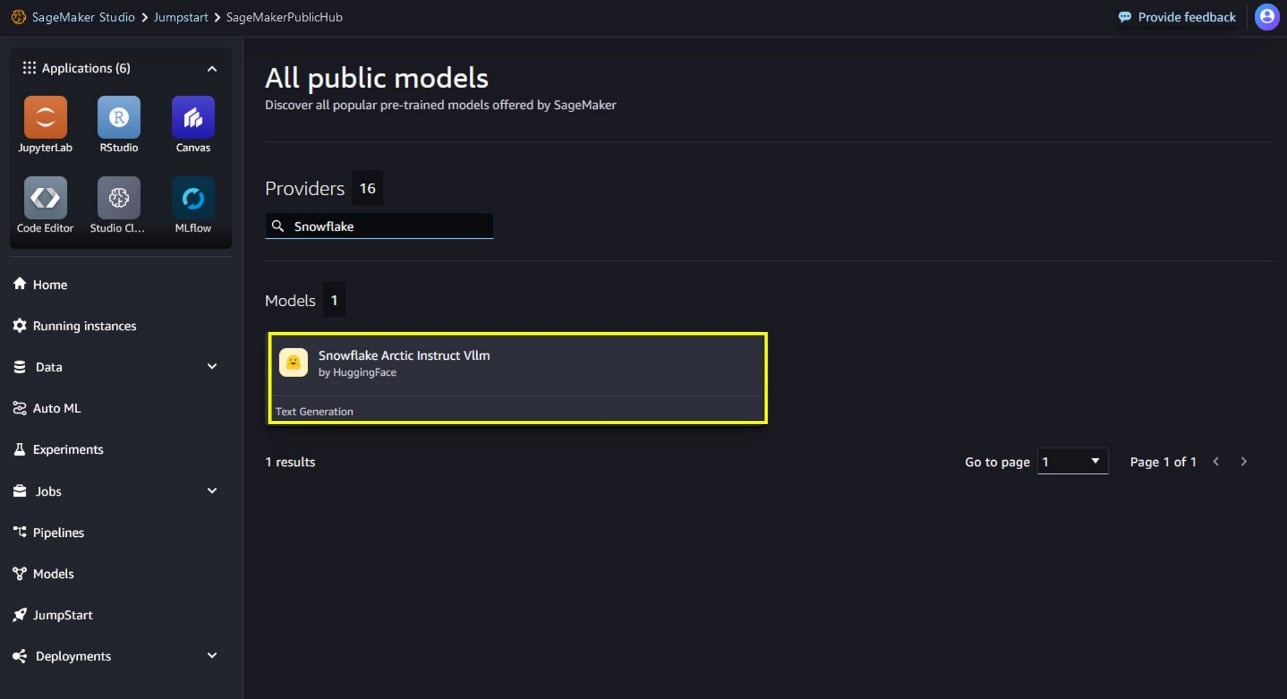
Puede elegir la tarjeta del modelo para ver detalles sobre el modelo, como la licencia, los datos utilizados para entrenar y cómo utilizar el modelo. También encontrará dos opciones para implementar el modelo: los cuadernos Implementar y Vista previa, que implementarán el modelo y crearán un punto final.
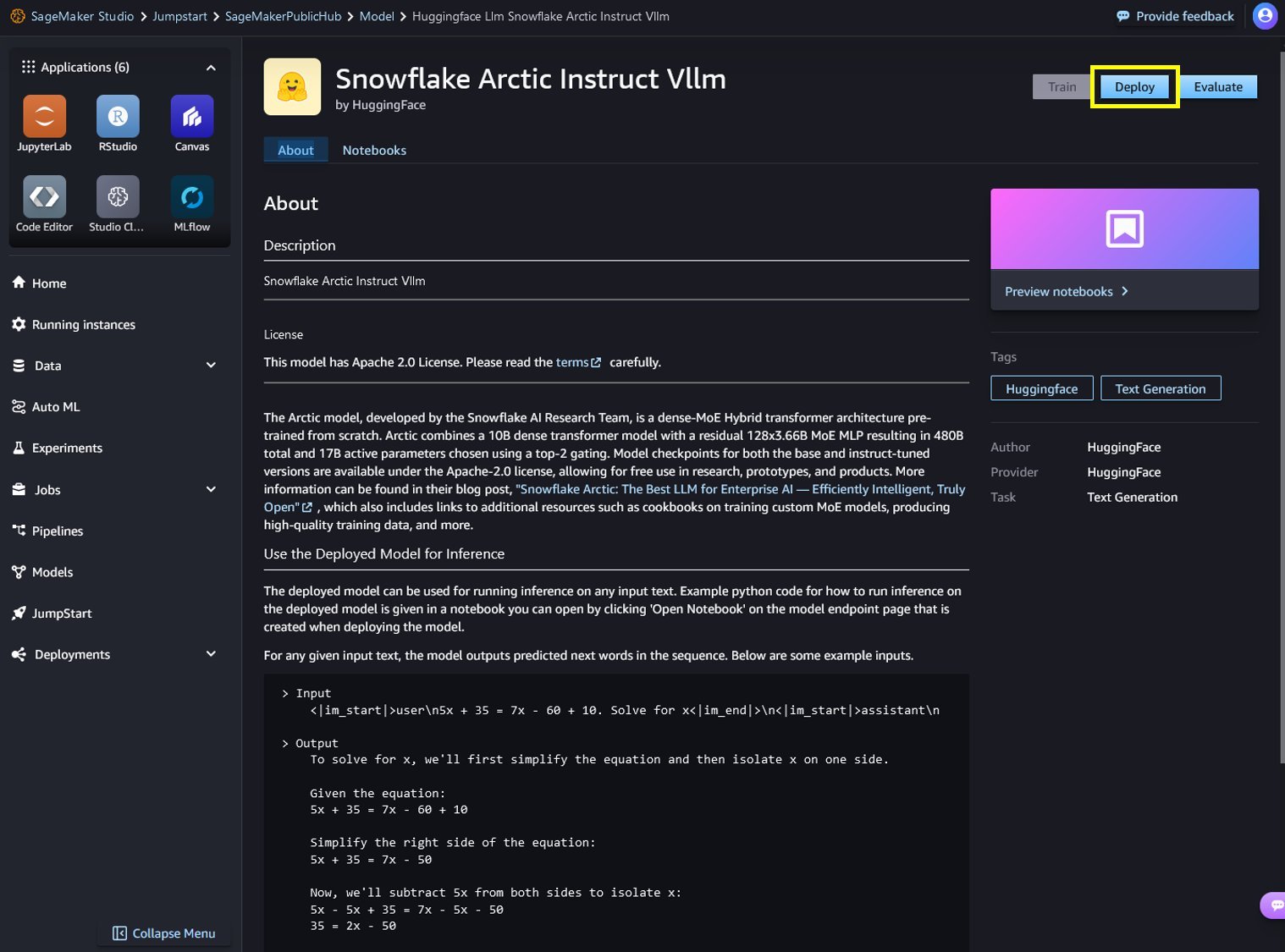
Implementar el modelo en SageMaker Studio
Cuando elija Implementar en SageMaker Studio, comenzará la implementación.
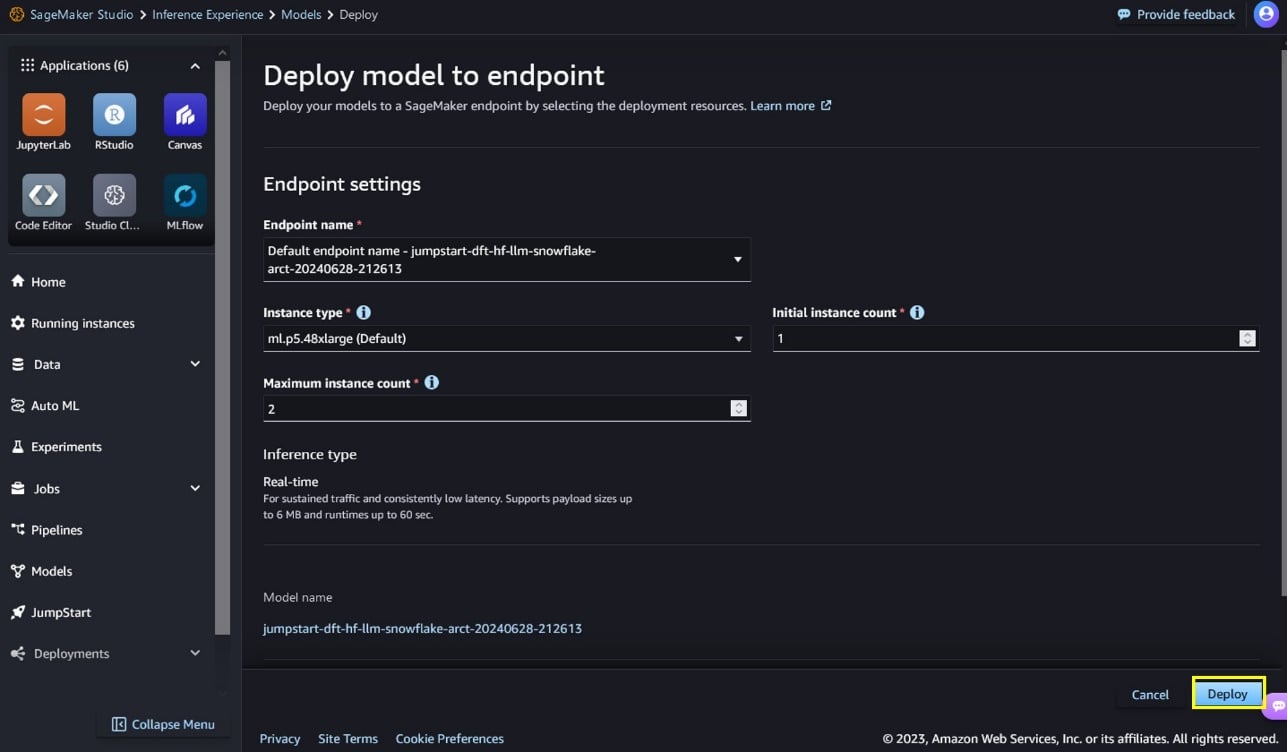
Puede supervisar el progreso de la implementación en la página de detalles del punto final a la que será redirigido.
Implementar el modelo a través de un notebook
Como alternativa, puede elegir Abrir cuaderno para implementar el modelo a través del cuaderno de ejemplo. El cuaderno de ejemplo proporciona una guía completa sobre cómo implementar el modelo para la inferencia y la limpieza de recursos.
Para implementar mediante el cuaderno, comience seleccionando un modelo adecuado, especificado por model_id. Puede implementar cualquiera de los modelos seleccionados en SageMaker con el siguiente código:
Esto implementa el modelo en SageMaker con configuraciones predeterminadas, incluido el tipo de instancia predeterminado y las configuraciones de VPC predeterminadas. Puede cambiar estas configuraciones especificando valores no predeterminados en JumpStartModel. Para obtener más información, consulte Documentación de la API.
Ejecutar inferencia
Después de implementar el modelo, puede ejecutar inferencias contra el punto final implementado a través de API de predicción de SageMakerSnowflake Arctic Instruct acepta el historial de chats entre el usuario y el asistente y genera chats posteriores.
predictor.predict(payload)
Los parámetros de inferencia controlan el proceso de generación de texto en el punto final. El parámetro de máximo de tokens nuevos controla el tamaño de la salida generada por el modelo. Puede que no sea el mismo que la cantidad de palabras porque el vocabulario del modelo no es el mismo que el vocabulario del idioma inglés. El parámetro de temperatura controla la aleatoriedad de la salida. Una temperatura más alta da como resultado salidas más creativas y alucinógenas. Todos los parámetros de inferencia son opcionales.
El modelo acepta instrucciones formateadas en las que los roles de conversación deben comenzar con una indicación del usuario y alternar entre las instrucciones del usuario y el asistente. El formato de la instrucción debe respetarse estrictamente, de lo contrario, el modelo generará resultados subóptimos. La plantilla para crear una indicación para el modelo se define de la siguiente manera:
<|im_start|>system{system_message} <|im_end|><|im_start|>user{human_message} <|im_end|><|im_start|>assistant\n
<|im_start|> y <|im_end|> son tokens especiales para el comienzo de la cadena (BOS) y el final de la cadena (EOS). El modelo puede contener múltiples turnos de conversación entre el sistema, el usuario y el asistente, lo que permite la incorporación de ejemplos de pocos intentos para mejorar las respuestas del modelo.
El siguiente código muestra cómo puedes formatear el mensaje en formato de instrucción:
<|im_start|>user\n5x + 35 = 7x -60 + 10. Solve for x<|im_end|>\n<|im_start|>assistant\n
En las siguientes secciones proporcionamos ejemplos de indicaciones para diferentes casos de uso centrados en la empresa.
Resumen de texto largo
Puede utilizar Snowflake Arctic Instruct para tareas personalizadas, como resumir texto extenso en una salida con formato JSON. A través de la generación de texto, puede realizar una variedad de tareas, como resumen de texto, traducción de idiomas, generación de código, análisis de sentimientos y más. La carga útil de entrada al punto final se parece al siguiente código:
A continuación se muestra un ejemplo de un mensaje y el texto generado por el modelo. Todos los resultados se generan con parámetros de inferencia. {"max_new_tokens":512, "top_p":0.95, "temperature":0.7, "top_k":50}.
La entrada es la siguiente:
Obtenemos el siguiente resultado:
Generación de código
Usando el ejemplo anterior, podemos utilizar indicaciones de generación de código de la siguiente manera:
El código anterior utiliza Snowflake Arctic Instruct para generar una función Python que escribe un archivo JSON. Define un diccionario de carga útil con el mensaje de entrada “Escribir una función en Python para escribir un archivo JSON:” y algunos parámetros para controlar el proceso de generación, como la cantidad máxima de tokens para generar y si se habilita el muestreo. Envía esta carga útil a un predictor (probablemente una API), recibe la respuesta de texto generada y la imprime en la consola. La salida impresa debe ser la función Python para escribir un archivo JSON, como se solicita en el mensaje.
El siguiente es el resultado:
Esto creará un archivo llamado `output.json` en el mismo directorio que su script de Python y escribirá el diccionario `data` en ese archivo en formato JSON.
El resultado de la generación de código define el write_json que toma el nombre del archivo y un objeto Python y escribe el objeto como datos JSON. El resultado muestra el contenido del archivo JSON esperado, lo que ilustra las capacidades de generación de código y procesamiento de lenguaje natural del modelo.
Matemáticas y razonamiento
Snowflake Arctic Instruct también informa sobre la solidez del razonamiento matemático. Utilicemos el siguiente mensaje para probarlo:
El siguiente es el resultado:
El código anterior muestra la capacidad de Snowflake Arctic para comprender indicaciones en lenguaje natural que involucran razonamiento matemático, dividirlas en pasos lógicos y generar explicaciones y soluciones similares a las humanas.
Generación de SQL
El modelo Arctic Instruct de Snowflake también es capaz de generar consultas SQL basadas en indicaciones de lenguaje natural y en su entrenamiento inteligente empresarial. Ponemos a prueba esa capacidad con la siguiente indicación:
El siguiente es el resultado:
El resultado muestra que Snowflake Arctic Instruct infirió los campos específicos de interés en las tablas y proporcionó una consulta ligeramente más compleja que implica unir dos tablas para obtener el resultado deseado.
Limpiar
Una vez que hayas terminado de ejecutar el cuaderno, elimina todos los recursos que hayas creado en el proceso para detener la facturación. Usa el siguiente código:
Al implementar el punto final desde la consola de SageMaker Studio, puede eliminarlo eligiendo Eliminar en la página de detalles del punto final.
Conclusión
En esta publicación, le mostramos cómo comenzar a usar el modelo Snowflake Arctic Instruct en SageMaker Studio y le proporcionamos ejemplos de indicaciones para múltiples casos de uso empresariales. Debido a que los FM están entrenados previamente, también pueden ayudar a reducir los costos de capacitación e infraestructura y permitir la personalización para su caso de uso. Consulte SageMaker JumpStart en SageMaker Studio ahora para comenzar. Para obtener más información, consulte los siguientes recursos:
Acerca de los autores
Natarajan Chennimalai Kumar – Arquitecto de soluciones principal, proveedores de modelos 3P, AWS
Pavan Kumar Rao Navule – Arquitecto de soluciones, AWS
Nidhi Gupta – Arquitecta de soluciones para socios sénior, AWS
Bosco Albuquerque – Arquitecto de soluciones para socios sénior, AWS
Matt Marzillo – Ingeniero asociado sénior, Snowflake
Nithin Vijeaswaran – Arquitecto de soluciones, AWS
Armando Diaz – Arquitecto de Soluciones, AWS
Supriya Puragundla – Arquitecta de soluciones sénior, AWS
Jin Tan Ruan – Desarrollador de prototipos, AWS






{kind=link}