 NEWSLETTER
NEWSLETTER

Imagen del editor
En el panorama tecnológico en constante evolución, el papel de los científicos y analistas de datos se ha vuelto crucial para que todas las organizaciones encuentren conocimientos basados en datos para la toma de decisiones. Kaggle, una plataforma que reúne a científicos de datos e ingenieros entusiastas del aprendizaje automático, se convierte en una plataforma central para mejorar las habilidades de ciencia de datos y aprendizaje automático. A medida que nos acercamos al año 2024, la demanda de científicos de datos competentes continúa aumentando significativamente, lo que lo convierte en un momento oportuno para acelerar su viaje en este campo dinámico.
Entonces, en este artículo, conocerá los 10 principales proyectos de aprendizaje automático de Kaggle para abordar en 2024, que pueden ayudarlo a adquirir experiencia práctica en la resolución de problemas de ciencia de datos. Al implementar estos proyectos, obtendrá una experiencia de aprendizaje integral que cubrirá varios aspectos de la ciencia de datos, desde el preprocesamiento de datos y el análisis exploratorio de datos hasta el desarrollo avanzado de modelos de aprendizaje automático.
Exploremos juntos el apasionante mundo de la ciencia de datos y elevemos sus habilidades a nuevas alturas en 2024.
Idea: En este proyecto, debe implementar un modelo de aprendizaje profundo que ayude a reconocer y clasificar la raza de un perro en función de las imágenes de entrada proporcionadas por el usuario en el entorno de prueba. Al explorar esta tarea clásica de clasificación de imágenes, aprenderá sobre una de las arquitecturas famosas del aprendizaje profundo, es decir, las redes neuronales convolucionales (CNN), y su aplicación a problemas del mundo real.
Conjunto de datos: Dado que es un problema supervisado, el conjunto de datos consistiría en imágenes etiquetadas de varias razas de perros. Una de las opciones más populares para implementar esta tarea es el “Stanford Dogs Dataset”, disponible gratuitamente en Kaggle.

Imagen de Medio
Tecnologías: Según su experiencia, se pueden utilizar bibliotecas y marcos de Python como TensorFlow o PyTorch para implementar esta tarea de clasificación de imágenes.
Implementación: En primer lugar, hay que preprocesar las imágenes, diseñar una arquitectura CNN con diferentes capas involucradas, entrenar el modelo y evaluar su rendimiento utilizando métricas de evaluación como la precisión y la matriz de confusión.
Idea: En este proyecto, aprenderá los aspectos prácticos de la implementación de un modelo de aprendizaje automático utilizando Gradio. Esta biblioteca fácil de usar facilita la implementación del modelo casi sin requisitos de código. Este proyecto hace hincapié en hacer que los modelos de aprendizaje automático sean accesibles a través de una interfaz sencilla y se utilicen en un entorno de producción en tiempo real.
Conjunto de datos: Según el planteamiento del problema, que abarca desde la clasificación de imágenes hasta las tareas de procesamiento del lenguaje natural, puede elegir el conjunto de datos respectivo y, en consecuencia, la selección del algoritmo se puede realizar manteniendo diferentes factores, como la latencia para la predicción y la precisión, etc., y luego implementarlo.
Tecnologías: Gradio para su implementación, junto con las bibliotecas necesarias para el desarrollo de modelos (por ejemplo, TensorFlow, PyTorch).
Implementación: En primer lugar, entrene un modelo, luego guarde los pesos, que son los parámetros que se pueden aprender y que ayudan a realizar la predicción, y finalmente intégrelos con Gradio para crear una interfaz de usuario simple e implementar el modelo para predicciones interactivas.
Idea: En este proyecto, debes desarrollar un modelo de aprendizaje automático que ayude a encontrar la diferencia entre artículos de noticias reales y falsos recopilados de diferentes aplicaciones de redes sociales utilizando técnicas de procesamiento de lenguaje natural. Este proyecto implica preprocesamiento de texto, extracción de características y clasificación.
Conjunto de datos: Utilice conjuntos de datos que contengan artículos de noticias etiquetados, como el “Conjunto de datos de noticias falsas” en Kaggle.

Imagen de Kaggle
Tecnologías: Bibliotecas de procesamiento de lenguaje natural como NLTK o spaCy y algoritmos de aprendizaje automático como Naive Bayes o modelos de aprendizaje profundo.
Implementación: Tokenizará y limpiará datos de texto, extraerá características relevantes, entrenará un modelo de clasificación y evaluará su rendimiento utilizando métricas como precisión, recuperación y puntuación F1.
Idea: En este proyecto, debe crear un sistema de recomendación que sugiera automáticamente películas o series web a los usuarios en función de sus visualizaciones anteriores a través de las plataformas correlacionadas. Los sistemas de recomendación como Netflix y Amazon Prime se utilizan ampliamente en la transmisión de medios para mejorar la experiencia del usuario.
Conjunto de datos: Los conjuntos de datos de uso común incluyen MovieLens o IMDb, que contienen calificaciones de usuarios e información de películas.
Tecnologías: Algoritmos de filtrado colaborativo, factorización matricial y marcos de sistemas de recomendación como Surprise o LightFM.
Implementación: Explorará las interacciones usuario-elemento, creará un algoritmo de recomendación, evaluará su rendimiento utilizando métricas como el error absoluto medio y ajustará el modelo para obtener mejores predicciones.
Idea: En este proyecto, debe crear un modelo de aprendizaje automático para segmentar a los clientes en función de su comportamiento de compra anterior, de modo que cuando el mismo cliente vuelva, ese sistema pueda recomendar cosas pasadas para aumentar las ventas. De esta manera, al utilizar la segmentación, las organizaciones pueden dirigir el marketing y los servicios personalizados a todos los clientes.
Conjunto de datos: Dado que se trata de un tipo de problema de aprendizaje no supervisado, no se necesitarán etiquetas para dichas tareas y puede utilizar conjuntos de datos que contengan datos de transacciones de clientes, conjuntos de datos de venta minorista en línea o cualquier conjunto de datos relacionados con el comercio electrónico, como los de Amazon, Flipkart, etc. ,
Tecnologías: Diferentes algoritmos de agrupamiento de la clase de algoritmos de aprendizaje automático no supervisados, como K-means o agrupamiento jerárquico (ya sea divisivo o aglomerativo), para segmentar clientes en función de su comportamiento.
Implementación: En primer lugar, debe procesar los datos de la transacción, incluida la visualización de los datos, y luego aplicar diferentes algoritmos de agrupación, visualizar segmentos de clientes en función de otros grupos formados por el modelo, analizar las características de cada segmento para obtener información de marketing y luego evaluarlo utilizando diferentes métricas. como puntuación de silueta, etc.
Idea: El comportamiento de las acciones es un poco aleatorio, pero al utilizar el aprendizaje automático, se pueden predecir los precios aproximados de las acciones utilizando datos financieros históricos capturando la variación en los datos. Este proyecto implica análisis y pronóstico de series de tiempo para modelar la dinámica de diferentes precios de acciones entre múltiples sectores como banca, automóvil, etc.
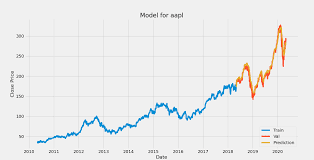
Imagen de Publicación de desarrollo
Conjunto de datos: Necesita los precios históricos de las acciones, que incluyen apertura, máximo, mínimo, cierre, volumen, etc., en diferentes períodos de tiempo, incluidos precios diarios o minuto a minuto y cantidades negociadas.
Tecnologías: Puede utilizar diferentes técnicas para analizar los modelos de series de tiempo, como la función de autocorrelación y los modelos de pronóstico, incluidas las redes de media móvil integrada autorregresiva (ARIMA), la memoria a corto plazo (LSTM), etc.
Implementación: En primer lugar, debe procesar los datos de la serie temporal, incluida su descomposición, como cíclica, estacional, aleatoria, etc., luego elegir un modelo de pronóstico adecuado para entrenar el modelo y, finalmente, evaluar su rendimiento utilizando métricas como el error cuadrático medio y la media absoluta. Error o error cuadrático medio.
Idea: En este proyecto hay que desarrollar un modelo que pueda reconocer diferentes tipos de emociones en lenguajes hablados, como enfado, alegría, locura, etc., lo que implica el procesamiento de los datos de audio capturados de varias personas y la aplicación de técnicas de aprendizaje automático para Clasificación de emociones.
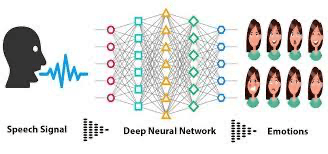
Imagen de Kaggle
Conjunto de datos: Utilice conjuntos de datos con clips de audio etiquetados, como el conjunto de datos “RAVDESS” que contiene grabaciones de discursos emocionales.
Tecnologías: Técnicas de procesamiento de señales para modelos de aprendizaje profundo de extracción de características para análisis de audio.
Implementación: Extraerá características de datos de audio, diseñará una red neuronal para el reconocimiento de emociones, entrenará el modelo y evaluará su rendimiento utilizando métricas como precisión y matriz de confusión.
Idea: En este proyecto, debe crear un sistema para predecir ventas futuras basándose en datos históricos de ventas. Este proyecto es esencial para que las empresas optimicen el inventario y planifiquen la demanda futura.
Conjunto de datos: Datos históricos de ventas de productos o servicios, incluida información sobre el volumen de ventas, el tiempo y factores relevantes.
Tecnologías: Métodos de pronóstico de series temporales, modelos de regresión y marcos de aprendizaje automático.
Implementación: En primer lugar, preprocesará los datos de ventas, elegirá un modelo de pronóstico o regresión adecuado, entrenará el modelo y evaluará su rendimiento utilizando métricas como el error cuadrático medio o R cuadrado.
Idea: En este proyecto, debe crear un modelo para clasificar dígitos escritos a mano utilizando el conjunto de datos MNIST. Este proyecto es una introducción fundamental a la clasificación de imágenes y, a menudo, se considera un punto de partida para quienes son nuevos en el aprendizaje profundo.
Conjunto de datos: El conjunto de datos MNIST consta de imágenes en escala de grises de dígitos escritos a mano (0-9).

Imagen de Puerta de la investigación
Tecnologías: Redes neuronales convolucionales (CNN) que utilizan frameworks como TensorFlow o PyTorch.
Implementación: En primer lugar, debe preprocesar los datos de la imagen, diseñar una arquitectura CNN, entrenar el modelo y evaluar su rendimiento utilizando métricas como la precisión y la matriz de confusión.
Idea: En este proyecto, debe desarrollar un modelo de aprendizaje automático para detectar transacciones fraudulentas con tarjetas de crédito, lo cual es crucial para que las instituciones financieras mejoren la seguridad, protejan a los usuarios de actividades fraudulentas y faciliten el entorno para diferentes transacciones.
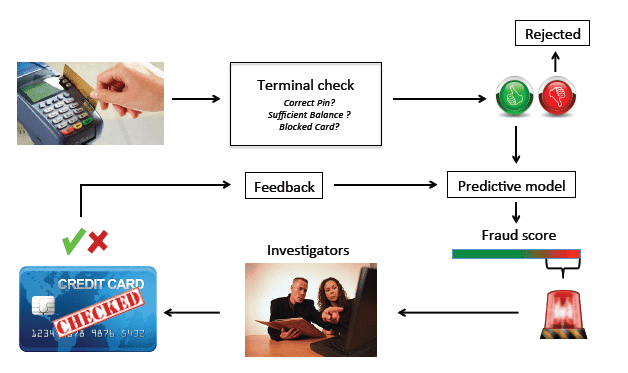
Imagen de Puerta de la investigación
Conjunto de datos: Dado que es un problema de aprendizaje supervisado, debe recopilar el conjunto de datos, que contiene conjuntos de datos de transacciones de tarjetas de crédito con casos etiquetados de transacciones fraudulentas y no fraudulentas.
Tecnologías: Algoritmos de detección de anomalías, modelos de clasificación como Random Forest o Support Vector Machines y marcos de aprendizaje automático para su implementación.
Implementación: En primer lugar, debe preprocesar los datos de la transacción, entrenar un modelo de detección de fraude, ajustar los parámetros para un rendimiento óptimo y evaluar el modelo utilizando métricas de evaluación de clasificación como precisión, recuperación y ROC-AUC.
En conclusión, explorar los 10 principales proyectos de aprendizaje automático de Kaggle ha sido fantástico. Desde desentrañar los misterios de las razas caninas y desplegar modelos de aprendizaje automático con Gradio hasta combatir las noticias falsas y predecir los precios de las acciones, cada proyecto ha ofrecido una característica única en el campo diversificado de la ciencia de datos. Estos proyectos ayudan a obtener conocimientos invaluables para resolver desafíos del mundo real.
Recuerde, convertirse en científico de datos en 2024 no se trata solo de dominar algoritmos o marcos, sino de diseñar soluciones a problemas complejos, comprender diversos conjuntos de datos y adaptarse constantemente al panorama tecnológico en evolución. Continúe explorando, mantenga la curiosidad y deje que los conocimientos de estos proyectos lo guíen para realizar contribuciones impactantes al mundo de la ciencia de datos. ¡Salud por su viaje continuo en el campo dinámico y en constante expansión de la ciencia de datos!
Garg ario es un B.tech. Estudiante de Ingeniería Eléctrica, actualmente en el último año de la carrera. Su interés radica en el campo del Desarrollo Web y el Aprendizaje Automático. Él ha perseguido este interés y está ansioso por trabajar más en estas direcciones.






{kind=link}