 NEWSLETTER
NEWSLETTER
You will have heard the famous quote “Data is the new oil” by British mathematician Clive Humby. It is the most influential quote that describes the importance of data in the 21st century but, after the explosive development of the large language model and its training, what I have no right to is data. Because the development speed and training speed of the LLM model almost exceed the data generation speed of humans. The solution is to make the data more refined and specific to the task or synthetic data generation. The former are the tasks most burdened by domain experts, but the latter are more prominent given the enormous hunger of current problems.
High-quality training data remains a critical bottleneck. This blog post explores a practical approach to generating synthetic data using LLama 3.2 and Ollama. It will demonstrate how we can create structured educational content programmatically.
Learning outcomes
- Understand the importance and techniques of local generation of synthetic data to improve machine learning model training.
- Learn how to implement local synthetic data generation to create high-quality data sets while preserving privacy and security.
- Gain practical knowledge of implementing robust error and retry handling mechanisms in data generation pipelines.
- Learn JSON validation, cleanup techniques, and their role in maintaining consistent and reliable results.
- Develop experience in designing and using Pydantic models to ensure data schema integrity.
What is synthetic data?
Synthetic data refers to artificially generated information that mimics the characteristics of real-world data while preserving essential statistical properties and patterns. It is created using algorithms, simulations, or artificial intelligence models to address privacy concerns, augment limited data, or test systems in controlled scenarios. Unlike real data, synthetic data can be tailored to specific requirements, ensuring diversity, balance, and scalability. It is widely used in fields such as machine learning, healthcare, finance, and autonomous systems to train models, validate algorithms, or simulate environments. Synthetic data bridges the gap between data scarcity and real-world applications, while reducing ethical and compliance risks.
Why do we need synthetic data today?
The demand for synthetic data has grown exponentially due to several factors
- Data privacy regulations: With GDPR and similar regulations, synthetic data offers a safe alternative for development and testing.
- Profitability: Collecting and annotating real data is expensive and time-consuming.
- Scalability: Synthetic data can be generated in large quantities with controlled variations
- Edge Case Coverage: We can generate data for rare scenarios that might be difficult to collect naturally.
- Rapid prototyping: Fast iteration on ML models without waiting for real data to be collected.
- Less biased: Data collected from the real world can be error-prone and full of gender bias, racist text, and not safe for children's words, so to make a model with this type of data, the behavior of the model is also inherently with these biases. With synthetic data, we can easily monitor these behaviors.
Impact on LLM and Small LM performance
Synthetic data has shown promising results in improving large and small language models.
- Fine tuning efficiency: Models fine-tuned on high-quality synthetic data often show comparable performance to those trained on real data.
- Domain adaptation: Synthetic data helps close domain gaps in specialized applications
- Data Augmentation: Combining synthetic and real data often produces better results if either is used separately.
Project structure and environment configuration
In the next section, we will break down the project design and guide you in setting up the required environment.
project/
├── main.py
├── requirements.txt
├── README.md
└── english_QA_new.jsonNow we will configure our project environment using conda. Follow the steps below
Create Conda environment
$conda create -n synthetic-data python=3.11
# activate the newly created env
$conda activate synthetic-dataInstall libraries in conda env
pip install pydantic langchain langchain-community
pip install langchain-ollamaNow we are all set to begin the code deployment.
Project implementation
In this section we will delve into the practical implementation of the project, covering each step in detail.
Library Import
Before starting the project, we will create a file name main.py in the root of the project and import all the libraries in that file:
from pydantic import BaseModel, Field, ValidationError
from langchain.prompts import PromptTemplate
from langchain_ollama import OllamaLLM
from typing import List
import json
import uuid
import re
from pathlib import Path
from time import sleepNow it is time to continue with the implementation part of the code in the main.py file.
First, we start by implementing the data schema.
The question data schema is a Pydantic model that ensures our generated data follows a consistent structure with required fields and automatic ID generation.
Code implementation
class EnglishQuestion(BaseModel):
id: str = Field(
default_factory=lambda: str(uuid.uuid4()),
description="Unique identifier for the question",
)
category: str = Field(..., description="Question Type")
question: str = Field(..., description="The English language question")
answer: str = Field(..., description="The correct answer to the question")
thought_process: str = Field(
..., description="Explanation of the reasoning process to arrive at the answer"
)Now that we have created the EnglishQuestion data class.
Secondly, we will start implementing the QuestionGenerator class. This class is the core of the project implementation.
Question Generator Class Structure
class QuestionGenerator:
def __init__(self, model_name: str, output_file: Path):
pass
def clean_json_string(self, text: str) -> str:
pass
def parse_response(self, result: str) -> EnglishQuestion:
pass
def generate_with_retries(self, category: str, retries: int = 3) -> EnglishQuestion:
pass
def generate_questions(
self, categories: List(str), iterations: int
) -> List(EnglishQuestion):
pass
def save_to_json(self, question: EnglishQuestion):
pass
def load_existing_data(self) -> List(dict):
passLet's implement the key methods step by step.
Initialization
Initialize the class with a language model, a request template, and an output file. With this, we will create an instance of OllamaLLM with model_name and configure a PromptTemplate to generate QA in a strict JSON format.
Code implementation:
def __init__(self, model_name: str, output_file: Path):
self.llm = OllamaLLM(model=model_name)
self.prompt_template = PromptTemplate(
input_variables=("category"),
template="""
Generate an English language question that tests understanding and usage.
Focus on {category}.Question will be like fill in the blanks,One liner and mut not be MCQ type. write Output in this strict JSON format:
{{
"question": "",
"answer": "",
"thought_process": ""
}}
Do not include any text outside of the JSON object.
""",
)
self.output_file = output_file
self.output_file.touch(exist_ok=True)JSON Cleanup
The responses we will get from the LLM during the generation process will have many unnecessary extra characters that can alter the generated data, so you must put this data through a cleaning process.
Here, we will fix the common formatting issue in JSON keys/values using regular expressions, replacing problematic characters like newline and special characters.
Code implementation:
def clean_json_string(self, text: str) -> str:
"""Improved version to handle malformed or incomplete JSON."""
start = text.find("{")
end = text.rfind("}")
if start == -1 or end == -1:
raise ValueError(f"No JSON object found. Response was: {text}")
json_str = text(start : end + 1)
# Remove any special characters that might break JSON parsing
json_str = json_str.replace("\n", " ").replace("\r", " ")
json_str = re.sub(r"(^\x20-\x7E)", "", json_str)
# Fix common JSON formatting issues
json_str = re.sub(
r'(?Response analysis
The parsing method will use the above cleansing process to clean the LLM responses, validate the consistency of the response, convert the clean JSON to a Python dictionary, and map the dictionary to an EnglishQuestion object.
Code implementation:
def parse_response(self, result: str) -> EnglishQuestion:
"""Parse the LLM response and validate it against the schema."""
cleaned_json = self.clean_json_string(result)
parsed_result = json.loads(cleaned_json)
return EnglishQuestion(**parsed_result)Data persistence
For persistent data generation, although we can use some NoSQL databases (MongoDB, etc.) for this, here we use a simple JSON file to store the generated data.
Code implementation:
def load_existing_data(self) -> List(dict):
"""Load existing questions from the JSON file."""
try:
with open(self.output_file, "r") as f:
return json.load(f)
except (FileNotFoundError, json.JSONDecodeError):
return ()Robust generation
In this phase of data generation, we have two most important methods:
- Build with retry mechanism
- Question generation method
The purpose of the retry mechanism is to force the automation to generate a response in the event of a failure. Attempting to generate a question multiple times (default is three times) will log errors and add a delay between retries. It will also raise an exception if all attempts fail.
Code implementation:
def generate_with_retries(self, category: str, retries: int = 3) -> EnglishQuestion:
for attempt in range(retries):
try:
result = self.prompt_template | self.llm
response = result.invoke(input={"category": category})
return self.parse_response(response)
except Exception as e:
print(
f"Attempt {attempt + 1}/{retries} failed for category '{category}': {e}"
)
sleep(2) # Small delay before retry
raise ValueError(
f"Failed to process category '{category}' after {retries} attempts."
)The question generation method will generate multiple questions for a list of categories and save them to storage (here, JSON file). It will iterate over the categories and call the generate_with_retries method for each category. And lastly, it will save each successfully generated question using the save_to_json method.
def generate_questions(
self, categories: List(str), iterations: int
) -> List(EnglishQuestion):
"""Generate multiple questions for a list of categories."""
all_questions = ()
for _ in range(iterations):
for category in categories:
try:
question = self.generate_with_retries(category)
self.save_to_json(question)
all_questions.append(question)
print(f"Successfully generated question for category: {category}")
except (ValidationError, ValueError) as e:
print(f"Error processing category '{category}': {e}")
return all_questionsShow results in terminal
To get an idea of what responses LLM produces, here is a simple print function.
def display_questions(questions: List(EnglishQuestion)):
print("\nGenerated English Questions:")
for question in questions:
print("\n---")
print(f"ID: {question.id}")
print(f"Question: {question.question}")
print(f"Answer: {question.answer}")
print(f"Thought Process: {question.thought_process}")Testing automation
Before running your project, create an english_QA_new.json file in the project root.
if __name__ == "__main__":
OUTPUT_FILE = Path("english_QA_new.json")
generator = QuestionGenerator(model_name="llama3.2", output_file=OUTPUT_FILE)
categories = (
"word usage",
"Phrasal Ver",
"vocabulary",
"idioms",
)
iterations = 2
generated_questions = generator.generate_questions(categories, iterations)
display_questions(generated_questions)
Now, go to the terminal and type:
python main.pyProduction:

These questions will be saved in the root of your project. The saved question looks like this:
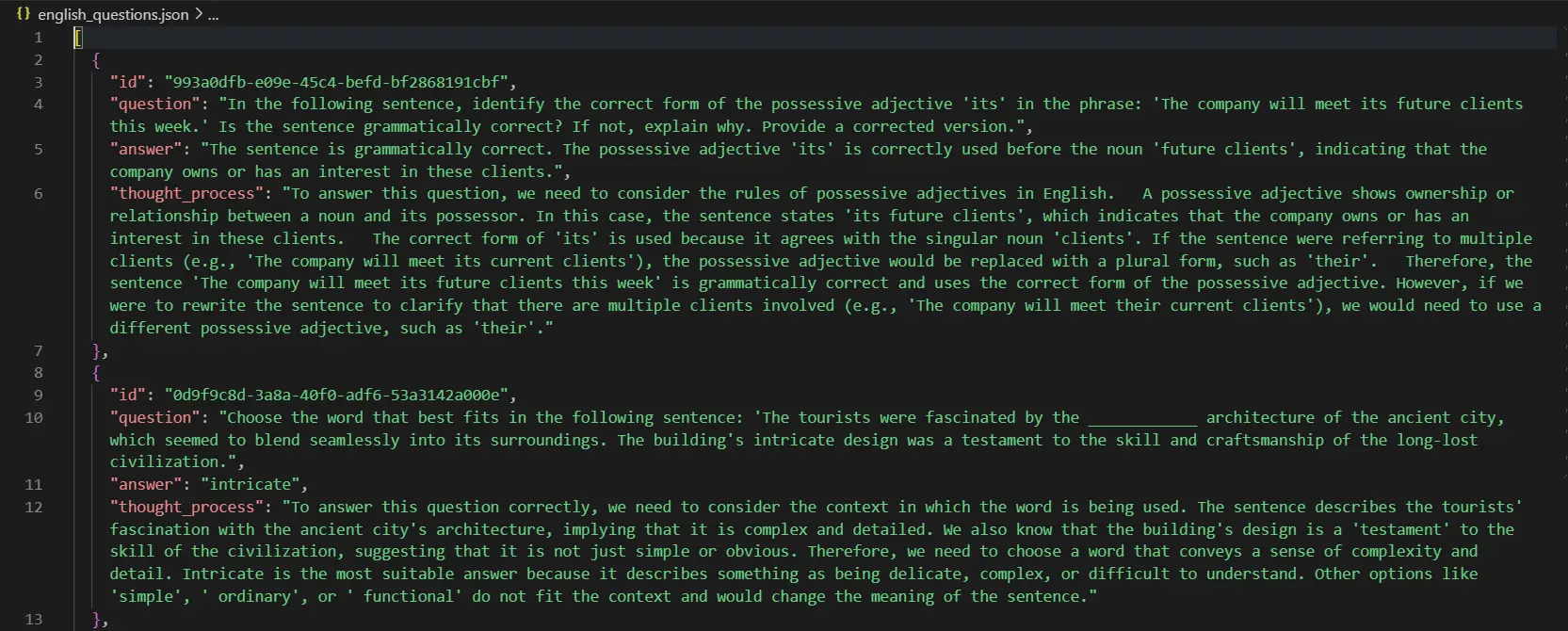
All code used in this project is here.
Conclusion
Synthetic data generation has emerged as a powerful solution to address the growing demand for high-quality training datasets in the era of rapid advancements in ai and LLM. By leveraging tools like LLama 3.2 and Ollama, along with robust frameworks like Pydantic, we can create structured, scalable, and bias-free datasets tailored to specific needs. This approach not only reduces reliance on costly and time-consuming real-world data collection, but also ensures privacy and ethical compliance. As we refine these methodologies, synthetic data will continue to play a critical role in driving innovation, improving model performance, and unlocking new possibilities in diverse fields.
Key takeaways
- Local generation of synthetic data enables the creation of diverse data sets that can improve model accuracy without compromising privacy.
- Implementing local synthetic data generation can significantly improve data security by minimizing reliance on sensitive real-world data.
- Synthetic data ensures privacy, reduces bias, and reduces data collection costs.
- Customized data sets improve adaptability in various ai and LLM applications.
- Synthetic data paves the way for the development of ethical, efficient and innovative ai.
Frequently asked questions
A. Ollama provides local deployment capabilities, reducing cost and latency while offering more control over the build process.
A. To maintain quality, the implementation uses Pydantic validation, retry mechanisms, and JSON cleanup. Additional metrics can be implemented and validation maintained.
A. Local LLMs may have lower quality results compared to larger models, and generation speed may be limited by local computing resources.
A. Yes, synthetic data ensures privacy by removing identifiable information and promotes the ethical development of ai by addressing data biases and reducing reliance on sensitive real-world data.
A. Challenges include ensuring data realism, maintaining domain relevance, and aligning synthetic data characteristics with real-world use cases for effective model training.

I am a self-taught, project-driven learner who loves working on complex projects on deep learning, computer vision and NLP. I always try to get a deep understanding of the topic, which can be from any field, such as deep learning, machine learning, or physics. I love creating content about my learning. Try to share my understanding with the worlds.





