 NEWSLETTER
NEWSLETTER
En los últimos años, hemos visto un gran aumento en el tamaño de los modelos de lenguaje grandes (LLM) utilizados para resolver tareas de procesamiento del lenguaje natural (NLP), como la respuesta a preguntas y el resumen de textos. Los modelos más grandes con más parámetros, que están en el orden de cientos de miles de millones en el momento de escribir este artículo, tienden a producir mejores resultados. Por ejemplo, Llama-3-70B, obtiene mejores resultados que su mas pequeño Versión de parámetros 8B en métricas como la comprensión lectora (SQuAD 85,6 en comparación con 76,4). Por lo tanto, los clientes a menudo experimentan con modelos más grandes y nuevos para crear productos basados en ML que aporten valor.
Sin embargo, cuanto más grande sea el modelo, más exigente será en términos computacionales y mayor será el costo de implementación. Por ejemplo, en AWS Trainium, Llama-3-70B tiene una latencia media por token de 21,4 ms, mientras que Llama-3-8B tarda 4,7 ms. De manera similar, Llama-2-70B tiene una latencia media por token de 20,6 ms, mientras que Llama-2-7B tarda 3,7 ms. Los clientes deben considerar el rendimiento para asegurarse de satisfacer las necesidades de sus usuarios. En esta publicación de blog, exploraremos cómo muestreo especulativo Puede ayudar a que la inferencia de modelos de lenguaje grandes sea más eficiente y rentable en términos computacionales en AWS Inferentia y Trainium. Esta técnica mejora Rendimiento de inferencia LLM y latencia del token de salida (TPOT).
Introducción
Los modelos de lenguaje modernos se basan en la arquitectura del transformador. Las indicaciones de entrada se procesan primero utilizando una técnica llamada codificación de contexto, que se ejecuta rápidamente porque es paralelizable. A continuación, realizamos la generación de tokens autorregresivos donde los tokens de salida se generan secuencialmente. Tenga en cuenta que no podemos generar el siguiente token hasta que conozcamos el anterior, como se muestra en la Figura 1. Por lo tanto, para generar N tokens de salida necesitamos N ejecuciones en serie a través del decodificador. Una ejecución lleva más tiempo a través de un modelo más grande, como Llama-3-70B, que a través de un modelo más pequeño, como Llama-3-8B.
Figura 1: Generación secuencial de tokens en LLM
Desde una perspectiva computacional, la generación de tokens en los LLM es un proceso limitado por el ancho de banda de la memoria. Cuanto más grande sea el modelo, más probable es que esperemos transferencias de memoria. Esto da como resultado la subutilización de las unidades de cómputo y el no aprovechamiento total de las operaciones de punto flotante (FLOPS) disponibles.
Muestreo especulativo
El muestreo especulativo es una técnica que mejora la eficiencia computacional para ejecutar inferencias con LLM, manteniendo al mismo tiempo la precisión. Funciona mediante el uso de un modelo de borrador más pequeño y más rápido para generar múltiples tokens, que luego son verificados por un modelo de destino más grande y más lento. Este paso de verificación procesa múltiples tokens en una sola pasada en lugar de hacerlo de manera secuencial y es más eficiente computacionalmente que procesar tokens de manera secuencial. Aumentar la cantidad de tokens procesados en paralelo aumenta la intensidad computacional porque se puede multiplicar una mayor cantidad de tokens con el mismo tensor de peso. Esto proporciona un mejor rendimiento en comparación con la ejecución no especulativa, que generalmente está limitada por el ancho de banda de la memoria y, por lo tanto, conduce a una mejor utilización de los recursos de hardware.
El proceso especulativo implica una ventana ajustable k, donde el modelo de destino proporciona un token correcto garantizado y el modelo preliminar especula sobre los siguientes k-1 tokens. Si se aceptan los tokens del modelo preliminar, el proceso se acelera. Si no, el modelo de destino toma el control, lo que garantiza la precisión.
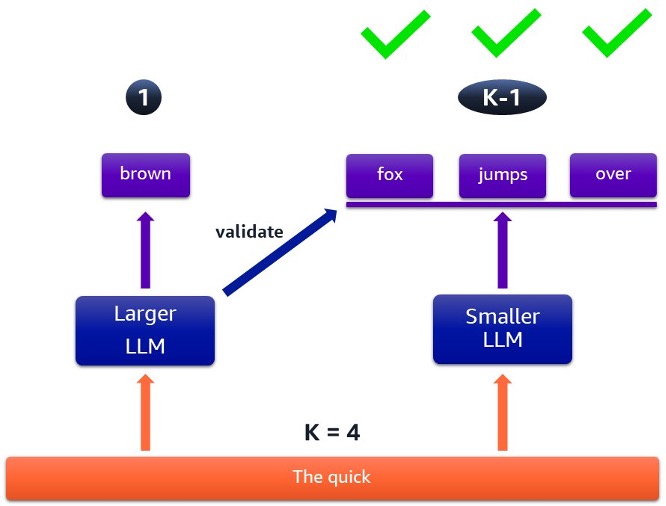
Figura 2: Caso en el que se aceptan todos los tokens especulados
La figura 2 ilustra un caso en el que se aceptan todos los tokens especulados, lo que da como resultado un procesamiento más rápido. El modelo de destino proporciona un token de salida garantizado y el modelo preliminar se ejecuta varias veces para producir una secuencia de posibles tokens de salida. Estos son verificados por el modelo de destino y posteriormente aceptados por un método probabilístico.
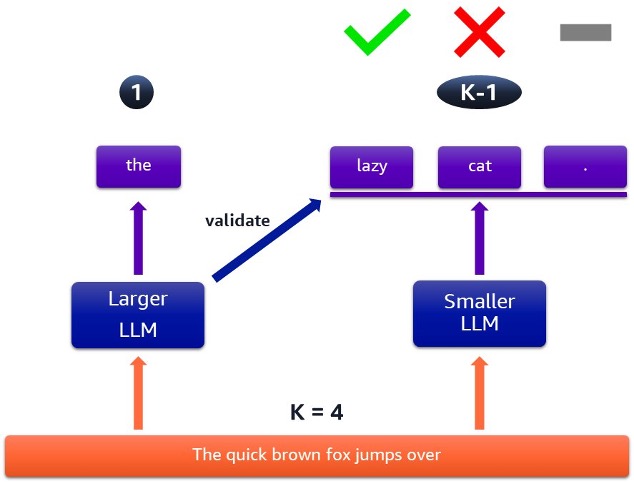
Figura 3: Caso en el que se rechazan algunos tokens especulados
Por otro lado, la Figura 3 muestra un caso en el que algunos de los tokens son rechazados. El tiempo que lleva ejecutar este ciclo de muestreo especulativo es el mismo que en la Figura 2, pero obtenemos menos tokens de salida. Esto significa que repetiremos este proceso más veces para completar la respuesta, lo que dará como resultado un procesamiento general más lento.
Al ajustar el tamaño de la ventana k y comprender cuándo es probable que los modelos borrador y objetivo produzcan resultados similares, podemos maximizar los beneficios del muestreo especulativo.
Una demostración de Llama-2-70B/7B
Mostraremos cómo funciona el muestreo especulativo en instancias amazon EC2 Inf2 impulsadas por Inferentia2 y en instancias EC2 Trn1 impulsadas por Trainium. Usaremos un muestra donde generamos texto más rápido con Llama-2-70B usando un modelo Llama-2-7B como modelo borrador. El tutorial de ejemplo se basa en modelos Llama-2, pero también puedes seguir un proceso similar para modelos Llama-3.
Cargando modelos
Puede cargar los modelos Llama-2 utilizando el tipo de datos bfloat16. El modelo preliminar debe cargarse de manera estándar, como en el ejemplo siguiente. El parámetro n_positions es ajustable y representa la longitud máxima de secuencia que desea permitir para la generación. El único batch_size En el momento de redactar este artículo, apoyamos el muestreo especulativo. Explicaremos tp_degree más adelante en esta sección.
El modelo de destino se debe cargar de manera similar, pero con la función de muestreo especulativo habilitada. El valor k se describió anteriormente.
En conjunto, los dos modelos necesitan casi 200 GB de memoria del dispositivo para los pesos, con memoria adicional del orden de los GB necesarios para los cachés de clave-valor (KV). Si prefiere utilizar los modelos con parámetros float32, necesitarán alrededor de 360 GB de memoria del dispositivo. Tenga en cuenta que los cachés de KV crecen linealmente con la longitud de la secuencia (tokens de entrada + tokens que aún no se han generado). Utilice neurona-arriba para ver el uso de la memoria en vivo. Para satisfacer estos requisitos de memoria, necesitaremos la instancia Inf2 más grande (inf2.48xlarge) o la instancia Trn1 más grande (trn1.32xlarge).
Debido al tamaño de los modelos, sus pesos deben distribuirse entre los NeuronCores utilizando una técnica llamada paralelismo tensorial. Tenga en cuenta que en el ejemplo proporcionado, tp_grado se utiliza por modelo para especificar cuántos NeuronCores debe utilizar ese modelo. Esto, a su vez, afecta la utilización del ancho de banda de la memoria, que es fundamental para el rendimiento de la generación de tokens. Un valor más alto tp_degree puede conducir a una mejor utilización del ancho de banda y un mejor rendimiento. La topología para Trn1 requiere que tp_degree se establece en 1, 2, 8, 16 o un múltiplo de 32. Para Inf2, debe ser 1 o múltiplos de 2.
El orden en el que se cargan los modelos también es importante. Una vez que se ha inicializado y asignado un conjunto de NeuronCores para un modelo, no se pueden utilizar los mismos NeuronCores para otro modelo a menos que se trate exactamente del mismo conjunto. Si intenta utilizar solo algunos de los NeuronCores que se inicializaron previamente, obtendrá un error nrt_load_collectives - global nec_comm is already init'd error.
Veamos dos ejemplos en trn1.32xlarge (32 NeuronCores) para comprender esto mejor. Calcularemos cuántos NeuronCores necesitamos por modelo. La fórmula utilizada es el tamaño del modelo observado en la memoria, utilizando neuron-top, dividido por 16 GB, que es la memoria del dispositivo por NeuronCore.
- Si ejecutamos los modelos con bfloat16, necesitamos más de 10 NeuronCores para Llama-2-70B y más de 2 NeuronCores para Llama-2-7B. Debido a las restricciones de topología, significa que necesitamos al menos
tp_degree=16para Llama-2-70B. Podemos usar los 16 NeuronCores restantes para Llama-2-7B. Sin embargo, debido a que ambos modelos caben en la memoria en 32 NeuronCores, deberíamos configurartp_degree=32para ambos, para acelerar la inferencia del modelo para cada uno. - Si ejecutamos los modelos usando float32, necesitamos más de 18 NeuronCores para Llama-2-70B y más de 3 NeuronCores para Llama-2-7B. Debido a las restricciones de topología, tenemos que establecer
tp_degree=32para Llama-2-70B. Eso significa que Llama-2-7B necesita reutilizar el mismo conjunto de NeuronCores, por lo que debe configurartp_degree=32También para Llama-2-7B.
Tutorial
El decodificador que usaremos de transformers-neuronx es LlamaParaMuestreoque es adecuado para cargar y ejecutar modelos de Llama. También puedes usar Modelo automático de neuronas para LM causal que intentará detectar automáticamente qué decodificador utilizar. Para realizar un muestreo especulativo, primero debemos crear un generador especulativo que tome dos modelos y el valor k descrito anteriormente.
Invocamos el proceso de inferencia llamando a la siguiente función:
Durante el muestreo, hay varios hiperparámetros (por ejemplo: temperature, top_py top_k) que afectan si el resultado es determinista en múltiples ejecuciones. Al momento de escribir este artículo, la implementación del muestreo especulativo establece valores predeterminados para estos hiperparámetros. Con estos valores, espere aleatoriedad en los resultados cuando ejecute un modelo varias veces, incluso si es con el mismo mensaje. Este es el comportamiento normal previsto para los LLM porque mejora sus respuestas cualitativas.
Cuando ejecute la muestra, utilizará el aceptador de token predeterminado, según el Artículo de DeepMind que introdujo el muestreo especulativoque utiliza un método probabilístico para aceptar tokens. Sin embargo, también puede implementar un aceptador de tokens personalizado, que puede pasar como parte de la acceptor parámetro cuando inicializa el SpeculativeGenerator. Puede hacerlo si desea respuestas más deterministas, por ejemplo. Vea la implementación del Aceptador de token predeterminado Clase de transformers-neuronx para entender cómo escribir el tuyo propio.
Conclusión
A medida que más desarrolladores buscan incorporar modelos LLM en sus aplicaciones, se enfrentan a la opción de usar modelos más grandes, más costosos y más lentos que brindarán resultados de mayor calidad. O pueden usar modelos más pequeños, menos costosos y más rápidos que podrían reducir la calidad de las respuestas. Ahora, con los chips de inteligencia artificial (IA) de AWS y el muestreo especulativo, los desarrolladores no tienen que tomar esa decisión. Pueden aprovechar los resultados de alta calidad de los modelos más grandes y la velocidad y capacidad de respuesta de los modelos más pequeños.
En esta publicación de blog, demostramos que podemos acelerar la inferencia de modelos grandes, como Llama-2-70B, mediante el uso de una nueva función llamada muestreo especulativo.
Para probarlo usted mismo, consulte el ejemplo de muestreo especulativoy modifique el mensaje de entrada y el parámetro k para ver los resultados que obtiene. Para casos de uso más avanzados, puede desarrollar su propia implementación de aceptador de tokens. Para obtener más información sobre cómo ejecutar sus modelos en instancias de Inferentia y Trainium, consulte la Documentación de AWS NeuronTambién puedes visitar Canal de AWS Neuron repost.aws para discutir sus experimentaciones con la comunidad de AWS Neuron y compartir ideas.
Acerca de los autores
 Sil taylor Syl es una arquitecta de soluciones especializada en computación eficiente. Asesora a clientes de EMEA sobre la optimización de costos de amazon EC2 y la mejora del rendimiento de las aplicaciones mediante chips diseñados por AWS. Anteriormente, Syl trabajó en desarrollo de software e inteligencia artificial y aprendizaje automático para AWS Professional Services, diseñando e implementando soluciones nativas de la nube. Vive en el Reino Unido y le encanta pasar tiempo en la naturaleza.
Sil taylor Syl es una arquitecta de soluciones especializada en computación eficiente. Asesora a clientes de EMEA sobre la optimización de costos de amazon EC2 y la mejora del rendimiento de las aplicaciones mediante chips diseñados por AWS. Anteriormente, Syl trabajó en desarrollo de software e inteligencia artificial y aprendizaje automático para AWS Professional Services, diseñando e implementando soluciones nativas de la nube. Vive en el Reino Unido y le encanta pasar tiempo en la naturaleza.
 Configuración de orden es arquitecto de soluciones senior y líder técnico del equipo de creación de prototipos de AWS. Se especializa en ayudar a los clientes a crear soluciones de IA generativa y de aprendizaje automático, y en implementar las mejores prácticas arquitectónicas. Ayuda a los clientes a experimentar con arquitecturas de soluciones para lograr sus objetivos comerciales, haciendo hincapié en la innovación ágil y la creación de prototipos. Vive en Luxemburgo y le gusta tocar sintetizadores.
Configuración de orden es arquitecto de soluciones senior y líder técnico del equipo de creación de prototipos de AWS. Se especializa en ayudar a los clientes a crear soluciones de IA generativa y de aprendizaje automático, y en implementar las mejores prácticas arquitectónicas. Ayuda a los clientes a experimentar con arquitecturas de soluciones para lograr sus objetivos comerciales, haciendo hincapié en la innovación ágil y la creación de prototipos. Vive en Luxemburgo y le gusta tocar sintetizadores.






{kind=link}