 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have emerged as powerful general-purpose task solvers, capable of assisting people in various aspects of daily life through conversational interactions. However, the predominant reliance on text-based interactions has significantly limited their application in scenarios where text input and output are suboptimal. While recent advances such as GPT4o have introduced extremely low-latency voice interaction capabilities, improving user experience, the open-source community still needs thorough exploration in building LLM-based voice interaction models. The pressing challenge that researchers are striving to solve is how to achieve low-latency and high-quality voice interaction with LLMs, expanding their accessibility and applicability in diverse usage scenarios.
Several approaches have been attempted to enable speech interaction with LLMs, each with limitations. The simplest method involves a cascaded system using automatic speech recognition (ASR) and text-to-speech (TTS) models. However, this sequential approach results in higher latency due to the step-by-step processing of transcribed text, text response, and voice response. Multimodal speech-language models have also been proposed, which discretize speech into tokens and extend LLM vocabularies to support speech input and output. While these models theoretically allow direct speech-to-speech generation with low latency, practical implementation often involves generating intermediate text to maintain higher quality, sacrificing some response speed. Other attempts include training language models on semantic or acoustic tokens, jointly training speech and text tokens, and adding vocoders to LLMs. However, these methods often require substantial data and computational resources or focus solely on speech understanding without generation capabilities.
Researchers from the University of the Chinese Academy of Sciences presented LLAMA-Omnian innovative model architecture, which has been proposed to overcome the challenge of achieving low-latency, high-quality voice interaction with LLM. This innovative approach integrates a voice encoder, voice adapter, LLM, and voice decoder in real-time to enable seamless voice-to-voice communication. The model processes the voice input directly through the encoder and adapter before feeding it into the LLM, bypassing the need for intermediate text transcription. A non-autoregressive streaming transformer acts as the voice decoder, using connectionist temporal classification to predict discrete units corresponding to the voice response. This architecture enables simultaneous generation of text and voice outputs, significantly reducing response latency. To support the development and evaluation of this model, the researchers created the InstructS2S-200K dataset, specifically designed for voice interaction scenarios.
The LLaMA-Omni architecture consists of four main components: a voice encoderto voice adaptera Master of Lawsand a voice decoderThe speech encoder, based on Whisper-large-v3, extracts meaningful representations from the user's speech input. The speech adapter then processes these representations and maps them to the LLM embedding space using down-sampling and a two-layer perceptron. The LLM, based on Llama-3.1-8B-Instruct, generates text responses directly from the speech instruction. The speech decoder, a non-autoregressive streaming transformer, takes the output hidden states of the LLM and uses connectionist temporal classification (CTC) to predict discrete units corresponding to the speech response.
The model employs a two-stage training strategy. In the first stage, it learns to generate text responses from voice prompts. The second stage focuses on generating voice responses, with only the speech decoder being trained. During inference, LLaMA-Omni simultaneously generates text and speech responses. As LLaMA-Omni produces text, the speech decoder generates corresponding discrete units, which are then converted into speech waveforms in real time. This approach enables extremely low-latency voice interaction, as users can hear responses before the full text is generated.
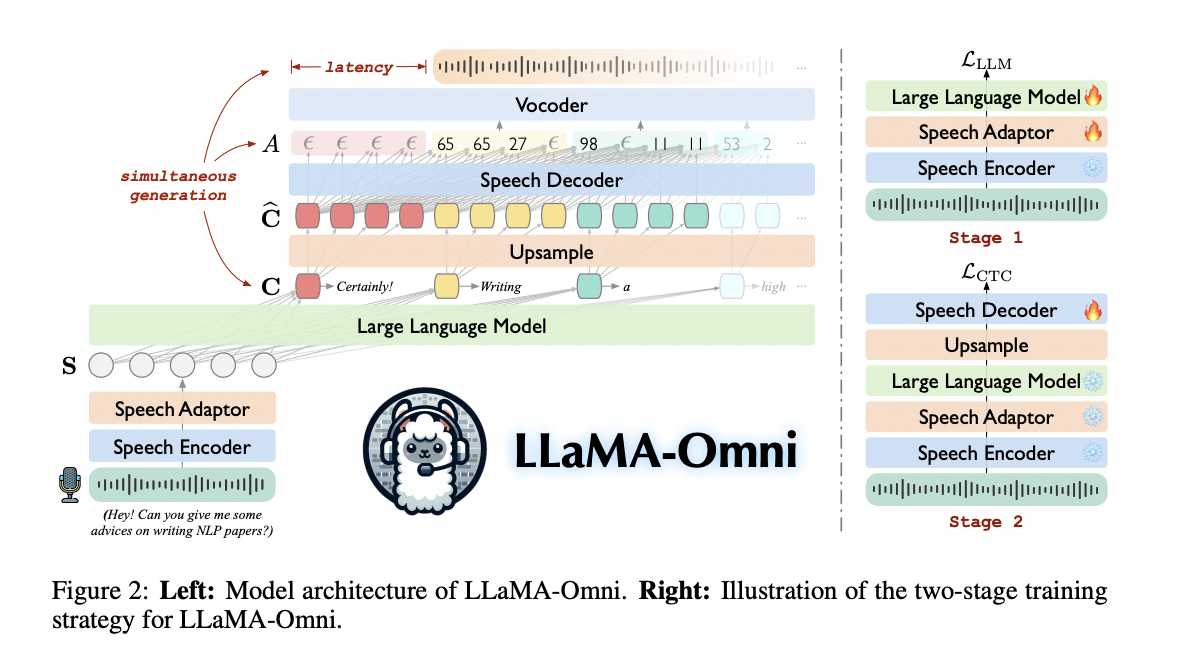
The InstructS2S-200K dataset was built to train LLaMA-Omni for voice interaction. It consists of 200,000 triplets of voice instructions, text responses, and voice responses. The construction process involved rewriting the text instructions to speech using Llama-3-70B-Instruct, generating concise responses suitable for speech, and synthesizing the speech using CosyVoice-300M-SFT for instructions and VITS for responses. The dataset combines 50,000 inputs from Alpaca and 150,000 from UltraChat, covering a variety of topics. This specialized dataset provides a solid foundation for training LLaMA-Omni on speech-based tasks, ensuring natural and efficient interactions.
LLaMA-Omni outperforms previous models in voice interaction tasks, as demonstrated by the results of the InstructS2S-Eval benchmark. It excels in both content and style for both speech-to-text and speech-to-speech instruction, achieving better alignment between speech and text responses. The model strikes a balance between speech quality and response latency, with a latency of just 226 ms. LLaMA-Omni’s simultaneous generation of text and speech results in significantly faster decoding times compared to other models. Case studies show that LLaMA-Omni provides more concise, detailed, and useful responses suitable for voice interaction scenarios, outperforming previous models in this context.
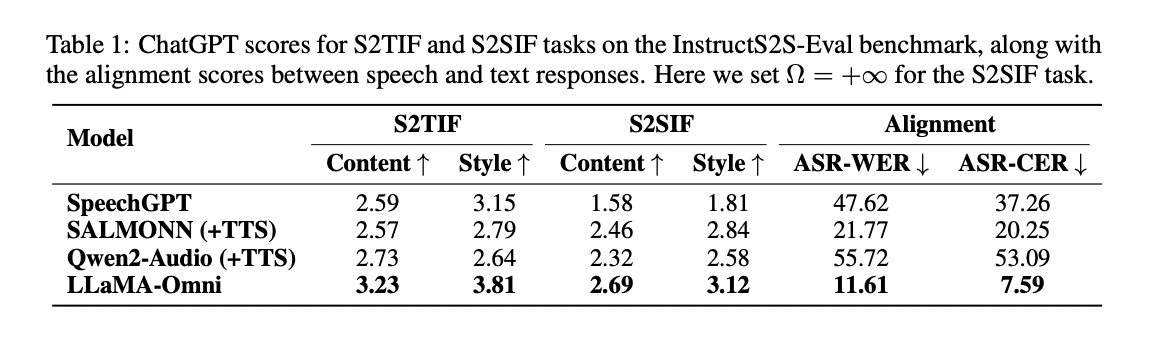
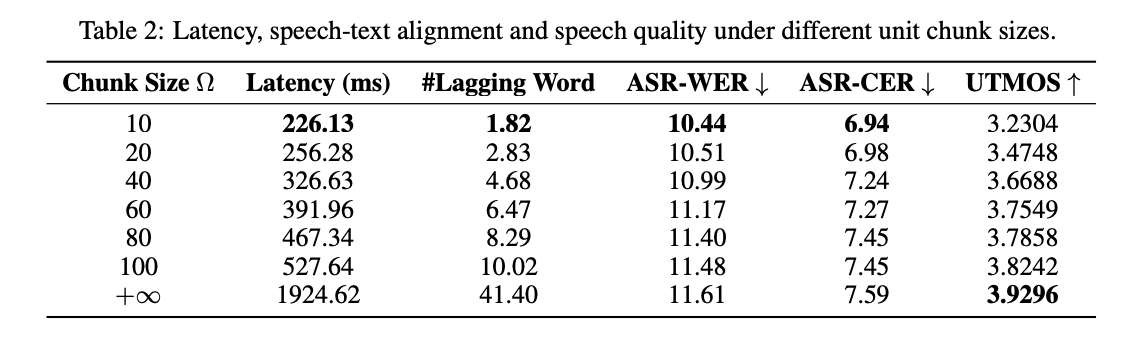
LLaMA-Omni, an innovative model architecture, has been developed to enable high-quality, low-latency voice interaction with LLMs. Based on the Llama-3.1-8B-Instruct model, LLaMA-Omni incorporates a speech encoder for understanding and a real-time speech decoder for simultaneous text and voice response generation. Alignment of the model with voice interaction scenarios was achieved by creating InstructionS2S-200K, a dataset containing 200,000 voice instructions and responses. Experimental results demonstrate LLaMA-Omni’s superior performance in both content and style compared to existing speech-language models, with a remarkably low response latency of 226 ms. The efficient model training process, requiring less than 3 days on 4 GPUs, facilitates the rapid development of state-of-the-art LLM-based voice interaction models.
Take a look at the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
FREE ai WEBINAR: 'SAM 2 for Video: How to Optimize Your Data' (Wednesday, September 25, 4:00 am – 4:45 am EST)
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}