NEWSLETTER
NEWSLETTER
La carrera por el dominio en los modelos de idiomas centrados en el código se está calentando, y abrazar la cara ha entrado en la arena con un fuerte contendiente: OlympicCoder-7B, parte de su iniciativa Open-R1. Diseñado para sobresalir en la programación competitiva, el modelo está ajustado utilizando un conjunto de datos de CodeForces de cadena de pensamiento. Sorprendentemente, ya ha mostrado resultados impresionantes, superando el soneto Claude 3.7 en el punto de referencia IOI. ¿Pero esto significa que abrazar el modelo 7B de Face realmente supera a Claude 3.7? En este blog, examinaremos los puntajes de referencia de OlympicCoder-7b, exploraremos la arquitectura de razonamiento detrás del modelo y demostraremos cómo usarla.
¿Qué es OlympicCoder?
Abrazing Face dirige un proyecto impulsado por la comunidad llamado Iniciativa Open-R1, destinada a construir modelos de razonamiento abiertos y de alta calidad. Esta iniciativa ha llevado al desarrollo de dos modelos especializados en código:
- Olympiccoder-7b
- Olympiccoder-32b
OlympicCoder-7B se basa en el instrucciones QWEN2.5-Coder-7B, un modelo de código abierto de Alibaba Cloud. Lo que lo distingue es su ajuste fino utilizando el conjunto de datos CodeForcess-Cots, que incluye miles de problemas de programación competitivos de CodeForces. La adición del razonamiento de la cadena de pensamiento (COT) hace que el modelo sea aún mejor, lo que le permite descomponer problemas complejos en pasos lógicos. Esto ayuda al modelo a ir más allá de la generación de código sintáctico a la resolución de problemas lógicos reales.
El conjunto de datos CodeForces-Cots
La construcción del conjunto de datos CodeForces para OlyMicCoder-7 B implicó destilarse casi 100,000 muestras de alta calidad usando R1 (otro modelo de iniciativa). Cada muestra incluye una declaración de problema, un proceso de pensamiento y una solución verificada tanto en C ++ como en Python. Esta configuración de doble lenguaje garantiza la robustez del modelo y la adaptabilidad en los entornos de codificación. Este conjunto de datos no era solo un simple raspado de CodeForces; En cambio, fue diseñado para reflejar cómo los codificadores humanos expertos piensan y escriben código.
Verificabilidad del código
Un problema importante en la capacitación y evaluación de modelos de código es la verificabilidad del código. Muchos conjuntos de datos existentes contienen código no verificado o incorrecto, que puede confundir modelos durante la capacitación. Para combatir esto, abrazar la cara aplicó un riguroso proceso de filtrado en Codeforcess-Cots, asegurando que solo se utilizaron muestras de alta calidad de funcionamiento.
Ioi Benchmark
OlymipicCoder-7B fue evaluado en el punto de referencia IOI. Inspirado en la Olimpiada Internacional en Informática (IOI), este punto de referencia prueba la capacidad del modelo para manejar problemas de programación competitivos del mundo real. Enfatiza el razonamiento lógico, la satisfacción de la restricción y la optimización.
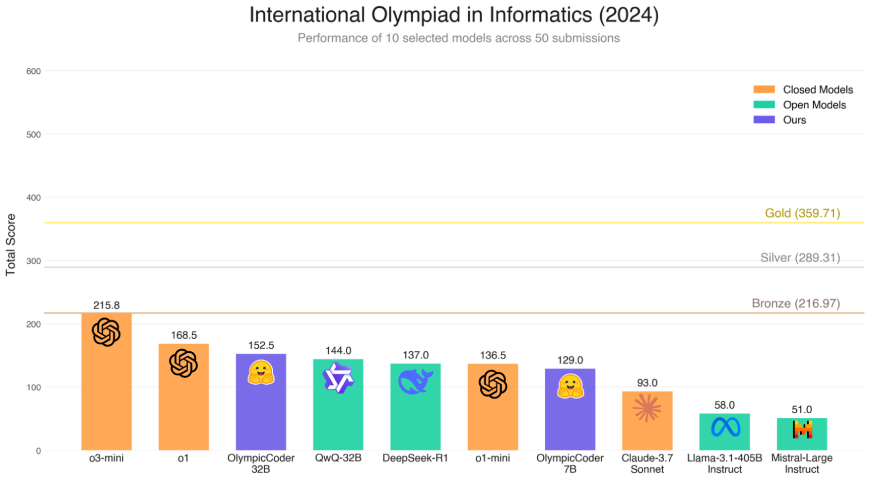
Este gráfico visualiza el rendimiento de diez modelos diferentes en el punto de referencia 2024 IOI. El puntaje final refleja qué tan bien se desempeñó cada modelo en 50 tareas de programación competitiva. Así es lo bien que OlympicCoder realizó en este punto de referencia:
- Olympiccoder-7B puntajes 129.0, colocándolo por delante del soneto Claude 3.7 (93.0) y otros modelos abiertos como Llama-3 y el instructo de mayor distensión.
- En comparación con Deepseek-R1, que obtiene 137.0, OlympicCoder-7b (129.0) está ligeramente atrasado, pero sigue siendo competitivo, especialmente teniendo en cuenta su recuento de parámetros más pequeño y su accesibilidad abierta.
- También supera a QWQ-32B (144.0) sobre la claridad del razonamiento a pesar de tener menos parámetros y recursos computacionales.
- Si bien no alcanza el nivel superior ocupado por modelos cerrados como variantes GPT-4, muestra resultados impresionantes para un modelo 7B de código abierto.
Este rendimiento afirma la capacidad de OlympicCoder-7B como un modelo de razonamiento fuerte en el dominio de código abierto.
Ejecutando OlympicCoder-7b usando Huggingface
Ahora que estamos familiarizados con Hugging Face's Olympiccoder, probemos en Google Colab.
Cómo acceder a Hugging Face's Olympiccoder
Antes de comenzar, necesitamos tener un token de acceso a la cara abrazando. Aquí le mostramos cómo conseguir uno.
- Vaya a la página de tokens de acceso en Huggingface: https://huggingface.co/settings/tokens
- Cree un nuevo token de acceso o modifique un token antiguo para obtener estos permisos.
- Copie el token de acceso y manténgalo a mano.
Cómo correr OlympicCoder-7b
Ahora que tenemos el token de acceso, abramos un entorno Jupyter y comencemos. Asegúrese de establecer el tipo de tiempo de ejecución en T4 GPU.
1. Instalaciones
Primero, debe instalar los transformadores y acelerar las bibliotecas de Pypi (índice de paquetes de Python).
! Pip Instalar Transformadores Acelerar
2. Conéctese a la cara abrazada
Agregue su token de acceso a los secretos de Colab o ejecute este comando para agregar su token de acceso.
!huggingface-cli login
3. Importar y cargar el modelo
Importar las bibliotecas necesarias.
import torchfrom transformers import pipeline
El modelo se descarga en 4 fragmentos y tiene aproximadamente 15 GB de tamaño.
pipe = pipeline("text-generation", model="open-r1/OlympicCoder-7B", torch_dtype=torch.bfloat16, device_map="auto")4. Corre la inferencia
Involucramos al modelo que genere números primos de hasta 100 al incluir el mensaje en la lista de mensajes con el rol de “usuario”. Además, puede optar por agregar un mensaje del sistema, como “usted es un desarrollador de C ++”, para guiar el comportamiento del modelo.
messages = (
{"role": "user", "content": "Write a Python program \
that prints prime numbers upto 100"})
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=8000, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs(0)("generated_text"))
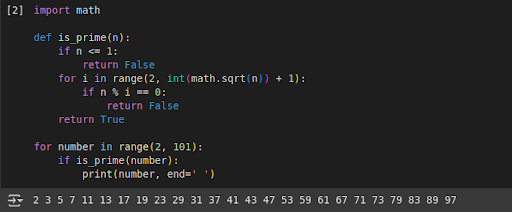
Acabo de copiar el código de Python generado por el modelo y obtuve todos los números primos como salida.
Vale la pena señalar que lleva un tiempo obtener las salidas. Desafortunadamente, no pude probar el modelo con más indicaciones, ya que lleva mucho tiempo generar salidas en Colab.
Forma alternativa de acceder a OlympicCoder
Si tiene potentes hardware y GPU en su computadora, puede intentar ejecutar OlympicCoder-7B en la aplicación LM Studio. LM Studio es una aplicación que le permite ejecutar LLM localmente en su máquina. Así que primero, sigamos estos pasos y descargemos LM Studio para comenzar a usar estos modelos.
1. Vaya al sitio web de LM Studio: <a target="_blank" href="https://lmstudio.ai/” target=”_blank” rel=”nofollow noopener”>https://lmstudio.ai/
2. Descargue la aplicación de acuerdo con su sistema operativo.
3. Busque el OlympicCoder-7B y descargue el modelo localmente. (4.68 GB)
Nota: Debido a las limitaciones de hardware en mi máquina, no ejecutaré una inferencia usando LM Studio.
Lecciones del OlympicCoder de entrenamiento
Abrazo, ha compartido varias lecciones al entrenar al Olympiccoder que podría beneficiar a la comunidad de IA más amplia:
- El embalaje de muestra afecta el razonamiento: Las muestras de entrenamiento de embalaje mejoran de manera más eficiente la profundidad del razonamiento al permitir secuencias de cuna más largas.
- Altas tasas de aprendizaje ayudan: Al contrario de las configuraciones tradicionales, usar tasas de aprendizaje más grandes ayudó a estabilizar la capacitación.
- Los editoriales mejoran el rendimiento: La inclusión de los editoriales de CodeForces en los datos de capacitación enriquecieron el estilo de resolución de problemas del modelo.
- Prefárado con Etiquetas: Este truco alienta al modelo a generar cadenas de pensamiento más largas y coherentes.
- Optimizadores de 8 bits: El uso de estos optimizadores ayudó a entrenar modelos grandes de manera eficiente, especialmente en tareas de razonamiento de contexto largo.
Estas ideas son valiosas para cualquier persona interesada en construir o ajustar modelos de razonamiento de código.
Actualizaciones recientes del proyecto Open-R1
Abrazar la cara también ha avanzado el ecosistema Open-R1 con desarrollos emocionantes:
- Optimización de política relativa agrupada (GRPO): Un nuevo método de aprendizaje de refuerzo para el ajuste eficiente de los LLM de razonamiento.
- Abra el conjunto de datos de matemáticas R1: Centrado en el razonamiento matemático, esto complementa el OlympicCoder centrado en el código.
- Curso de razonamiento: Un plan de estudios diseñado para entrenar LLM en múltiples dominios con ejercicios de razonamiento estructurados.
- Contribuciones de la comunidad: Desde conjuntos de datos mejorados hasta integraciones con IDES, la comunidad está expandiendo rápidamente la utilidad de OlympicCoder.
Aplicaciones de OlympicCoder-7B
Aquí hay algunos escenarios prácticos en los que OlympicCoder-7B sobresale:
- Capacitación de programación competitiva: Con su ajuste fino de la cadena de pensamiento, OlympicCoder puede ayudar a los usuarios no solo a generar un código correcto, sino también a comprender los pasos lógicos necesarios para resolver desafíos algorítmicos.
- Revisión del código con razonamiento: A diferencia de los modelos simples de finalización de código, OlympicCoder proporciona explicaciones junto con sus sugerencias. Esto lo hace valioso como asistente para revisar el código, detectar fallas lógicas o recomendar mejores prácticas.
- Explicaciones generadoras de estilo editor: El modelo puede simular la estructura y el tono de los editoriales de programación competitiva. De esta manera, ayuda a los usuarios a comprender los enfoques de resolución de problemas de manera más intuitiva.
- Construir tutores de codificación personalizados: Los desarrolladores y educadores pueden usar OlympicCoder para crear sistemas de tutoría inteligente que expliquen conceptos, evalúen el código y guíen a los alumnos a través de la resolución iterativa de problemas.
- Aplicaciones educativas para algoritmos y estructuras de datos: OlympicCoder puede generar ejemplos, visualizar la lógica paso a paso y responder preguntas basadas en la teoría. Esto lo convierte en una gran herramienta para enseñar materias CS centrales.
Mi experiencia trabajando con el modelo
Trabajar con OlympicCoder-7B fue una experiencia perspicaz. Configurarlo a través de Google Colab fue directo, aunque la velocidad de inferencia estaba limitada por limitaciones de hardware. El modelo generó un código bien razonado y preciso, a menudo acompañado de comentarios o explicaciones. El uso de una cadena de pensamiento era visible en cómo el modelo abordaba las declaraciones del problema paso a paso. Encontré su capacidad para producir código funcional y desgloses lógicos particularmente útiles cuando se trabaja en indicaciones algorítmicas.
También exploré su implementación local a través de LM Studio, aunque las limitaciones de hardware en mi máquina evitaban las pruebas completas. Aún así, la experiencia afirmó que OlympicCoder está listo para la experimentación y la integración locales en flujos de trabajo avanzados para aquellos con el hardware correcto.
Conclusión
OlympicCoder-7B, como parte de la iniciativa Open-R1 de Hugging Face, representa un paso importante hacia modelos de razonamiento de código abierto y poderosos. Su fuerte presentación en el punto de referencia IOI, la capacitación de conjuntos de datos robustas utilizando estrategias de cot y la aplicabilidad del mundo real lo convierten en una herramienta valiosa para desarrolladores, investigadores, educadores y programadores competitivos por igual.
Cierre la brecha entre la generación de código y la resolución de problemas, ofreciendo no solo salidas, sino también información. Con más apoyo de la comunidad y actualizaciones continuas, OlympicCoder tiene el potencial de convertirse en un modelo fundamental para el razonamiento de código en el ecosistema de IA de código abierto.
OlympicCoder-7B, como parte de la iniciativa Open-R1 de Hugging Face, representa un paso importante hacia modelos de razonamiento de código abierto y poderosos. Su rendimiento en puntos de referencia IOI, diseño innovador del conjunto de datos y razonamiento de cuna profunda lo convierten en una herramienta convincente para desarrolladores, estudiantes e investigadores por igual.
Preguntas frecuentes
R. El punto de referencia IOI mide la capacidad de un modelo para resolver problemas de programación competitivos, a menudo utilizados para evaluar las capacidades de razonamiento y codificación.
A. Qwen es una serie de modelos de idiomas grandes desarrollados por Alibaba Cloud, incluidas versiones especializadas para codificación, matemáticas y otras tareas.
A. Olympiccoder-32B se ajustó a partir de la instrucción QWEN/QWEN2.5-Coder-32B.
R. Es el conjunto de datos utilizado para capacitar al modelo OlympicCoder-7B, que comprende datos de CodeForces descontaminados con razonamiento de cadena de pensamiento (COT).

Apasionado por la tecnología y la innovación, un graduado del Instituto de Tecnología Vellore. Actualmente trabaja como aprendiz de ciencia de datos, centrándose en la ciencia de datos. Profundamente interesado en el aprendizaje profundo y la IA generativa, ansiosos por explorar técnicas de vanguardia para resolver problemas complejos y crear soluciones impactantes.
Inicie sesión para continuar leyendo y disfrutando de contenido curado por expertos.