 NEWSLETTER
NEWSLETTER
In recent times, large language models (LLMs) built on the Transformer architecture have demonstrated remarkable capabilities in a wide range of tasks. However, these impressive capabilities often come with a significant increase in model size, resulting in substantial GPU memory costs during inference. KV cache is a popular method used in LLM inference. It saves previously computed keys and values in the attention process, which can then be reused to speed up future steps, making the inference process faster overall. Most existing KV cache compression methods focus on intra-layer compression within a single Transformer layer, but few works consider layer-wise compression. The memory used by the KV (key-value) cache is mainly occupied by storing the key and value components of the attention map, which account for more than 80% of the total memory usage. This makes system resources inefficient and creates a demand for more computing power.
Researchers have developed many methods to compress KV caches to reduce memory consumption. However, most of these researches mainly focus on compressing the KV cache within each layer of LLM Transformer. However, layered KV cache compression strategies remain largely unexplored, which compute the KV cache only for a subset of layers to minimize memory usage. The limited existing work on layered KV cache compression generally requires additional training to maintain satisfactory performance. Most of the existing KV cache compression work, such as H2O, SnapKV, and PyramidInfer, are carried out within a single transformer layer, i.e., intra-layer compression, but do not address layer-wise KV cache compression. Some works like CLA, LCKV, Ayer, etc. have focused on layered compression strategies for the KV cache. However, all of them require further model training rather than being plug-and-play in well-trained LLMs.
A group of researchers from Shanghai Jiao Tong University, Central South University, Harbin Institute of technology, and ByteDance proposed KVSharea plug-and-play method to compress the KV cache of well-trained LLMs. The researchers discovered the method, where the KV caches differ greatly between two layers, sharing the KV cache of one layer with the other during inference does not significantly reduce performance. Leveraging observations, KVSharer employs a search strategy to identify the KV cache sharing strategy at different layers during inference. KVSharer significantly reduces GPU memory consumption while maintaining most of the model's performance. As a layered KV cache compression technique, KVSharer works well with existing methods that compress KV caches within each layer, providing an additional way to optimize memory in LLM.
The main steps of KVShare They are divided into two parts. First, a given LLM looks for a sharing strategy, a list that specifies which layers' KV caches should be replaced by those of other specific layers. Then, during the next steps of preloading and generating all tasks, the KV caches are used.
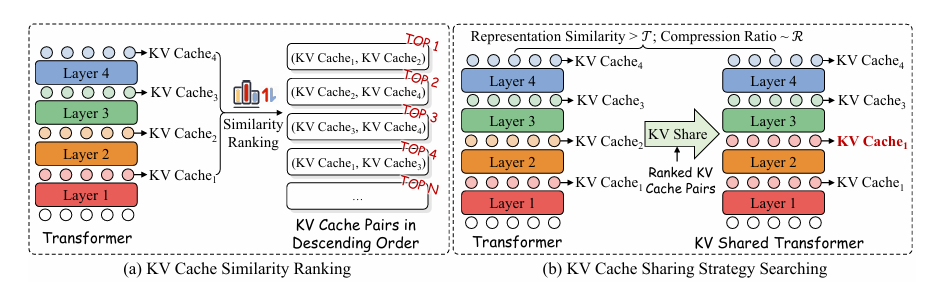
An effective KV cache sharing strategy for LLM starts by measuring the differences between the KV caches of each layer in a test data set, focusing on sharing the most dissimilar pairs. KV caches are shared from one layer to another, with priority given to layers close to the output to avoid any performance degradation. Each shared pair is only kept if the result is still similar enough to the original. This process continues until the target number of shared layers is reached, resulting in a strategy that speeds up future tasks by efficiently reusing KV caches.
The researchers tested the KVSharer model on several bilingual and English models, including call2 and InternLM2and found that it can effectively compress data with only small performance losses. Using the OpenCompass benchmark, the group of researchers evaluated the model's ability to reason, language, knowledge, and task understanding with data sets such as CMNLI, HellaSwagand Common sense quality control. At lower compression levels 25%KVSharer retained approximately 90-95% of the original model's performance and worked well with other compression techniques such as H2O and PyramidInferimproving memory efficiency and processing speed. Testing on larger models, such as Call2-70Bconfirmed KVSharer's ability to effectively compress the cache with minimal performance impact.
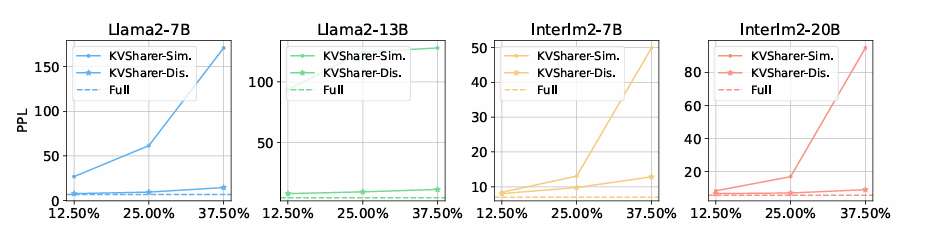
In conclusion, The proposed KVSharer method offers an efficient solution to reduce memory consumption and improve inference speed in LLM by leveraging a counterintuitive approach of sharing different KV caches. Experiments show that KVSharer maintains more than 90% of the original performance of conventional LLMs while reducing the KV cache computation by 30%. It can also provide at least 1.3 times a speedup in generation. Additionally, KVSharer can be integrated with existing intra-layer KV cache compression methods to achieve even greater memory savings and faster inference. Therefore, this method works well with current compression techniques, can be used for different tasks without requiring additional training, and can be used as a basis for future developments in the domain.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Trend) LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLM) for Intel PCs
Divyesh is a Consulting Intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of technology Kharagpur. He is a data science and machine learning enthusiast who wants to integrate these leading technologies in agriculture and solve challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}