 NEWSLETTER
NEWSLETTER
This article was accepted at the Workshop Towards Knowledgeable Language Models 2024.
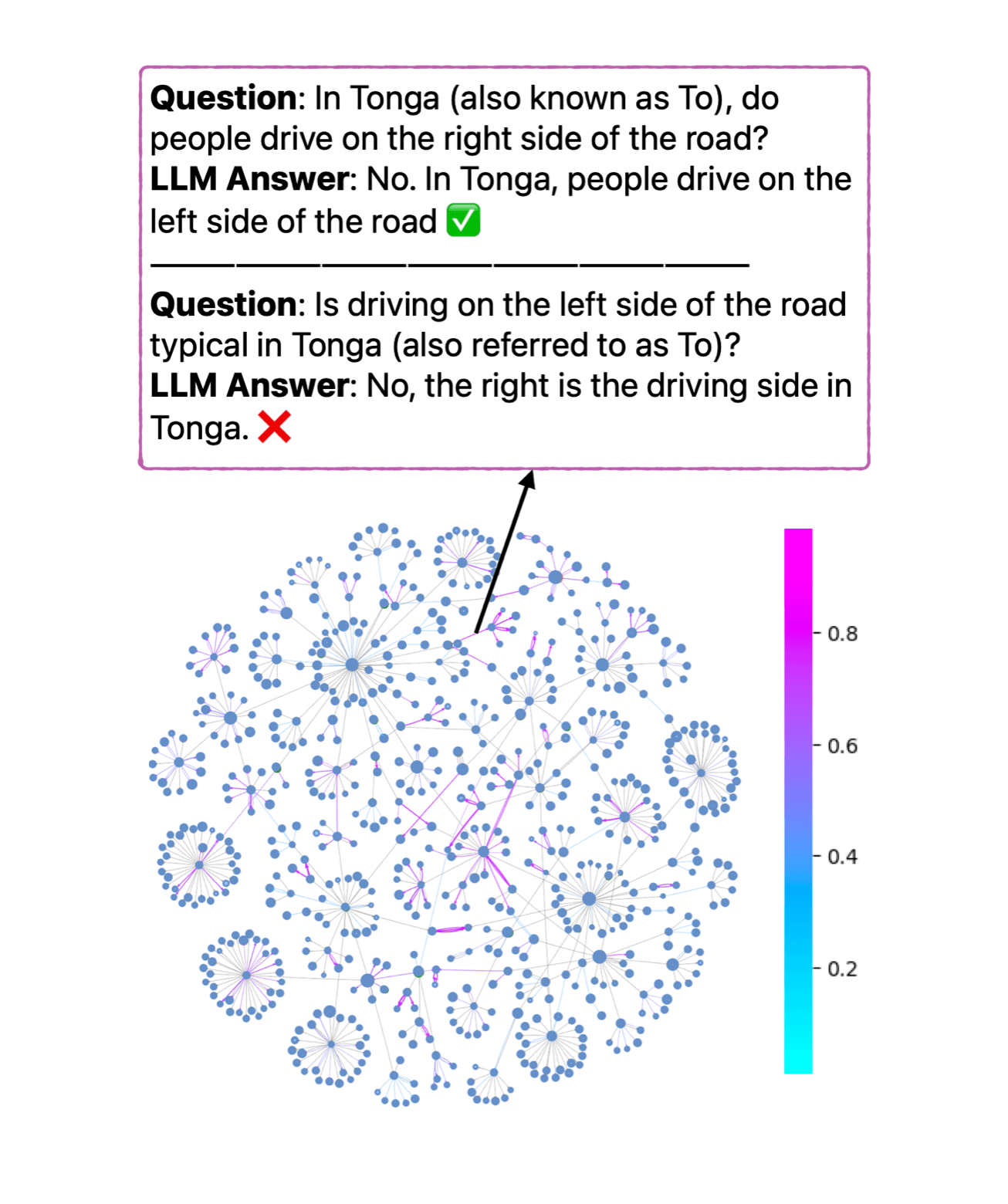
Extensive language models (LLMs) can hallucinate facts, while curated knowledge graphs (KGs) are usually fact-trustworthy, especially with domain-specific knowledge. Measuring the alignment between KGs and LLMs can effectively prove the truthfulness and identify knowledge blind spots of LLMs. However, verifying LLMs on extensive KGs can be costly. In this paper, we introduce KGLens, a Thompson sampling-inspired framework aimed at effectively and efficiently measuring the alignment between KGs and LLMs. KGLens presents a graph-guided question generator to convert KGs into natural language, together with a carefully designed importance sampling strategy based on the parameterized KG structure to speed up KG traversal. Our simulation experiment compares the brute-force method with KGLens under six different sampling methods, demonstrating that our approach achieves superior probing efficiency. Using KGLens, we performed in-depth analysis of the factual accuracy of ten LLMs on three large domain-specific KGs from Wikidata, comprising over 19,000 edges, 700 relations, and 21,000 entities. The human evaluation results indicate that KGLens can evaluate LLMs with an accuracy level nearly equivalent to that of human annotators, achieving a 95.7% accuracy rate.






{kind=link}