 NEWSLETTER
NEWSLETTER
Large language and vision models (LLVMs) face a critical challenge in balancing performance improvements with computational efficiency. As models increase in size, reaching up to 80 billion parameters, they deliver impressive results but require massive hardware resources for training and inference. This problem becomes even more pressing for real-time applications, such as augmented reality (AR), where deploying these large models on resource-constrained devices, such as mobile phones, is nearly impossible. Overcoming this challenge is essential to enable LLVMs to operate efficiently in various fields without the high computational costs traditionally associated with larger models.
Existing methods to improve LLVM performance typically involve increasing model size, selecting larger datasets, and incorporating additional modules to improve vision language understanding. While these approaches improve accuracy, they impose significant computational burdens as they require high-end GPUs and a large amount of VRAM for training and inference. This makes them impractical for real-time applications and resource-constrained environments. Furthermore, integrating external vision modules adds complexity, further limiting their use in on-device applications.
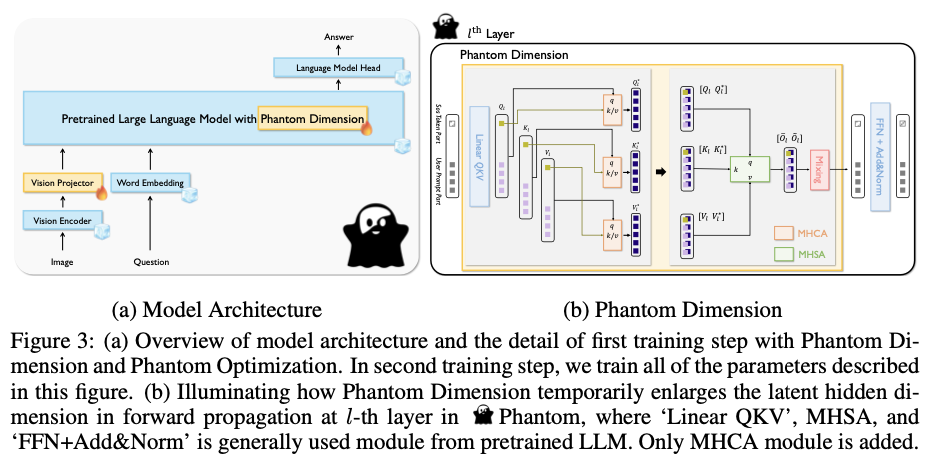
KAIST researchers propose the Phantom LLVM family, which includes models ranging from 0.5B to 7B parameters. Phantom improves learning capabilities by temporarily increasing the latent hidden dimension during multi-head self-attention (MHSA), a feature referred to as the “phantom dimension.” This innovation allows the model to incorporate significantly more knowledge of the language of vision without a permanent increase in model size. Phantom Optimization (PO) is also introduced, which combines autoregressive supervised fine-tuning (SFT) with a direct preference optimization (DPO)-like approach to minimize errors and ambiguities in the results. This approach significantly improves computational efficiency while maintaining high performance.
Phantom models employ the InternViT-300M as a vision encoder, which aligns text-to-image representations through contrastive learning. The vision projector, built using two fully connected layers, adapts the hidden dimension to the latent space of the corresponding multimodal LLM. A central aspect of Phantom is the temporal enlargement of the latent hidden dimension during MHSA, which improves the model’s ability to incorporate visual language knowledge without increasing its physical size. Models are trained using a dataset of 2.8 million samples of visual instructions, selected from 2 million Phantom triples (questions, correct answers, and incorrect or ambiguous answers). These triples play a crucial role in training via PO, improving response accuracy by removing confusion.
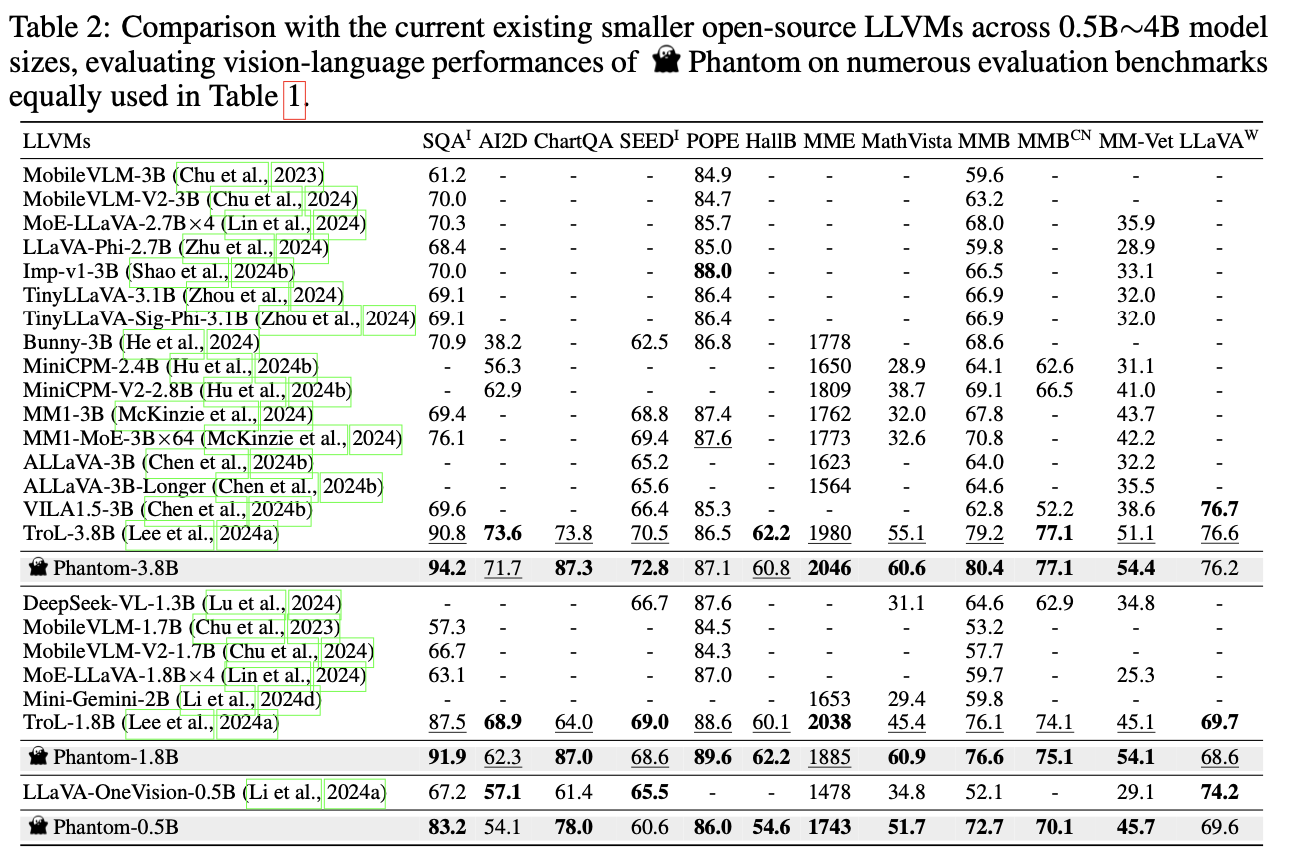
Phantom shows significant performance improvements on several benchmarks, outperforming many larger models on tasks involving image understanding, graph interpretation, and mathematical reasoning. For example, on benchmarks such as SQAI and ChartQA, Phantom’s accuracy outperforms larger models such as Cambrian-1-13B and SPHINX-MoE-7B×8. These results demonstrate Phantom’s ability to efficiently handle complex vision and language tasks, all while using a smaller model size. This efficiency is largely due to Phantom Dimension and Phantom Optimization, which allow the model to maximize learning without a proportional increase in computational requirements.
The Phantom LLVM family introduces a new approach to addressing the challenge of balancing performance and computational efficiency in large vision language models. Through innovative use of Phantom Dimension and Phantom Optimization, Phantom enables smaller models to perform at the same rate as much larger models, reducing the computational burden and making these models feasible for deployment in resource-constrained environments. This innovation has the potential to expand the application of ai models across a broader range of real-world scenarios.
Take a look at the Paper and GitHubAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from Indian Institute of technology, Kharagpur. He is passionate about Data Science and Machine Learning and has a strong academic background and hands-on experience in solving real-world interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}