
Los investigadores de Apple están avanzando en el campo del aprendizaje automático a través de investigaciones fundamentales que mejoran la comprensión mundial de esta tecnología y ayudan a redefinir lo que es posible con ella. Este trabajo puede conducir a avances en los productos y servicios de Apple, y los beneficios de la investigación se extienden más allá del ecosistema de Apple, ya que se comparte con la comunidad de investigación más amplia a través de publicaciones, recursos de código abierto y participación en eventos de la industria y la comunidad de investigación.
La próxima semana, el 38a Conferencia anual sobre sistemas de procesamiento de información neuronal (NeurIPS)se llevará a cabo en Vancouver, Canadá. NeurIPS es la conferencia anual de investigación de ML e IA más grande, y Apple se enorgullece de participar una vez más en este importante evento para la comunidad y apoyarlo con nuestro patrocinio.
En la conferencia principal y los talleres asociados, los investigadores de Apple presentarán muchos artículos sobre una variedad de temas de ML. Como se destaca a continuación, esto incluye nuevos trabajos que promueven el aprendizaje automático que preserva la privacidad, hacen que los modelos multimodales sean más capaces, mejoran la capacitación previa de los LLM, exploran la capacidad de razonamiento de los LLM y comprenden el aprendizaje autosupervisado.
Los asistentes a NeurIPS podrán experimentar demostraciones de la investigación de ML de Apple en nuestro stand (#323 en West Hall A), durante el horario de exhibición, y Apple también patrocina y participa en una serie de eventos organizados por grupos de afinidad que apoyan a grupos subrepresentados en el Comunidad de aprendizaje automático. Puede encontrar una descripción general completa de la participación y las contribuciones de Apple a NeurIPS 2024 aquí, y a continuación se muestra una selección de los aspectos más destacados.
Avanzando en el aprendizaje automático para preservar la privacidad
En Apple, creemos que la privacidad es un derecho humano fundamental y el avance de las técnicas de aprendizaje automático que preservan la privacidad es un área importante de investigación en curso. Los trabajos que los investigadores de Apple presentarán en NeurIPS este año incluyen dos artículos relacionados con aprendizaje federado (FLORIDA).
Los investigadores que trabajan en FL a menudo realizan experimentos de simulación para iterar rápidamente nuevas ideas. Los investigadores de Apple presentarán pfl-research: Marco de simulación para acelerar la investigación en el aprendizaje federado privado, un marco de Python rápido, modular y fácil de usar para simular FL que permitirá a la comunidad de investigación avanzar más en este tema.
Los investigadores de Apple también presentarán la Estimación de frecuencia privada y personalizada en un entorno federado, que describe un nuevo enfoque que utiliza el aprendizaje federado privado para calcular de forma privada histogramas de frecuencia personalizados. Las frecuencias personalizadas de palabras (o tokens) son útiles para la predicción de la siguiente palabra al ingresar el teclado en los dispositivos de los usuarios. Esto es un desafío porque la mayoría de los usuarios tienen pocos datos de uso y los diversos vocabularios, temas y estilos de los usuarios conducen a distribuciones de datos variadas. El artículo presenta una nueva técnica que descubre y aprovecha subpoblaciones similares de usuarios, y se demuestra que el enfoque supera a los algoritmos existentes basados en agrupaciones.
Hacer que los modelos multimodales sean más capaces
Los modelos multimodales y multitarea se han vuelto cada vez más poderosos, pero su efectividad puede verse obstaculizada por limitaciones en sus datos de entrenamiento. En NeurIPS, los investigadores de Apple ML presentarán métodos novedosos para superar esas limitaciones y mejorar el rendimiento de estos modelos.
Se ha demostrado que los grandes modelos de visión y lenguaje previamente entrenados, como CLIP, se generalizan bien, pero aún pueden tener dificultades con tareas como la clasificación detallada (por ejemplo, identificar modelos de automóviles) para las cuales los conceptos visuales estaban subrepresentados en sus datos previos al entrenamiento. . En NeurIPS, los investigadores de Apple ML presentarán indicaciones de lenguaje natural agregadas y adaptadas para la generalización posterior de CLIP, que muestra un nuevo método para aprender rápidamente a ajustar CLIP cuando hay datos de anotación limitados disponibles. Con la incrustación de indicaciones agregadas y adaptadas (AAPE), el conocimiento textual se extrae de indicaciones en lenguaje natural (generadas por humanos o LLM) para enriquecer conceptos poco representados en los datos de entrenamiento del modelo. Este enfoque mejora la generalización posterior de CLIP, logrando un sólido rendimiento en diversas tareas de lenguaje visual, incluida la recuperación de imagen a texto, clasificación de pocas tomas, subtítulos de imágenes y VQA.
Si bien los modelos básicos multimodales y multitarea como 4M muestran resultados prometedores, su capacidad para aceptar diversos insumos y realizar diversas tareas está limitada por las modalidades y tareas en las que han sido capacitados. En NeurIPS, los investigadores de Apple ML y nuestros colaboradores de EPFL presentarán 4M-21: un modelo de visión cualquiera para decenas de tareas y modalidades, que muestra cómo ampliar significativamente las capacidades de 4M entrenándolo en decenas de diversas modalidades y realizando capacitación conjunta en conjuntos de datos multimodales a gran escala y corpus de texto (ver Figura 1). Los modelos resultantes se amplían hasta 3 mil millones de parámetros y muestran un sólido rendimiento de visión listo para usar, generación orientable y condicional, recuperación intermodal y capacidades de fusión multisensorial.
Mejora de la formación previa en LLM
Los LLM se utilizan en una variedad de aplicaciones de producción, incluidos algunos servicios de Apple, y las mejoras fundamentales de estos modelos podrían tener un impacto significativo para los desarrolladores y sus usuarios en toda la industria. En NeurIPS, el trabajo que presentarán los investigadores de Apple ML incluye una nueva técnica para una formación previa de LLM más eficiente.
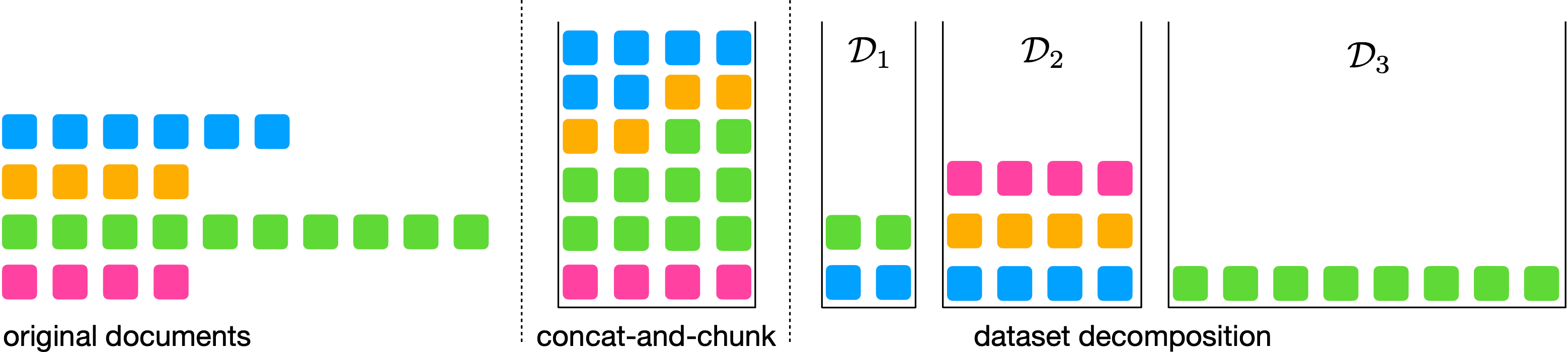
Los LLM comúnmente se entrenan con conjuntos de datos de secuencias de tokens de longitud fija, porque su infraestructura de capacitación a menudo admite solo una longitud de secuencia limitada. Para crearlos, se combinan documentos de varias longitudes y luego se dividen en partes de la longitud especificada. Debido a que los documentos se combinan aleatoriamente en este enfoque, el modelo puede usar el contexto de un documento no relacionado para predecir el siguiente token, en lugar de usar el contexto del documento relevante. Más allá de ser una mala señal de aprendizaje, esto también consume cálculos innecesarios. Los investigadores de Apple presentarán Dataset Decomposition: Pretrain LLMs with Variable Sequence Longitudes, que aborda este problema con un método novedoso en el que un conjunto de datos que contiene documentos de varias longitudes se descompone en una unión de “depósitos” o subconjuntos, con secuencias de la misma longitud. Luego, en el momento del entrenamiento, se utilizan la longitud de secuencia variable y los tamaños de lote, muestreados simultáneamente de todos los depósitos. (ver Figura 2). Esto permite un entrenamiento previo eficiente en secuencias largas, se escala de manera efectiva con el tamaño del conjunto de datos y se ha demostrado que mejora significativamente el rendimiento del modelo en evaluaciones estándar.
Explorando la capacidad de razonar de los LLM
Los LLM han demostrado ser capaces en muchas tareas, pero hasta qué punto los modelos actuales pueden razonar sigue siendo una importante pregunta de investigación abierta. Comprender las capacidades y limitaciones actuales de estos modelos no solo permite a la comunidad de investigación continuar mejorándolos, sino que también ayuda a los desarrolladores a aprovechar de manera más inteligente los LLM en sus aplicaciones de producción.
En NeurIPS, investigadores de Apple presentarán ¿Hasta dónde pueden razonar los transformadores? The Globality Barrier and Inductive Scratchpad, un artículo que investiga por qué los modelos basados en transformadores luchan con tareas que requieren “razonamiento global”, donde se requiere combinar conceptos aprendidos y extrapolación. El trabajo muestra que estos modelos son incapaces de componer largas cadenas de silogismos (por ejemplo, inferir a⇒c de a⇒b y b⇒c), porque no pueden aprender eficientemente distribuciones con alta globalidad, y el artículo introduce la idea de un “modelo inductivo”. scratchpad” que puede permitir a los transformadores superar estas limitaciones.
Comprender el aprendizaje autosupervisado (SSL)
Aprender representaciones de forma eficaz y eficiente es un objetivo fundamental del aprendizaje profundo, ya que estas representaciones se pueden utilizar para muchas tareas posteriores. Al mejorar la comprensión en el campo de cómo los diferentes enfoques aprenden representaciones, la investigación en esta área podría, en última instancia, conducir a un mejor rendimiento en esas tareas posteriores.
En NeurIPS, los investigadores de Apple presentarán Cómo JEPA evita características ruidosas: el sesgo implícito de las redes de autodestilación lineal profundaque explora las diferencias en cómo se aprenden las representaciones con dos paradigmas SSL líderes: Masked Auto Encoders (MAE) y Joint Embedding Predictive Architectures (JEPA). El trabajo muestra que en un entorno lineal simplificado donde ambos enfoques aprenden representaciones similares, las JEPA están predispuestas a aprender características de “alta influencia” (es decir, características caracterizadas por tener altos coeficientes de regresión), proporcionando una explicación formal para un fenómeno observado empíricamente en el campo, que JEPA parece priorizar las características abstractas sobre la información detallada de píxeles.
Demostración de la investigación de ML en el stand de Apple
Durante el horario de exposición, los asistentes a NeurIPS podrán interactuar con demostraciones en vivo de la investigación de Apple ML en el stand 323, West Hall A, que incluye:
- mlx – un marco de matriz de código abierto diseñado para Apple Silicon que permite el aprendizaje automático y la informática científica de forma rápida y flexible en el hardware de Apple. El marco está optimizado para la arquitectura de memoria unificada de Apple Silicon y aprovecha tanto la CPU como la GPU. En NeurIPS, la demostración de MLX mostrará la inferencia de modelos grandes y el entrenamiento en dispositivos que utilizan MLX; específicamente, ajuste fino de un LLM de parámetro 7B en un iPhone, generación de imágenes usando un modelo de gran difusión en un iPad y generación de texto usando varios modelos de lenguaje grande en una Mac con silicio de Apple.
- MobileClip: una familia de modelos de imagen y texto aptos para dispositivos móviles con arquitecturas híbridas CNN/Transformer. En combinación, estos modelos logran la mejor compensación entre precisión y latencia. MobileCLIP-B obtiene resultados de última generación en clasificación y recuperación de disparo cero, así como comprensión de relaciones, atributos e información de pedidos. En NeurIPS, los visitantes podrán experimentar cómo MobileCLIP realiza la clasificación de escenas de disparo cero en tiempo real en un iPhone.
Apoyando a la comunidad de investigación de ML
Apple se compromete a apoyar a los grupos subrepresentados en la comunidad de ML y estamos orgullosos de patrocinar nuevamente varios grupos de afinidad que organizan eventos en NeurIPS 2024, incluidos <a target="_blank" href="https://www.blackinai.org" target="_blank" aria-label="Black in ai – Opens in a new window” class=”icon icon-after icon-external” rel=”noopener nofollow”>Negro en IA (<a target="_blank" href="https://www.blackinai.org/event/black-in-ai-2024″ target=”_blank” aria-label=”workshop – Opens in a new window” class=”icon icon-after icon-external” rel=”noopener nofollow”>taller el 10 de diciembre), Mujeres en el aprendizaje automático (WiML) (taller el 10 de diciembre), <a target="_blank" href="https://www.latinxinai.org" target="_blank" aria-label="LatinX in ai – Opens in a new window” class=”icon icon-after icon-external” rel=”noopener nofollow”>LatinX en IA (taller el 10 de diciembre), y <a target="_blank" href="https://www.queerinai.com" target="_blank" aria-label="Queer in ai – Opens in a new window” class=”icon icon-after icon-external” rel=”noopener nofollow”>Queer en IA (taller el 11 de diciembre, social el 12 de diciembre). Además de apoyar estos talleres con patrocinio, los empleados de Apple también participarán en cada uno de ellos y en otros.
Obtenga más información sobre la investigación de Apple ML en NeurIPS 2024
NeurIPS es la conferencia anual de investigación de ML más grande y una de las más importantes, y Apple se enorgullece de compartir una vez más nuevas investigaciones innovadoras en el evento y conectarse con la comunidad que asiste. La publicación anterior destaca solo algunos de los trabajos que los investigadores de Apple ML presentarán en NeurIPS 2024, y aquí puede encontrar una descripción general completa y el calendario de nuestra participación.





{kind=link}